集群容量规划案例研究 – 仲裁队列(第一部分)
在本系列的第一篇文章 中,我们介绍了工作负载、测试以及 AWS EC2 上的集群和存储卷配置。在本篇文章中,我们将进行仲裁队列的容量分析。我们还进行了 镜像队列的容量分析。
在本文中,我们将运行递增强度测试,以在理想条件下测量候选集群大小在不同发布速率下的表现。在下一篇文章中,我们将运行弹性测试,以测量我们的集群在不利条件下能否处理目标峰值负载。
所有仲裁队列都声明有以下属性
- x-quorum-initial-group-size=3 (复制因子)
- x-max-in-memory-length=0
x-max-in-memory-length 属性强制仲裁队列在安全时尽快将消息体从内存中移除。您可以将其设置为更长的限制,这是最激进的设置——旨在避免内存大幅增长,但代价是在消费者跟不上时增加磁盘读取次数。没有此属性,消息体将始终保留在内存中,这可能导致内存增长到触发内存警报,严重影响发布速率——这是我们在本次工作负载案例研究中希望避免的。
理想条件 - 强度递增测试
在之前的文章中,我们讨论了运行基准测试的选项。您可以使用以下命令以这些强度运行此工作负载:
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-c 1000 \
-ct -1 \
-ad false \
--rate 50 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
-qa auto-delete=false,durable=false,x-queue-type=quorum \
--producers 200 \
--consumers 200 \
--consumer-latency 10000 \
--producer-random-start-delay 30
只需将 --rate 参数更改为您在每个测试中需要的速率,并请记住,这是每发布者的速率,而不是总速率。由于消费者处理时间(消费者延迟)设置为 10 毫秒,因此我们也需要增加发布者数量以应对更高的发布速率。
请注意,我们将 durable 设置为 false,因为此属性与 quorum queues 无关。
io1 - 高性能 SSD
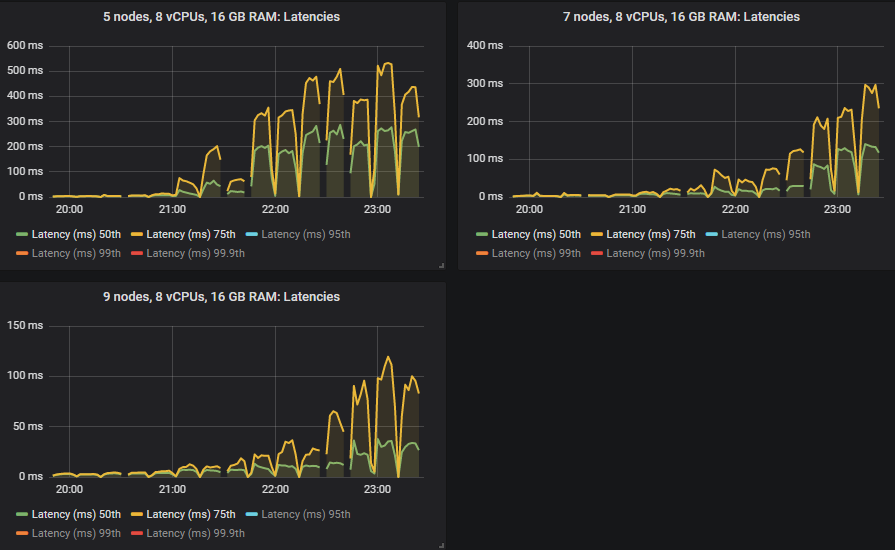
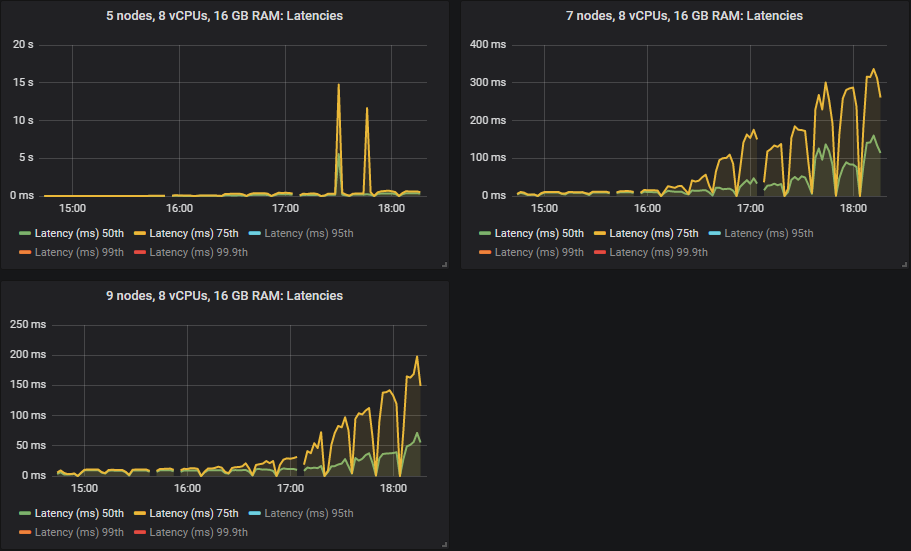
在 quorum queues 达到极限的强度下,它们倾向于积累消息积压,导致 95% 分位数及以上的端到端延迟增加。以下是 50% 和 75% 分位数的延迟。
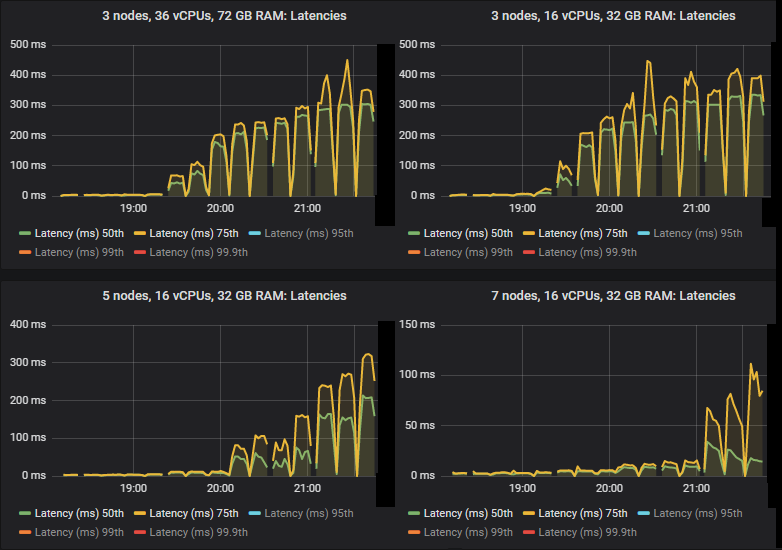
