集群容量规划案例研究 – 仲裁队列(第二部分)
在 上一篇文章 中,我们开始使用仲裁队列对我们的 工作负载 进行容量分析。我们专注于消费者能够跟上、队列没有积压且集群中所有代理程序都正常运行的理想情况。通过运行一系列基准测试,模拟不同强度的我们的工作负载,我们确定了每 1000 条消息/秒每月成本最低的前 5 个集群大小和存储卷组合。
- 集群:7 个节点,8 个 vCPU (c5.2xlarge),gp2 SSD。成本:54 美元
- 集群:9 个节点,8 个 vCPU (c5.2xlarge),gp2 SSD。成本:69 美元
- 集群:5 个节点,8 个 vCPU (c5.2xlarge),st1 HDD。成本:93 美元
- 集群:5 个节点,16 个 vCPU (c5.4xlarge),gp2 SSD。成本:98 美元
- 集群:7 个节点,16 个 vCPU (c5.4xlarge),gp2 SSD。成本:107 美元
还需要进行更多测试,以确保这些集群能够处理代理程序故障和因停机或系统减速而积压大量消息的情况。
所有仲裁队列都声明有以下属性
- x-quorum-initial-group-size=3
- x-max-in-memory-length=0
x-max-in-memory-length 属性强制仲裁队列在安全时尽快将消息体从内存中移除。您可以将其设置为更长的限制,这是最激进的设置——旨在避免内存大幅增长,但代价是在消费者跟不上时增加磁盘读取次数。没有此属性,消息体将始终保留在内存中,这可能导致内存增长到触发内存警报,严重影响发布速率——这是我们在本次工作负载案例研究中希望避免的。
不利条件 – 应对滚动重启和代理丢失
我们使用 Quorum Queues 是因为我们关心数据和可用性。如果由于磁盘故障而丢失代理,或者因为在紧急操作系统补丁中需要重启代理,那么我们可以获得持续的可用性和零数据丢失,但是我们能否维持每秒 30k 条消息的目标峰值速率?弹性不仅仅在于不丢失数据和保持可用,还在于能否充分处理负载。
为此,我们再次进行完全相同的测试,但在每个强度级别进行到一半时硬终止一个代理。
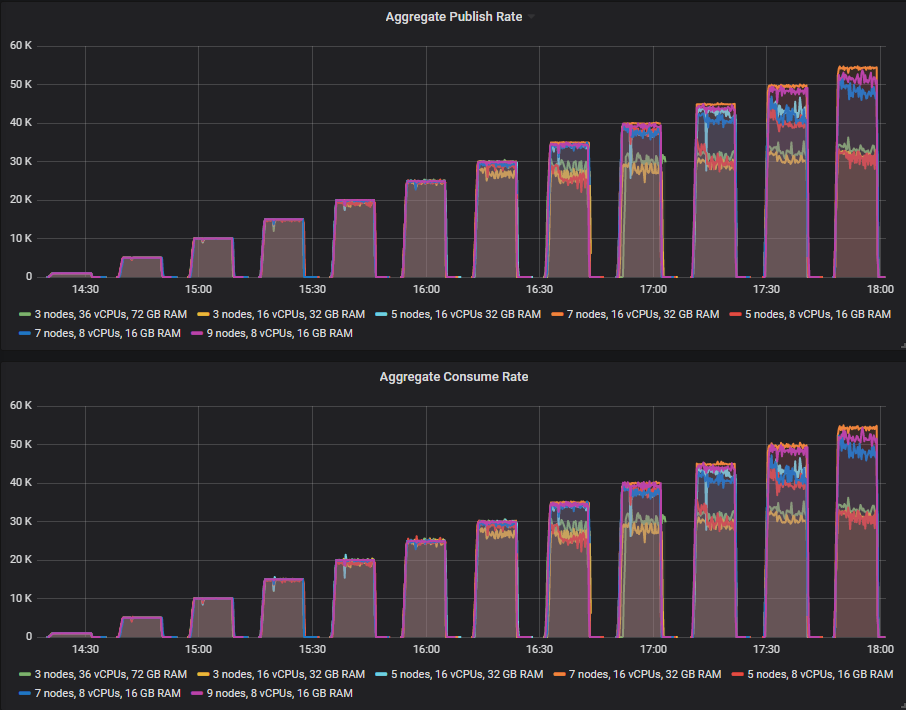
在具有镜像队列(一个主队列,一个镜像)的相同测试中,我们发现当终止一个代理时吞吐量有所下降。对于 Quorum Queues,我们没有看到如此强烈的影响。
让我们看看每秒 30k 条消息的目标速率周期。
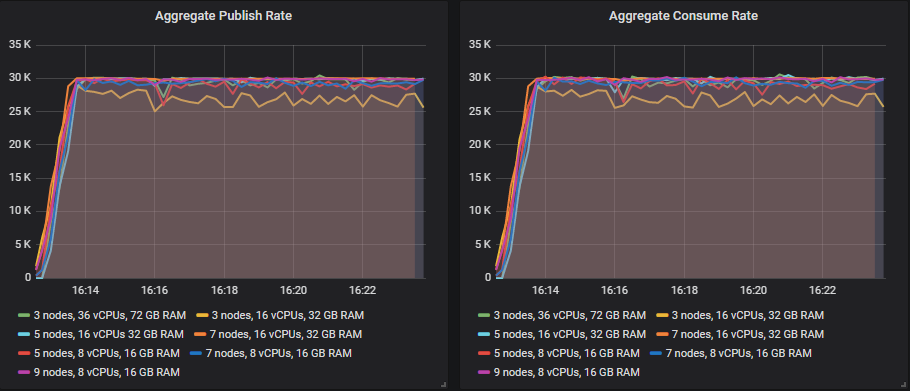
