集群容量规划案例研究 – 镜像队列(第二部分)
在 上一篇文章 中,我们开始使用镜像队列对我们的 工作负载 进行容量分析。我们专注于消费者能够跟上、队列没有积压且集群中所有代理程序都正常运行的理想情况。通过运行一系列基准测试,模拟不同强度的我们的工作负载,我们确定了每 1000 条消息/秒每月成本最低的前 5 个集群大小和存储卷组合。
- 集群:5 节点,8 vCPU,gp2 SSD。成本:58 美元
- 集群:7 节点,8 vCPU,gp2 SSD。成本:81 美元
- 集群:5 节点,8 vCPU,st1 HDD。成本:93 美元
- 集群:5 节点,16 vCPU,gp2 SSD。成本:98 美元
- 集群:9 节点,8 vCPU,gp2 SSD。成本:104 美元
还需要进行更多测试,以确保这些集群能够处理代理程序故障和因停机或系统减速而积压大量消息的情况。
恶劣条件 - 应对滚动重启和代理丢失
如果一个代理宕机,我们的 gp2 SSD 集群是否还能处理相同的负载?可能虚拟机或磁盘发生故障,或者您需要执行紧急的操作系统补丁?我们确实需要确保在黑色星期五销售高峰期,即使在发生故障的情况下,我们也能处理流量。
为此,我们再次运行相同的测试,但在每个强度级别进行到一半时强制杀死一个代理。
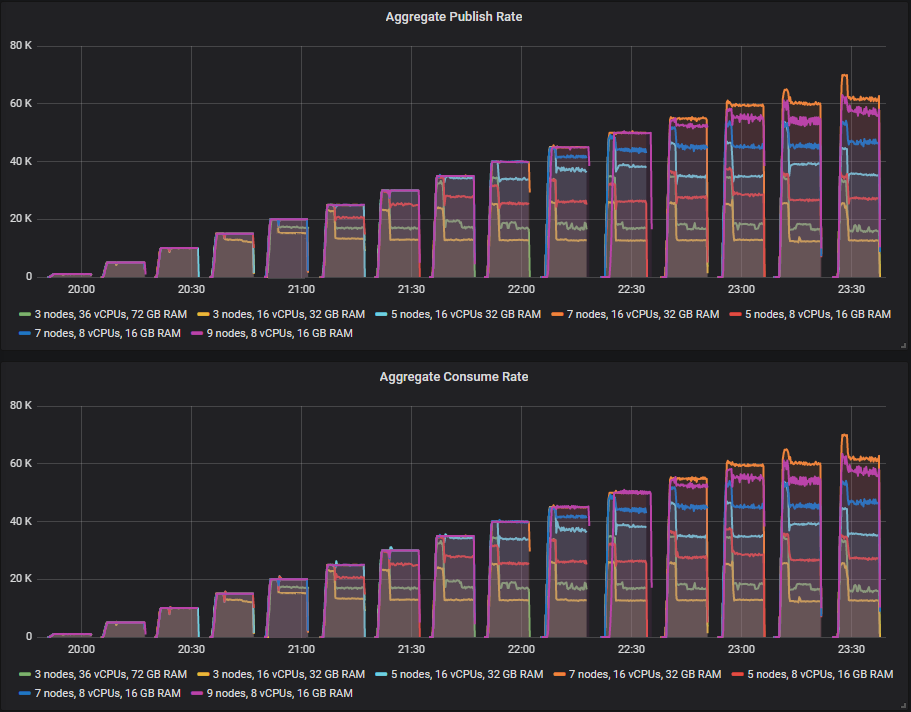
有些集群的表现比其他集群好,但没有集群能在没有吞吐量下降的情况下完成测试,当一个代理被杀死时。在较低强度的测试中,较小的 3 节点和 5 节点集群看到了这种下降,而 7 节点和 9 节点集群仅在较高强度下才开始看到这种下降。
让我们看看我们 30k msg/s 的目标速率周期。
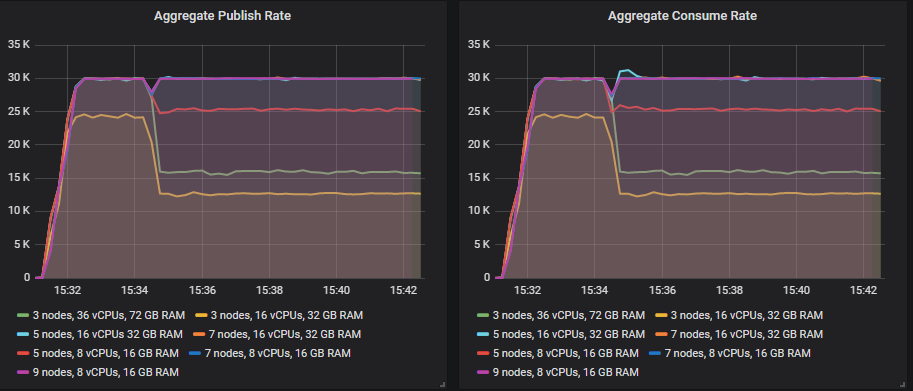
您会注意到,5x16、7x16、7x8 和 9x8 集群能够完全恢复,而在另一端,3 节点集群的下降幅度最大。对于那些完全恢复的集群,下降幅度很小,但这是在 *ha-sync-mode* 为 *manual* 的情况下。如果您选择 *automatic*,恢复仍然会发生,但下降幅度会更大,持续时间也更长。