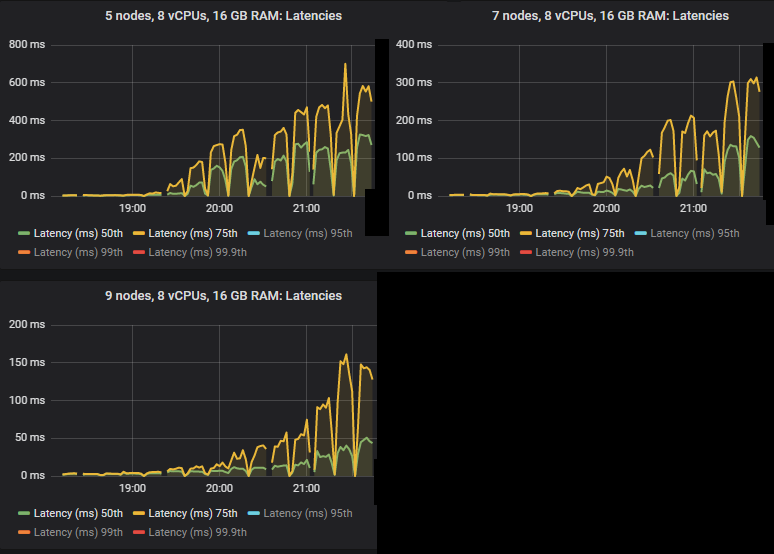
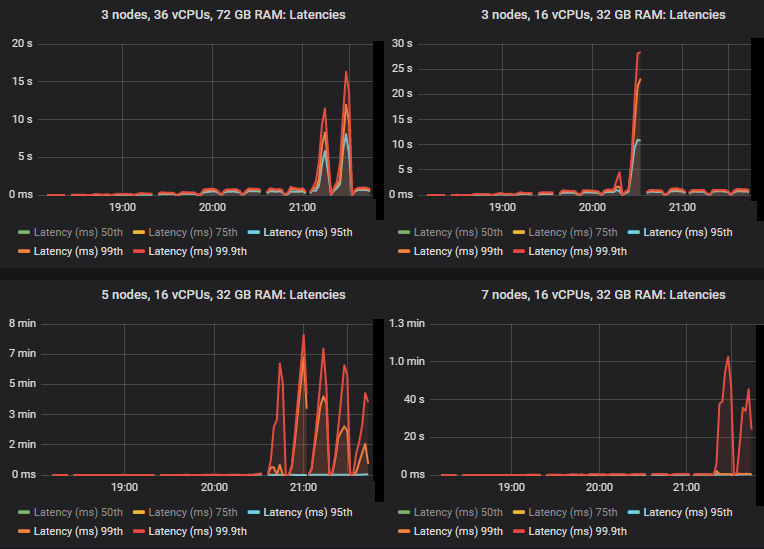
我们看到,在某些情况下,当 quorum queues 达到吞吐量容量时,延迟会急剧升高。
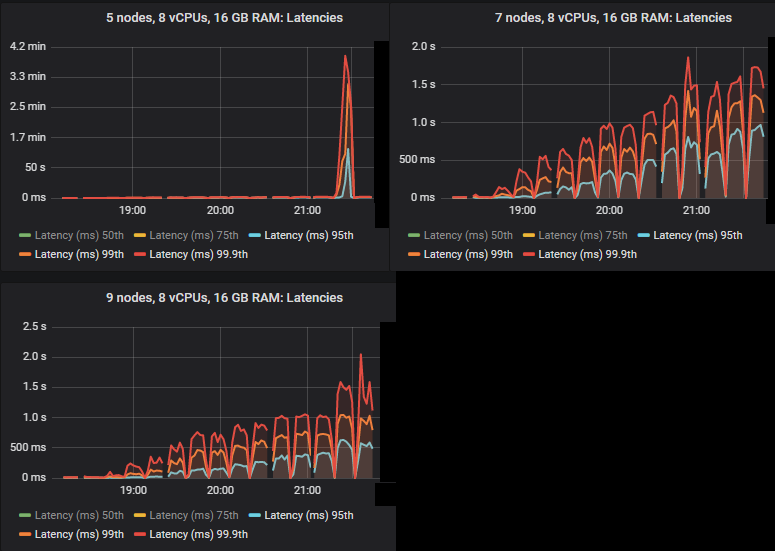
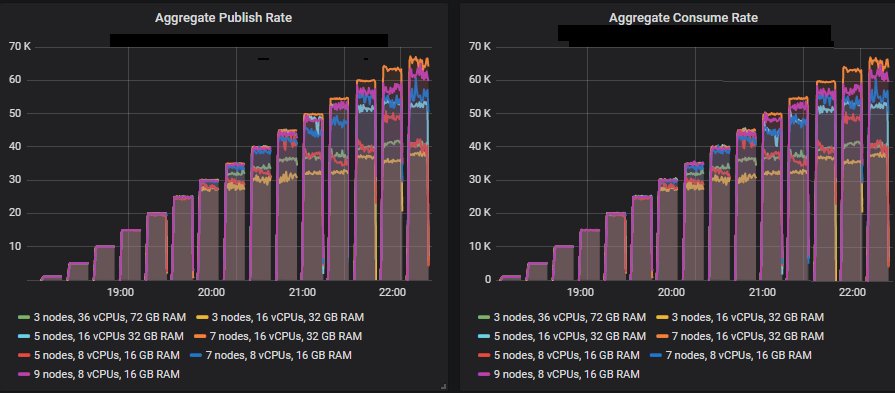
除 3x16 和 5x8 集群外,所有集群都达到了 30k 消息/秒的目标峰值,并且端到端延迟均低于 1 秒的要求。正如预期的那样,较大的集群实现了最高的吞吐量。
吞吐量最低的集群 (3x16) 服务器指标
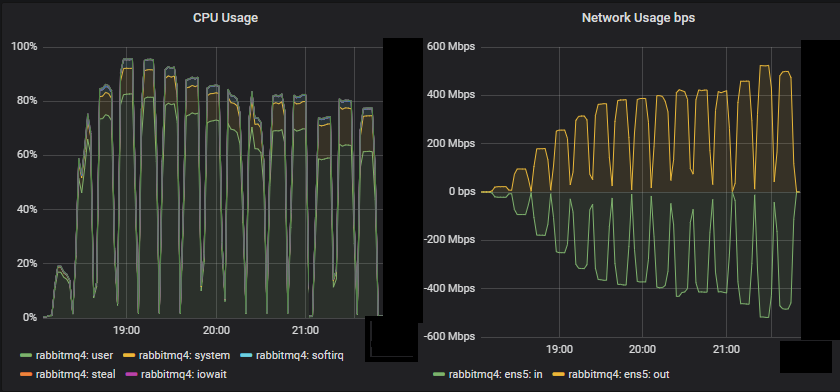
我们看到,对于这个小型集群,CPU 似乎是资源瓶颈。
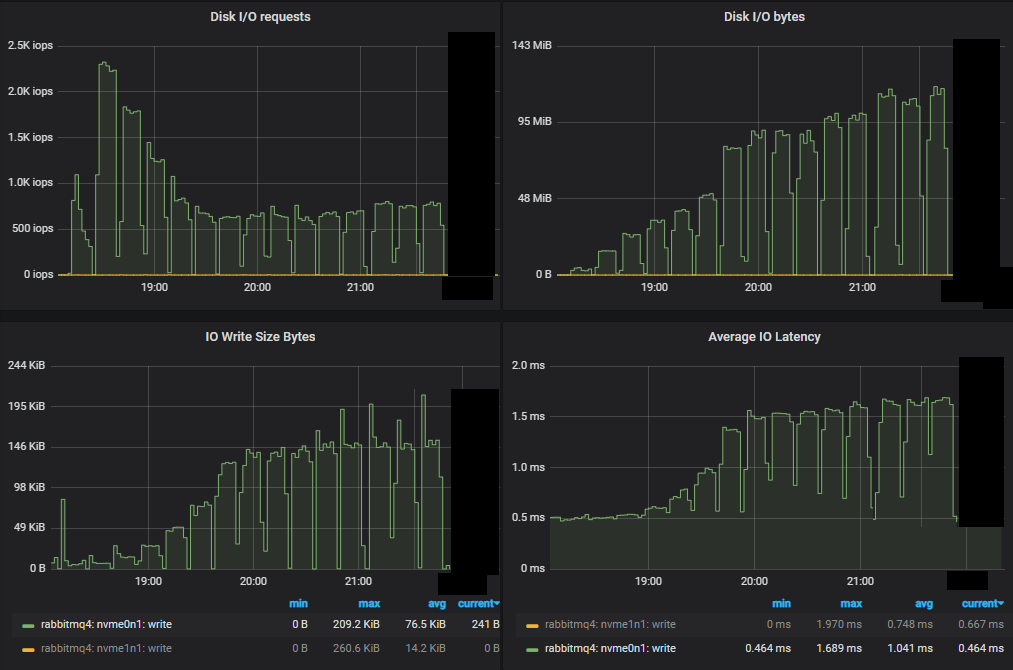
首先,与镜像队列相比,我们看到 IOPs 的数量大大减少。随着我们通过递增的强度进行,IOPs 实际上有所下降,每次写入操作都变得越来越大。
吞吐量最高的集群服务器指标
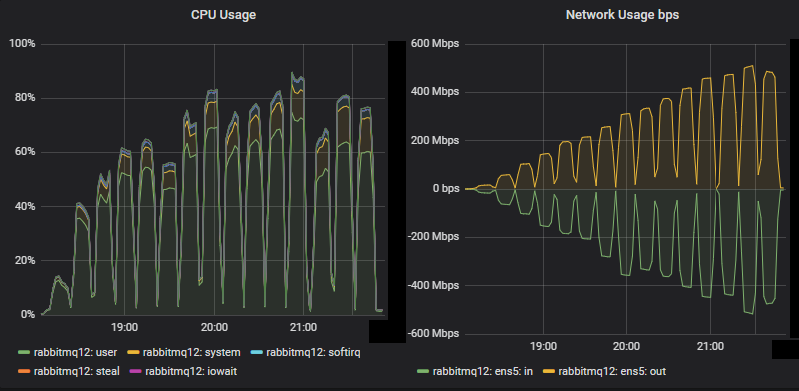
对于这个大型集群,CPU 未达到饱和。网络带宽达到了 500 Mbps,低于镜像队列的相同测试(达到 750 Mbps)(尽管镜像队列的复制因子较低)。在之前的博文中讨论了镜像队列的网络使用效率低下。
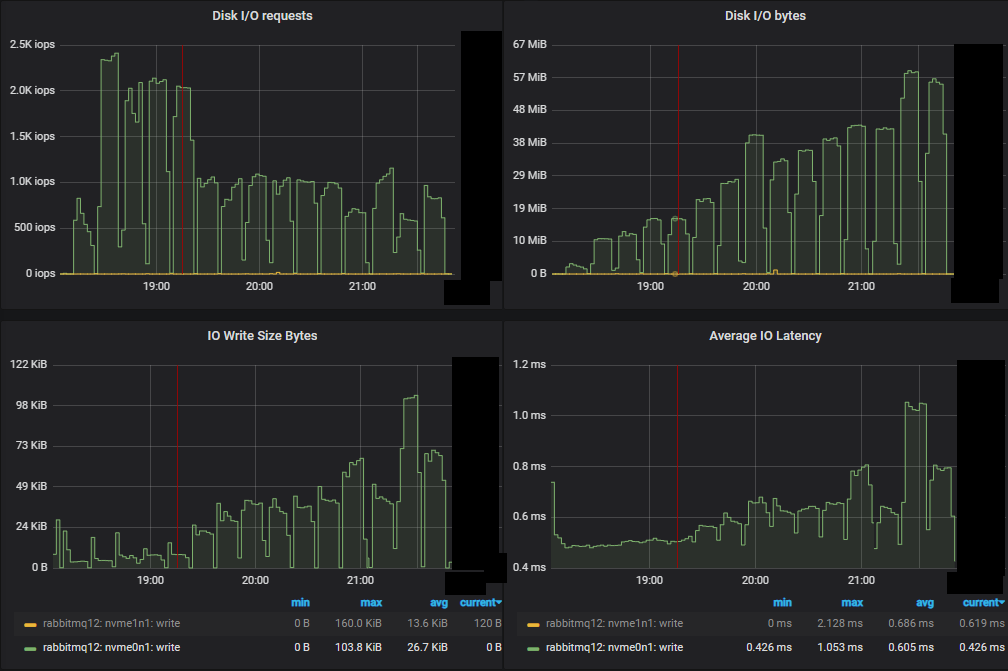
与镜像队列测试一样,性能最差的集群不仅吞吐量较低,而且磁盘 IO 也更高。这是因为 quorum queues 的写入磁盘方式。每条消息始终写入 Write-Ahead Log (WAL)。为了控制 WAL 的大小,WAL 文件会被截断,这会涉及将其消息写入段文件。有一种优化,即如果消息在写入段文件之前被消耗并确认,则不会执行第二次磁盘写入 - 就 RabbitMQ 而言,该消息已不再存在。这意味着如果消费者能够跟上,消息只会写入磁盘一次,但如果消费者落后,消息最多可能写入磁盘两次。
吞吐量最高的集群没有遇到资源瓶颈,这表明限制因素是协调成本(基于 Raft 的复制)。
吞吐量最低的集群过早地达到了 90% 以上的 CPU 利用率,这与它停止达到目标吞吐量的时刻相对应。它在第四次测试中达到了 > 90%,从第五次测试开始,它就无法稳定匹配目标。
因此,quorum queues 将比最多写入磁盘一次的镜像队列使用更多的磁盘带宽。
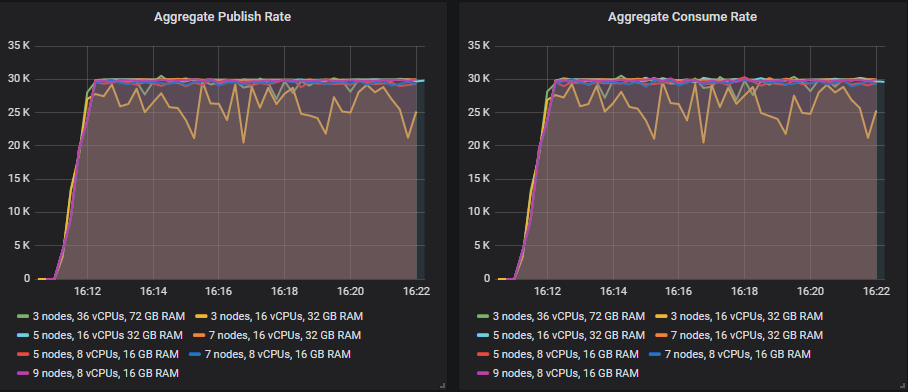
每个集群如何应对 30k 消息/秒的目标速率。