吞吐量下降的原因是,当一个镜像队列因代理丢失而变得欠复制时,它会在另一个代理上创建一个新的镜像(如果可能的话),从而保持相同的冗余级别。这会将相同数量的流量集中到更少的代理上。因此,如果您使用复制因子 2(一个主,一个镜像),就像本测试一样,拥有三个代理并丢失一个,那么您将使另外两个代理的负载增加一个可观的百分比。如果您使用 *ha-mode=all*,则不会看到这种下降,因为没有代理可以放置新的镜像。
但是,如果您有九个节点并丢失一个,那么负载增加是微不足道的。
水平扩展在这方面占优。
恶劣条件 - 消费者速度变慢
在处理消息时,消费者通常需要与其他系统(如数据库或第三方 API)进行交互。这些下游系统可能会因为负载过重或某种中断而变慢,从而导致您的消费者速度变慢。这会导致您的队列中的消息数量增加,进而也可能影响发布者。RabbitMQ 在队列较小或为空时(因为消息被立即消费)表现最佳。
我们的要求规定,如果我们遇到消费者速度变慢的情况,发布应该不受影响,即使在目标峰值负载 30k msg/s 时也是如此。
在此测试中,每条消息的处理时间有所不同
- 5 分钟,10ms
- 在 20 分钟内从 10ms 增长到 30ms
- 5 分钟,30ms
- 在 20 分钟内从 30ms 减少到 10ms
- 50 分钟,10ms
消息积压可能增长到数千万,因为这是一个高流量系统,积压会快速形成。我们将看到消费速率呈现 S 形,因为首先处理时间增加,然后减少,消费速率随后超过发布速率,因为消费者处理积压的消息。
随着消费速率恢复,但队列长度仍然非常大,这时我们可能会看到对发布者的影响。发布速率可能会在一段时间内下降,直到积压的消息被清除。性能更好的集群应该不会受到影响,或者影响时间很短。
我们将进行三个不同发布速率的测试
- 10k msg/s,在 100 个队列上分布 200 个消费者。最高消费速率为 20k msg/s,在 30ms 处理时间时下降到 6.6k msg/s。