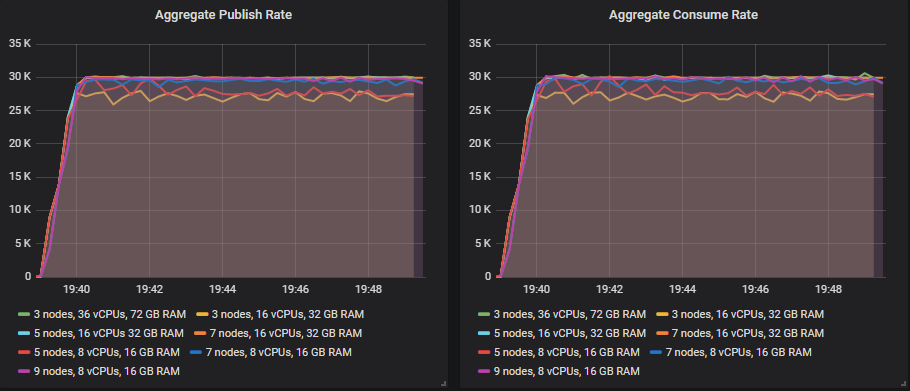
匹配目标吞吐量的排行榜
从 35k 消息/秒开始,随着目标吞吐量的增加,许多集群的大小继续显示出吞吐量的增加,但总是略低于目标。
能够远远超出 30k 消息/秒目标的集群大小是
- 集群:7 节点,16 vCPU(c5.4xlarge)- 60k 消息/秒
其余集群在从 35k 消息/秒开始的每次测试中都未能达到目标,但随着测试的进行,吞吐量仍然更高。这是按最高吞吐量排名的排行榜
- 集群:7 节点,16 vCPU(c5.4xlarge)。速率:65k 消息/秒
- 集群:9 节点,8 vCPU(c5.2xlarge)。速率:63k 消息/秒
- 集群:7 节点,8 vCPU(c5.2xlarge)。速率:54k 消息/秒
- 集群:5 节点,16 vCPU(c5.4xlarge)。速率:53k 消息/秒
- 集群:5 节点,8 vCPU(c5.2xlarge)。速率:50k 消息/秒
- 集群:3 节点,36 vCPU(c5.9xlarge)。速率:40k 消息/秒
- 集群:3 节点,16 vCPU(c5.4xlarge)。速率:37k 消息/秒
横向扩展和中间的纵向扩展/横向扩展(up/out)显示了最佳结果。
按最高吞吐量计算的每千条消息/月的成本排行榜
- 集群:5 节点,8 vCPU(c5.2xlarge)。成本:97 美元(50k)
- 集群:3 节点,16 vCPU(c5.4xlarge)。成本:98 美元(37k)
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:115 美元(53k)
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:126 美元(54k)
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:137 美元(40k)
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:139 美元(63k)
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:142 美元(65k)
按 30k 消息/秒目标计算的每千条消息/月的成本排行榜
我们看到有两个集群未能达到 30k 消息/秒的目标。达到目标的集群排行榜
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:135 美元
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:151 美元
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:183 美元
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:194 美元
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:204 美元
在此测试中,成本效益与性能背道而驰。当存储卷是最昂贵的项目时,横向扩展成本很高。最佳价值来自纵向/横向扩展的中间地带。
我们真的需要那些昂贵的 io1 SSD 吗?此测试中的 IOPs 相对较低,我们也没有超过 250MiB/s,因此便宜的 gp2 卷应该是不错的选择。让我们看看。
gp2 - 通用 SSD
与之前一样,50% 和 75% 的分位数保持相当低。
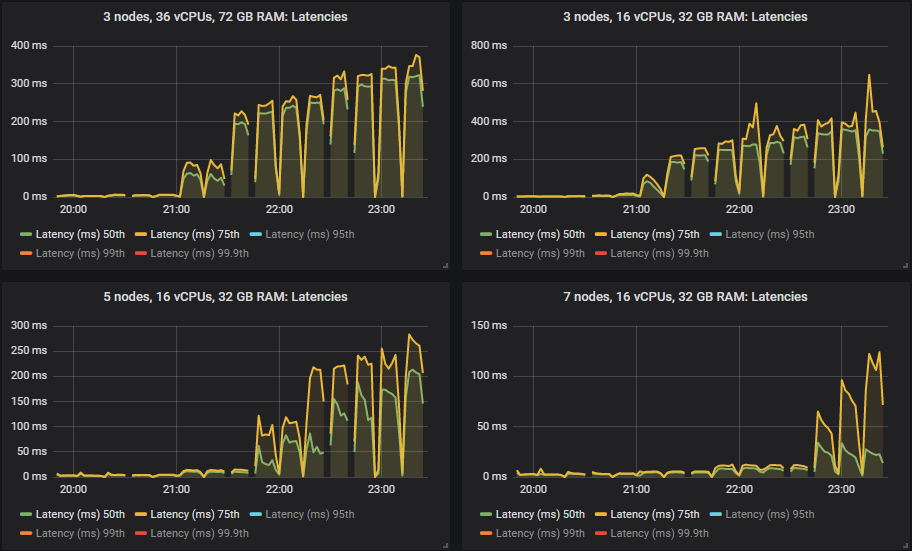
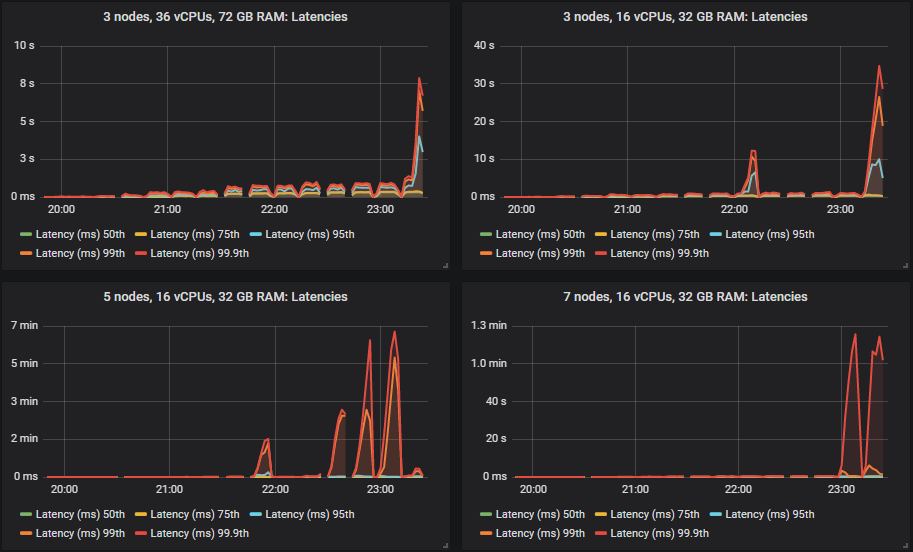
但是,当集群达到其吞吐量容量时,95%、99% 和 99.9% 的分位数在某些情况下会急剧上升。这种延迟基本上意味着队列开始积累消息。这些积压仅发生在较大的 16 vCPU 集群上。
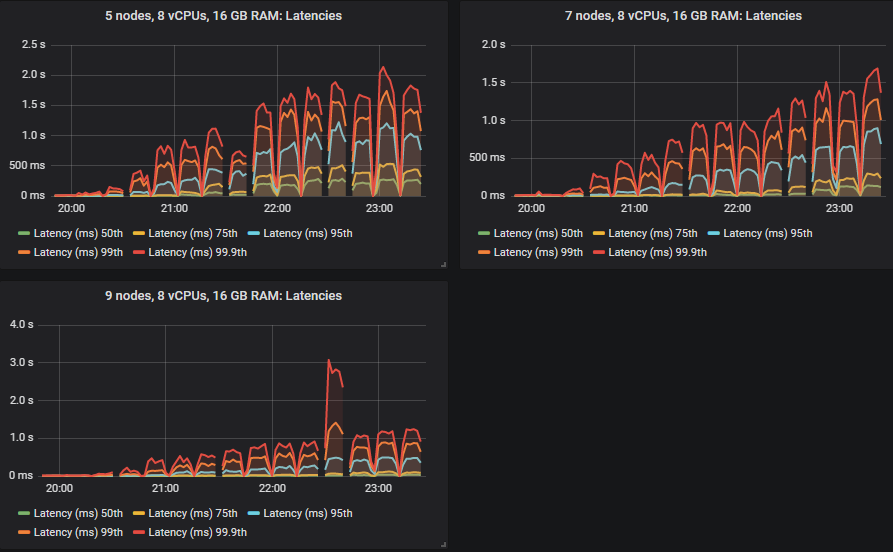
gp2 卷的结果并不比更昂贵的 io1 卷差。
吞吐量最低的集群 (3x16) 磁盘指标
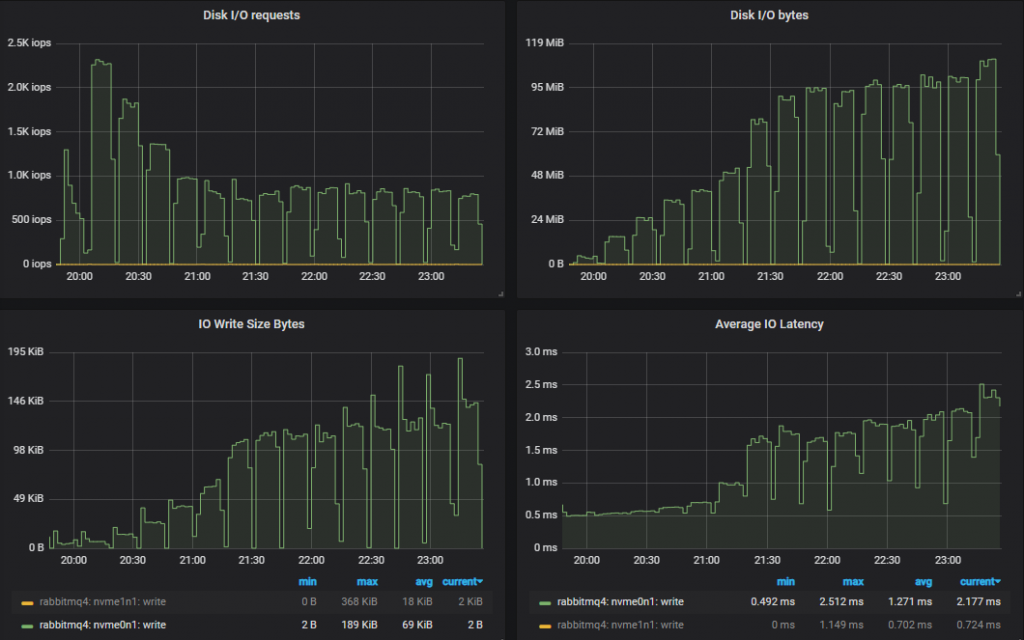
吞吐量最高的集群 (7x16) 磁盘指标。
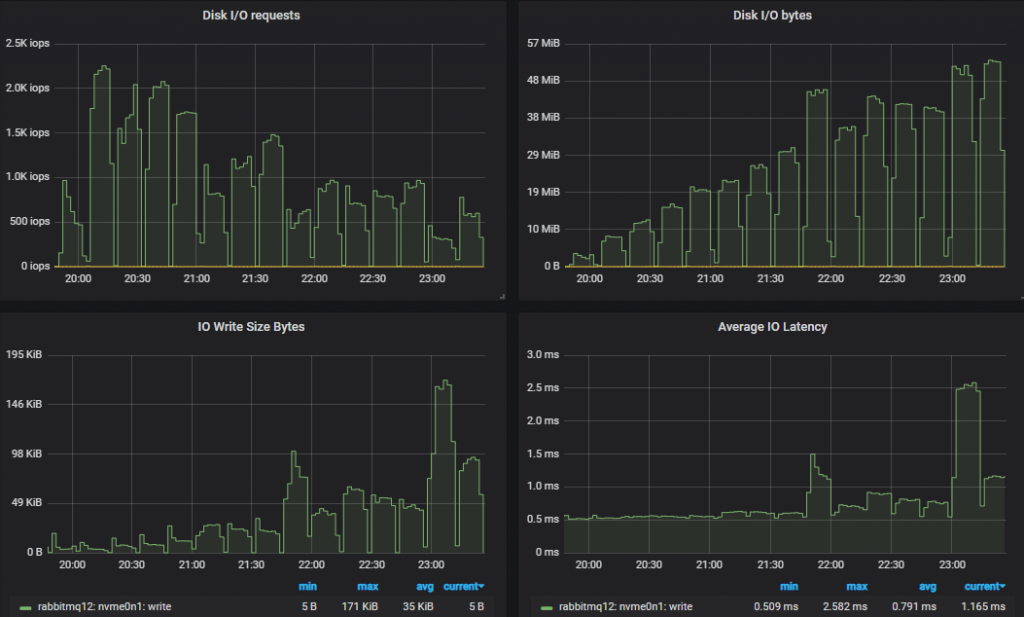
在这两种情况下,IOPs 开始时较高,相对接近 3000 IOPs 的限制(达到 2.3k),但随着负载的增加,IO 大小变得越来越大,操作数量也减少了。
对于 30k 消息/秒和 1kb 消息的目标,即使我们将每条消息写入两次,我们仍然不会达到 gp2 的 250MiB/s 限制。与之前一样,较小的集群看到了更多的磁盘 IO,因为它们执行了比较大的、性能更高的集群更多的双重写入。
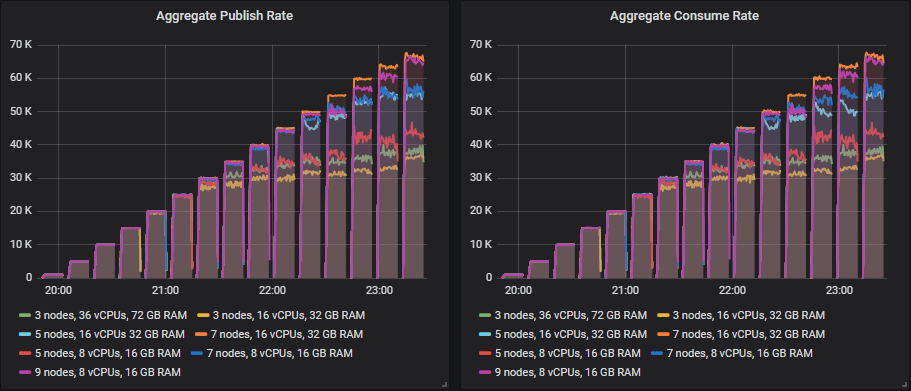
这就是 30k 消息/秒的目标结果。
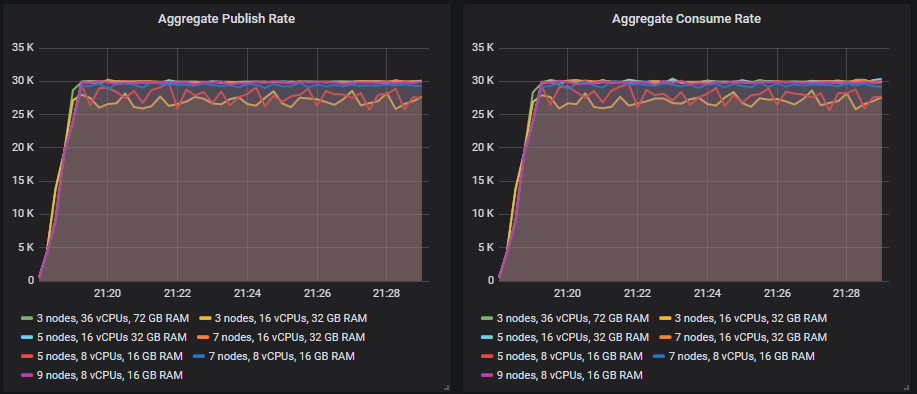
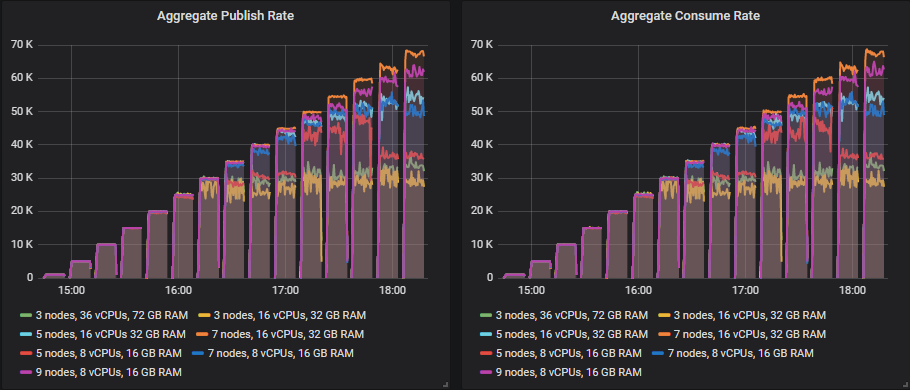
匹配目标吞吐量的排行榜
从 35k 消息/秒开始,许多集群的大小随着目标吞吐量的增加继续显示出吞吐量的增加,但总是略低于目标。
能够远远超出该目标的集群大小是
- 集群:7 节点,c5.4xlarge - 60k 消息/秒