- 20k msg/s,在 100 个队列上分布 300 个消费者。最高消费速率为 30k msg/s,在 30ms 处理时间时下降到 10k msg/s。
- 30k msg/s,在 100 个队列上分布 400 个消费者。最高消费速率为 40k msg/s,在 30ms 处理时间时下降到 13.3k msg/s。
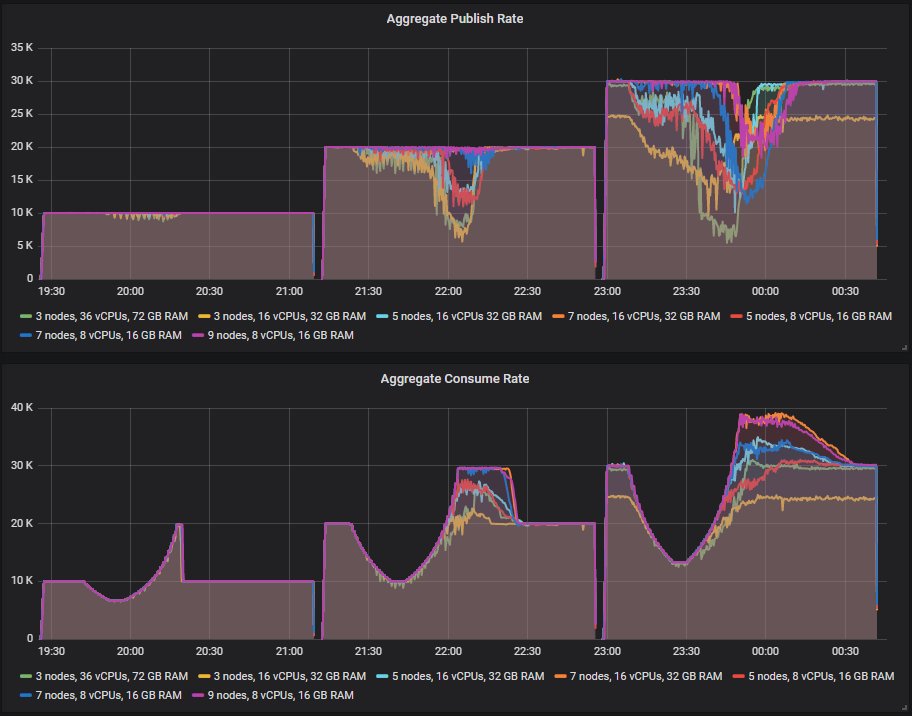
看看队列积压有多大的例子。
3x16 集群
7x16 集群
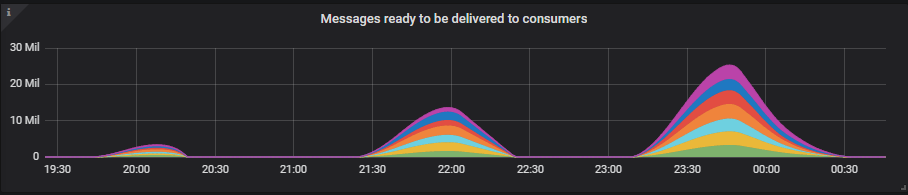
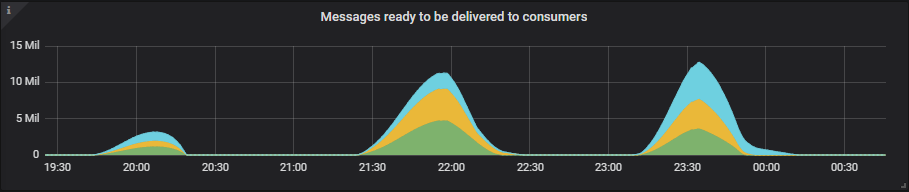
队列积压增长得相当大,但即便如此,我们也只达到了 11GB 最大内存限制的 50%。我们使用的默认内存高水位线是服务器内存的 40%。
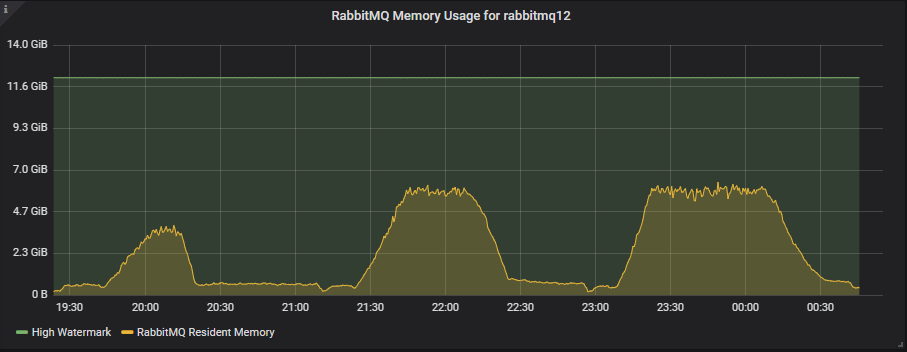
9x8 集群
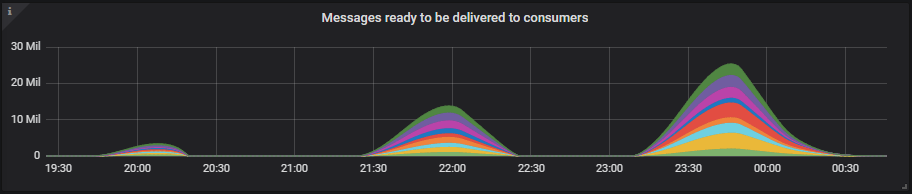
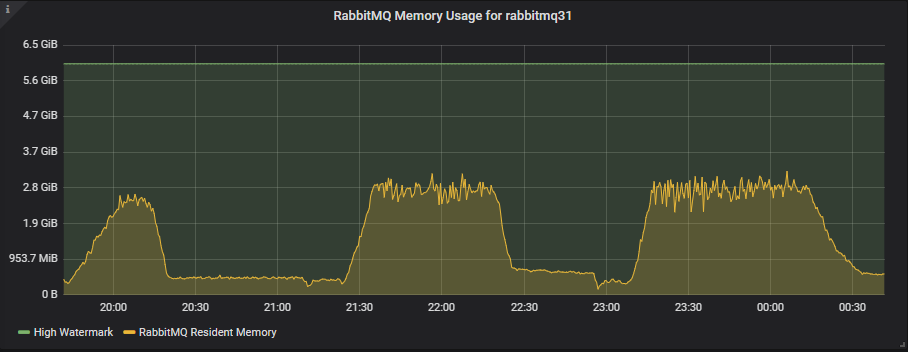
较小的 8 vCPU 实例拥有更少的内存,高水位线为 6GB,但这些测试只使用了其中大约一半。
在 10k msg/s 时,所有集群都能处理消费者速度变慢和相关的积压。
在 20k msg/s 时,只有 7x16 和 9x8 集群能在发布速率不下降的情况下处理。7x8 非常接近。其余集群在发布速率上有所下降,因为在队列积压仍然很高的情况下,消费者和发布者之间存在竞争。长队列效率较低,因为磁盘使用量增加以及内存中的数据结构。请注意,这是我们预期的峰值负载,但我们希望在此之上进行容量规划,以防万一(在 30k msg/s 时)。
但在 30k msg/s 时,我们的任何集群都无法在消费者速度变慢期间持续处理 30k msg/s。表现最好的是 7x16 和 9x8 集群,它们的发布速率在 20-25 分钟内有所降低。