在 35k 消息/秒以上的测试中,其余集群未能达到目标,有的只差一点,有的则差了一些,但随着测试的进行,吞吐量仍然更高。这是按最高吞吐量排名的排行榜
- 集群:7 节点,16 vCPU(c5.4xlarge)。速率:67k 消息/秒
- 集群:9 节点,8 vCPU(c5.2xlarge)。速率:66k 消息/秒
- 集群:5 节点,16 vCPU(c5.4xlarge)。速率:54k 消息/秒
- 集群:7 节点,8 vCPU(c5.2xlarge)。速率:54k 消息/秒
- 集群:5 节点,8 vCPU(c5.2xlarge)。速率:42k 消息/秒
- 集群:3 节点,36 vCPU(c5.9xlarge)。速率:37k 消息/秒
- 集群:3 节点,16 vCPU(c5.4xlarge)。速率:36k 消息/秒
横向扩展和中间的纵向扩展/横向扩展(up/out)显示了最佳结果。
按最高吞吐量计算的每千条消息/月的成本排行榜
- 集群:5 节点,8 vCPU(c5.2xlarge)。成本:41 美元(42k)
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:45 美元(54k)
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:47 美元(66k)
- 集群:3 节点,16 vCPU(c5.4xlarge)。成本:49 美元(36k)
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:55 美元(54k)
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:72 美元(67k)
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:97 美元(37k)
按 30k 消息/秒目标计算的每千条消息/月的成本排行榜
达到 30k 消息/秒目标的集群
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:54 美元
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:69 美元
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:98 美元
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:107 美元
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:120 美元
在此测试中,成本效益与性能更加一致。廉价的存储卷使得小型横向扩展 VM 具有出色的投资回报率。对于此工作负载,io1 根本不值得。
在之前的文章中,我们推荐使用 SSD 和 quorum queues。我们展示了 quorum queues 在纯 quorum queue 工作负载的 HDD 上运行得很好。但当您运行经典队列和 quorum queues 的混合工作负载时,我们发现 HDD 无法提供 quorum queues 所需的性能。鉴于这是一项纯粹的 quorum 工作负载,让我们看看它们在 HDD 上的表现。
st1 - HDD
Quorum queues 在 HDD 上运行良好,尽管一旦集群达到其吞吐量容量,吞吐量就变得更加零碎。除了 7x16 集群(在这些测试中通常位居榜首)之外,所有集群的吞吐量也略低。我们通常建议使用 SSD,因为由于经典队列的随机 IO 特性,混合经典/quorum 队列工作负载的性能可能会显着下降。但此测试表明,对于纯 quorum queue 工作负载,HDD 可以表现良好。
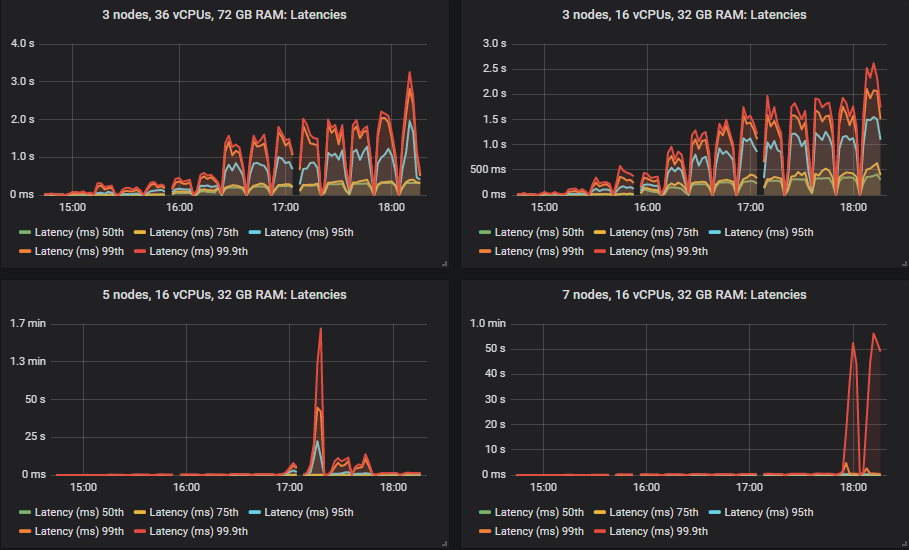
50% 和 75% 分位数的延迟高于 SSD,但均低于一秒,除了 5x8 集群,该集群在高强度下出现了消息积压。
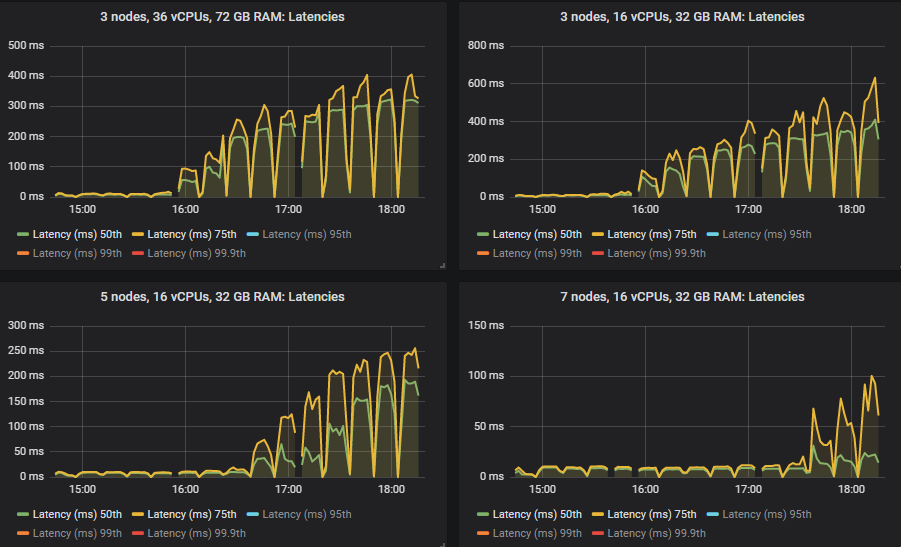
与 SSD 一样,在某些情况下,当集群达到其吞吐量容量时,延迟会急剧上升(这意味着出现小型消息积压)。
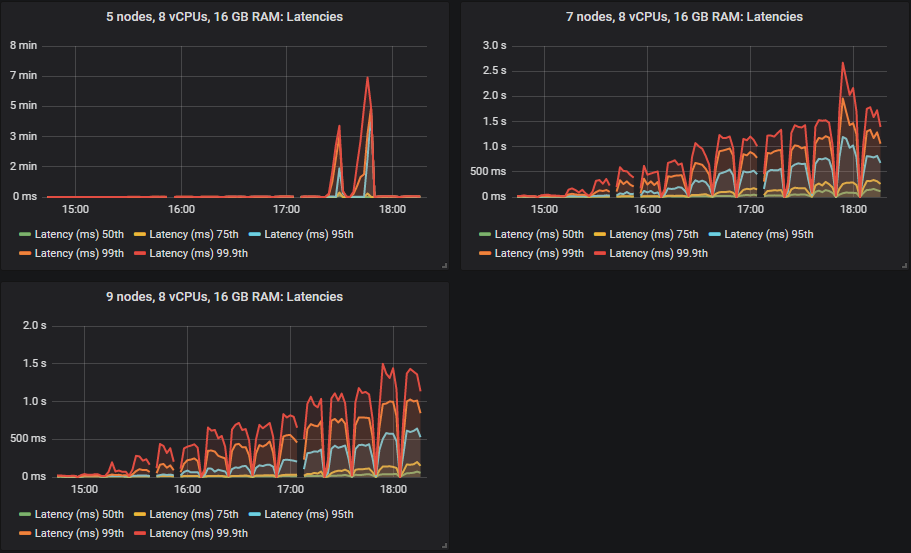
重要的是,在 30k 消息/秒的目标速率下,所有延迟都低于一秒。
查看磁盘指标,正如 HDD 所预期的那样,IOPs 通常再次较低,并且相应的写入大小也很大。
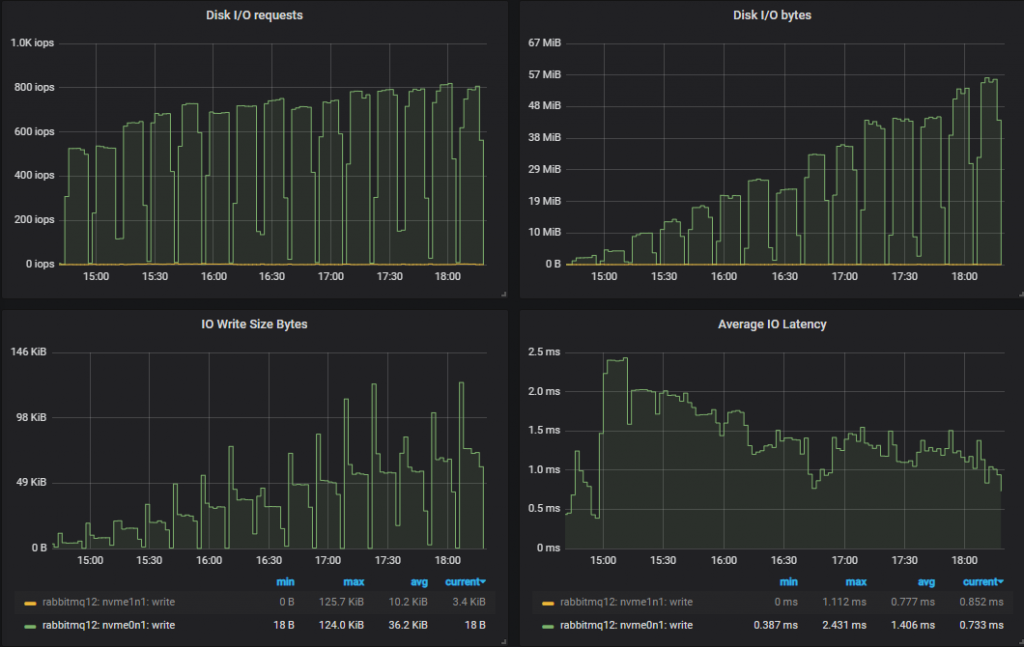
这就是 30k 消息/秒的目标结果。
这次我们可以争辩说 5x8 集群达到了 30k 消息/秒的目标,而它在 SSD 上时未能达到。
从 35k 消息/秒开始,许多集群的大小随着目标吞吐量的增加继续显示出吞吐量的增加,但总是略低于目标。
能够超出该目标的大型集群是
- 集群:7 节点,16 vCPU(c5.4xlarge)。速率:60k 消息/秒
- 集群:9 节点,8 vCPU(c5.2xlarge)。速率:40k 消息/秒
其余集群在 35k 消息/秒以上的每次测试中都未能达到目标,但随着测试的进行,吞吐量仍然更高。这是按最高吞吐量排名的排行榜
- 集群:7 节点,16 vCPU(c5.4xlarge)。速率:67k 消息/秒
- 集群:9 节点,8 vCPU(c5.2xlarge)。速率:62k 消息/秒