所以,我们要么认为这已经足够好,要么需要进一步扩大规模,使用 9x16 或 11x8 集群。
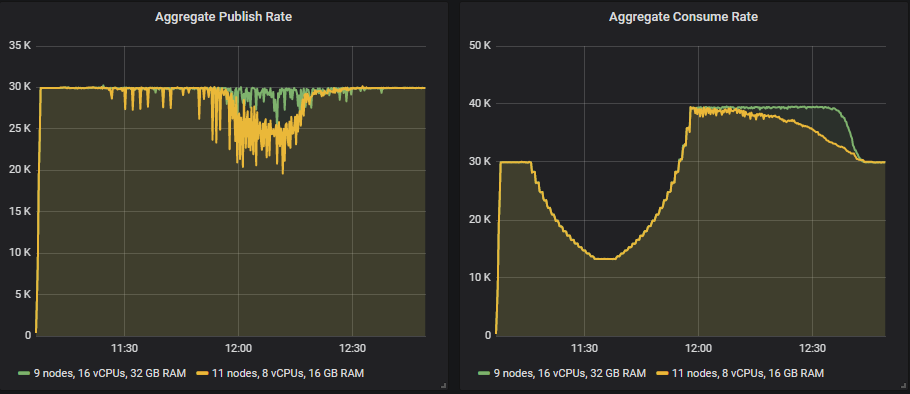
9x16 集群能够处理 30k msg/s 的负载,但发布速率略有波动。对于 8 vCPU 实例,看起来我们需要扩展到 13 个或更多实例。这些是大型集群,但这也是一个非常繁重的负载。
您可以使用 PerfTest(2.12 版本及更高版本)之类的工具运行测试。
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-c 1000 \
-ct -1 \
--rate 100 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
--producers 200 \
--consumers 200 \
--producer-random-start-delay 30 \
-vl 10000:300 \
-vl 11000:60 -vl 12000:60 -vl 13000:60 -vl 14000:60 -vl 15000:60 -vl 16000:60 -vl 17000:60 -vl 18000:60 -vl 19000:60 \
-vl 20000:60 -vl 21000:60 -vl 22000:60 -vl 23000:60 -vl 24000:60 -vl 25000:60 -vl 26000:60 -vl 27000:60 -vl 28000:60 -vl 29000:60 \
-vl 30000:300 \
-vl 29000:60 -vl 28000:60 -vl 27000:60 -vl 26000:60 -vl 25000:60 -vl 24000:60 -vl 23000:60 -vl 22000:60 -vl 21000:60 -vl 20000:60 \