- 集群:5 节点,16 vCPU(c5.4xlarge)。速率:54k 消息/秒
- 集群:7 节点,8 vCPU(c5.2xlarge)。速率:50k 消息/秒
- 集群:5 节点,8 vCPU(c5.2xlarge)。速率:37k 消息/秒
- 集群:3 节点,36 vCPU(c5.9xlarge)。速率:32k 消息/秒
- 集群:3 节点,16 vCPU(c5.4xlarge)。速率:27k 消息/秒
横向扩展和中间的纵向扩展/横向扩展(up/out)显示了最佳结果。
按最高吞吐量计算的每千条消息/月的成本排行榜
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:74 美元(54k)
- 集群:5 节点,8 vCPU(c5.2xlarge)。成本:76 美元(37k)
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:78 美元(50k)
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:81 美元(62k)
- 集群:3 节点,16 vCPU(c5.4xlarge)。成本:89 美元(27k)
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:94 美元(67k)
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:132 美元(32k)
按 30k 消息/秒目标计算的每千条消息/月的成本排行榜
- 集群:5 节点,8 vCPU(c5.2xlarge)。成本:93 美元
- 集群:7 节点,8 vCPU(c5.2xlarge)。成本:131 美元
- 集群:5 节点,16 vCPU(c5.4xlarge)。成本:134 美元
- 集群:3 节点,36 vCPU(c5.9xlarge)。成本:142 美元
- 集群:9 节点,8 vCPU(c5.2xlarge)。成本:168 美元
- 集群:7 节点,16 vCPU(c5.4xlarge)。成本:211 美元
在此情况下,成本效益与性能并非背道而驰(不像 io1),但它们也没有一致(像 gp2)。横向扩展在性能方面是最佳的,但更昂贵的卷意味着横向扩展也不是最具成本效益的。中间地带和横向/纵向扩展是最佳的。
端到端延迟和三种卷类型
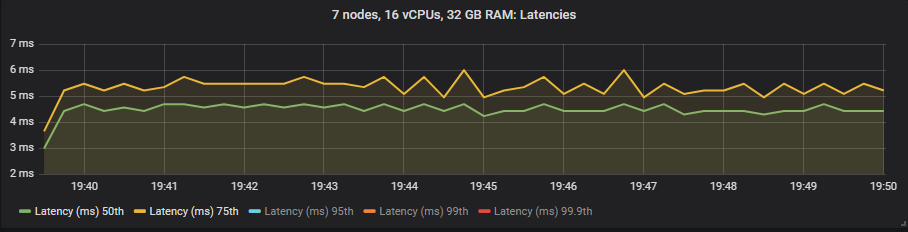
在这些测试中,我们将端到端延迟视为消息发布和消耗之间的时间。如果我们查看 30k 消息/秒的目标速率和 7x16 集群类型,我们会看到
io1 SSD
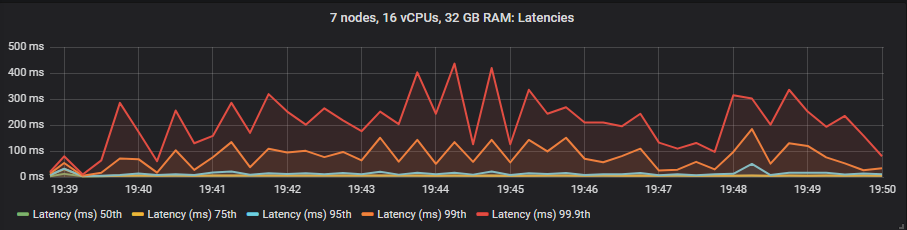
gp2 SSD
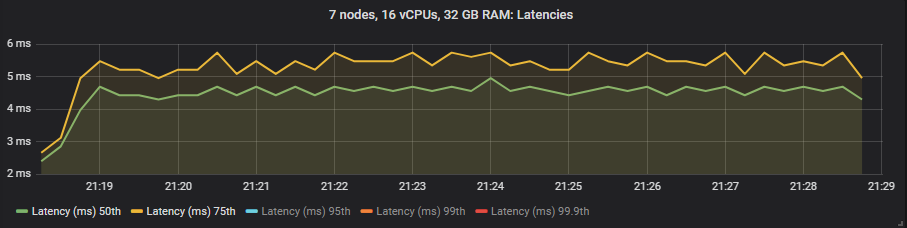
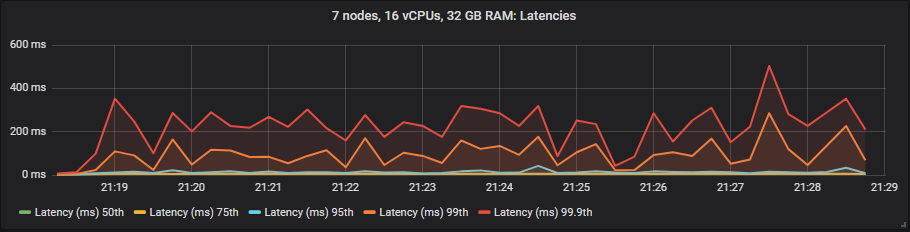
st1 HDD
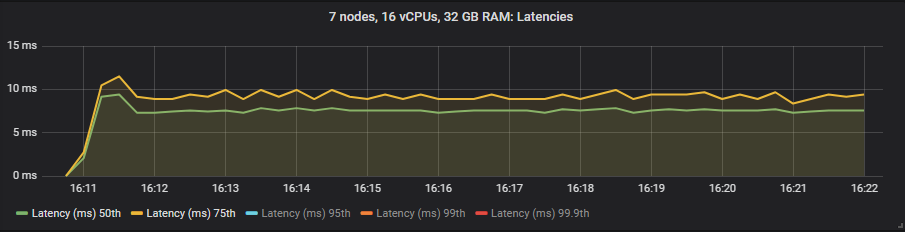
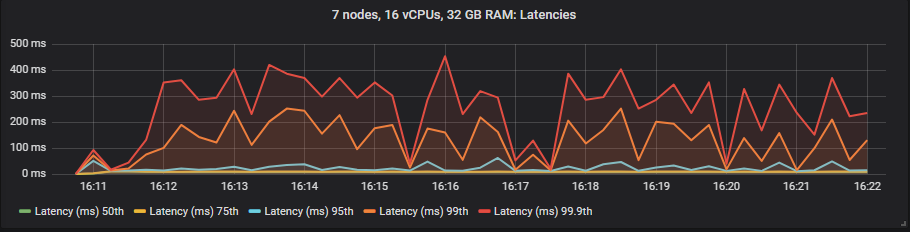
与镜像队列不同,我们没有看到使用昂贵的 io1 卷相比 gp2 在延迟方面有任何好处。正如预期的那样,HDD 显示出比 SSD 更高的端到端延迟。
强度递增基准测试 - 结论
到目前为止的结论是:
- 昂贵的 io1 卷根本不值得。它的性能与 gp2 一样好。但是,如果我们有更大的工作负载或更大的消息,我们可能需要一个能够处理 250MiB/s 以上的卷,在那些情况下我们可能会选择 io1,但不是在高 IOPS 的情况下。使用 io1,您按 GB 支付卷的费用,也按 IOPs 支付费用。因此,为 3000(或更少)而不是 10000 付费是有意义的。
- 廉价的 gp2 卷提供了性能和成本的最佳组合,是大多数工作负载的最佳选择。请记住,我们使用的是一个 1TB 的大小,它没有突发 IOPS,并且有一个 250 MiBs 的限制(我们从未达到过)。
- 在廉价存储卷的情况下,横向扩展较小的 8 vCPU VM 在成本效益和性能方面都是最佳的。
- 使用昂贵的卷时,选择纵向/横向扩展的中间地带最具成本效益。
- 使用 3 个大型 VM 进行纵向扩展从未是最佳选择。
每 1000 消息/月吞吐量的 Top 5 配置(针对 30k 消息/秒吞吐量)
- 集群:7 个节点,8 个 vCPU (c5.2xlarge),gp2 SSD。成本:54 美元
- 集群:9 个节点,8 个 vCPU (c5.2xlarge),gp2 SSD。成本:69 美元
- 集群:5 个节点,8 个 vCPU (c5.2xlarge),st1 HDD。成本:93 美元
- 集群:5 个节点,16 个 vCPU (c5.4xlarge),gp2 SSD。成本:98 美元
- 集群:7 个节点,16 个 vCPU (c5.4xlarge),gp2 SSD。成本:107 美元
我们只在理想条件下进行了测试……
我们从 21 种不同的集群配置和 15 种不同的工作负载强度收集了大量数据。我们认为到目前为止,我们应该选择使用廉价 gp2 卷的中到大型集群,其中包含小型 VM。但这只是测试队列为空或接近为空的理想情况,此时 RabbitMQ 以其最佳性能运行。接下来,我们将进行更多测试,以确保尽管券商丢失和队列积压,我们选择的集群大小仍能提供我们所需的性能。下一篇我们将测试弹性。