-vl 19000:60 -vl 18000:60 -vl 17000:60 -vl 16000:60 -vl 15000:60 -vl 14000:60 -vl 13000:60 -vl 12000:60 -vl 11000:60 -vl 10000:60 \
-vl 10000:3000
恶劣条件 - 发布速率峰值超过消费者容量
与消费者速度变慢类似,我们最终会遇到发布速率超过消费速率导致消息积压的情况。但这次是由发布速率的巨大峰值引起的,我们的后端系统无法处理。吸收发布速率的峰值是选择消息队列的原因之一。您无需扩展后端系统来应对峰值负载,这可能很昂贵,而是允许消息队列吸收额外的流量。然后,您可以在一段时间内处理积压的消息。
在此测试中,我们将处理时间保持在 10ms,然后增加发布速率,再降低它
- 5 分钟,基础速率
- 在 20 分钟内从基础速率增长到峰值
- 5 分钟,峰值。
- 在 20 分钟内从峰值降低到基础速率
- 50 分钟,基础速率
我们将进行三个测试
- 10k msg/s 基础发布速率,20k msg/s 峰值。200 个消费者,13k msg/s 最高消费速率。
- 20k msg/s 基础发布速率,30k msg/s 峰值。300 个消费者,23k msg/s 最高消费速率。
- 30k msg/s 基础发布速率,40k msg/s 峰值。400 个消费者,33k msg/s 最高消费速率。
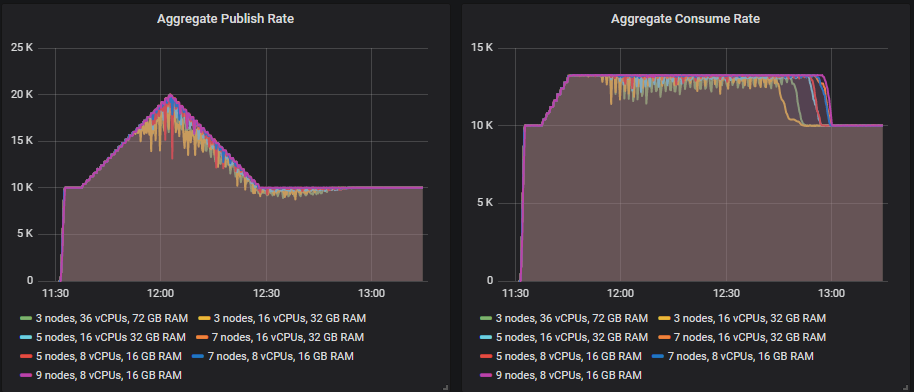
7x16、9x8、7x8 集群能够处理峰值,5x8 集群基本能处理,但发布速率有几次短暂下降。其他集群接近但未能处理目标速率。
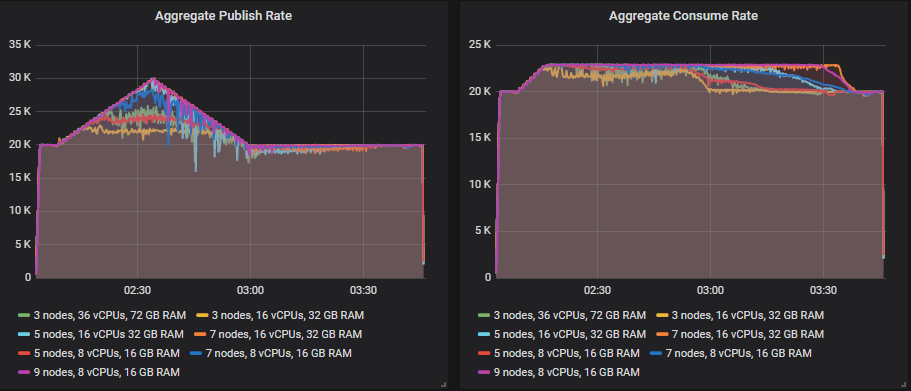
只有 7x16 和 9x8 集群能够处理,但 5 节点集群也非常接近。
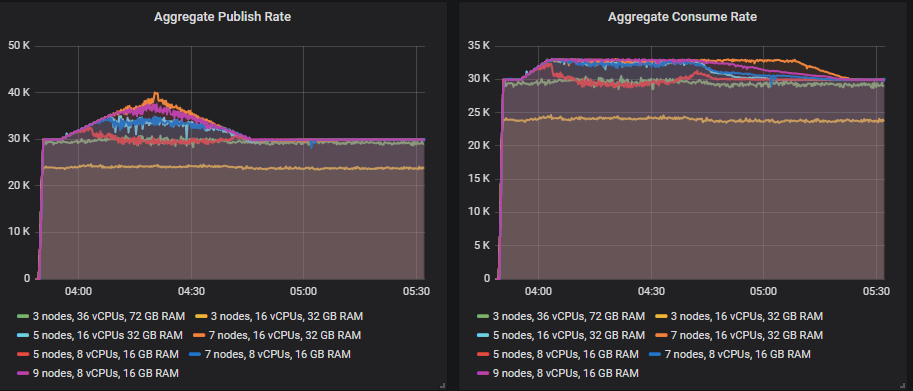
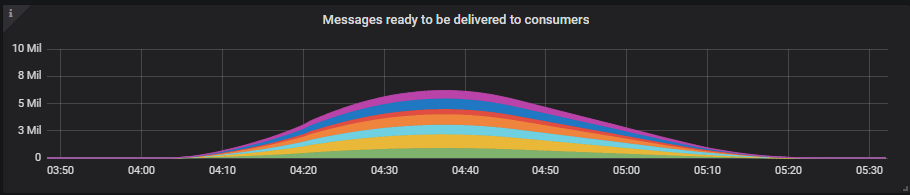
只有 7x16 集群达到了 40k msg/s 的发布速率,但 9x8 集群也很接近。7x16 的消息积压接近 700 万条,但它仍然能够处理。
您可以使用 PerfTest 运行测试。
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-ct -1 \
-c 1000 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
--producers 200 \
--consumers 200 \
--producer-random-start-delay 30 \
--consumer-latency 10000 \
-vr 100:300 \
-vr 102:60 -vr 104:60 -vr 106:60 -vr 108:60 -vr 110:60 -vr 112:60 -vr 114:60 -vr 116:60 -vr 118:60 -vr 120:60 \
-vr 122:60 -vr 124:60 -vr 126:60 -vr 128:60 -vr 130:60 -vr 132:60 -vr 134:60 -vr 136:60 -vr 138:60 -vr 140:60 \
-vr 142:60 -vr 144:60 -vr 146:60 -vr 148:60 -vr 150:60 \
-vr 148:60 -vr 146:60 -vr 144:60 -vr 142:60 -vr 140:60 -vr 138:60 -vr 136:60 -vr 134:60 -vr 132:60 -vr 130:60 \
-vr 128:60 -vr 126:60 -vr 124:60 -vr 122:60 -vr 120:60 -vr 118:60 -vr 116:60 -vr 114:60 -vr 112:60 -vr 110:60 \
-vr 108:60 -vr 106:60 -vr 104:60 -vr 102:60 -vr 100:60 \
-vr 100:3000
恶劣条件测试结论
在执行了正常场景测试后,我们有许多集群能够处理峰值负载,因此我们得到了一个成本效益(每 1000 msg/s 每月)排名前五的集群排行榜。现在,在运行了恶劣条件测试后,我们从原始集合中只剩下两个潜在的候选。
- 集群:7 个节点,16 个 vCPU,gp2 SSD。成本:每 1000 msg/s 104 美元
- 集群:9 个节点,8 个 vCPU,gp2 SSD。成本:每 1000 msg/s 81 美元
在正常场景下,使用较小 VM 进行水平扩展提供了最佳的最高吞吐量和成本效益。但考虑到容错测试,7x16 是全能型选手。
当然,即使是 7x16 集群在 30k msg/s 的消费者速度变慢测试中也遇到了困难。所以,我们可能仍然需要考虑这些集群:
- 集群:9 个节点,16 个 vCPU,gp2 SSD。成本:每 1000 msg/s 133 美元
- 集群:11 个节点,8 个 vCPU,gp2 SSD。成本:每 1000 msg/s 99 美元
镜像队列案例研究要点
请注意,只测试简单场景(如我们第一个正常场景测试,发布速率恒定,消费速率固定)是不可取的,您只是在理想条件下评估 RabbitMQ 的容量。如果您需要 RabbitMQ 在逆境中也能提供一定的吞吐量,那么您需要包含像本帖中那样的测试。在负载较高时,您更有可能遇到恶劣场景。由慢速消费者引起的队列积压在整个系统负载较高时更容易发生。同样,发布速率超过消费速率是由流量峰值引起的。因此,在峰值条件及以上进行测试对于确保集群能够承受您预期的负载至关重要。
底线是,RabbitMQ 能够很好地处理代理丢失,但它更难以应对队列积压。我们的顶级集群,7x16 和 9x8 配置在理想条件下可以达到 65-70k msg/s,但在我们进行的最恶劣条件下只能达到 20k msg/s。我说“只”20k msg/s,但这相当于每天 17 亿条消息,这高于 RabbitMQ 的大多数用例。
最后……这是一个特定的工作负载,请查看第一篇帖子中适用于其他工作负载和场景的建议:集群容量和其他注意事项。