在镜像队列中丢失代理会产生巨大影响的原因是,当主队列或镜像队列丢失时,镜像队列会尝试通过在另一个代理上创建新镜像来维持冗余级别。这会将相同数量的消息流量集中到更少的服务器上。Quorum Queues 不会这样做。如果丢失了托管队列副本的代理,则该队列的成员身份不会改变。只要大多数队列副本(领导者、跟随者)可用,队列就会继续运行。一旦代理重新上线,该代理上的跟随者副本将再次开始被复制。
因此,复制流量不会集中到更少的服务器上,只有客户端流量会。Quorum Queues 还有一个优势,即如果一个消费者恰好连接到托管其想要消费的队列副本的代理,那么它会直接从该副本读取——无需从托管领导者的代理代理消息到消费者连接的代理。
由于镜像队列尝试通过创建新镜像来维持冗余级别,但同步是阻塞的,这削弱了这一优势。因此,许多管理员使用手动同步来避免在新镜像复制时剩余代理之间出现巨大的流量峰值。
最大的集群(7x16、7x8 和 9x8)在丢失代理时没有观察到明显影响。故障转移到新领导者很快,吞吐量也一如既往。
不利条件 – 消费者缓慢
在处理消息时,消费者通常需要与数据库或第三方 API 等其他系统进行交互。这些下游系统可能会因为负载过重或某种故障而变慢,从而导致你的消费者变慢。这会使队列中的消息数量增加,进而也会影响发布者。RabbitMQ 在队列较小或为空时(为空是因为消息被立即消费)提供最佳性能。
我们的要求规定,如果出现消费者缓慢的情况,发布应该不受影响,即使在每秒 30k 条消息的目标峰值负载下也是如此。
在此测试中,每条消息的处理时间会发生变化
- 5 分钟,处理时间为 10ms
- 在 20 分钟内,处理时间从 10ms 增加到 30ms
- 5 分钟,处理时间为 30ms
- 在 20 分钟内,处理时间从 30ms 减少到 10ms
- 50 分钟,处理时间为 10ms
消息积压可能会达到数千万条,因为这是一个高流量系统,积压会迅速形成。我们将看到一个 S 形的消费速率,因为处理时间首先会增加,然后减少,消费速率会超过发布速率,因为消费者正在处理积压的消息。
当消费速率恢复但队列长度仍然非常大时,这时我们可能会看到对发布者的影响。发布速率可能会暂时下降,直到积压被清除。性能更高的集群应该不会受到影响,或者只受到短暂影响。
我们将以三种不同的发布速率运行测试
- 每秒 10k 条消息,在 100 个队列上分布 200 个消费者。最高消费速率为每秒 20k 条消息,在 30ms 的处理时间下下降到每秒 6.6k 条消息。
- 每秒 20k 条消息,在 100 个队列上分布 300 个消费者。最高消费速率为每秒 30k 条消息,在 30ms 的处理时间下下降到每秒 10k 条消息。
- 每秒 30k 条消息,在 100 个队列上分布 400 个消费者。最高消费速率为每秒 40k 条消息,在 30ms 的处理时间下下降到每秒 13.3k 条消息。
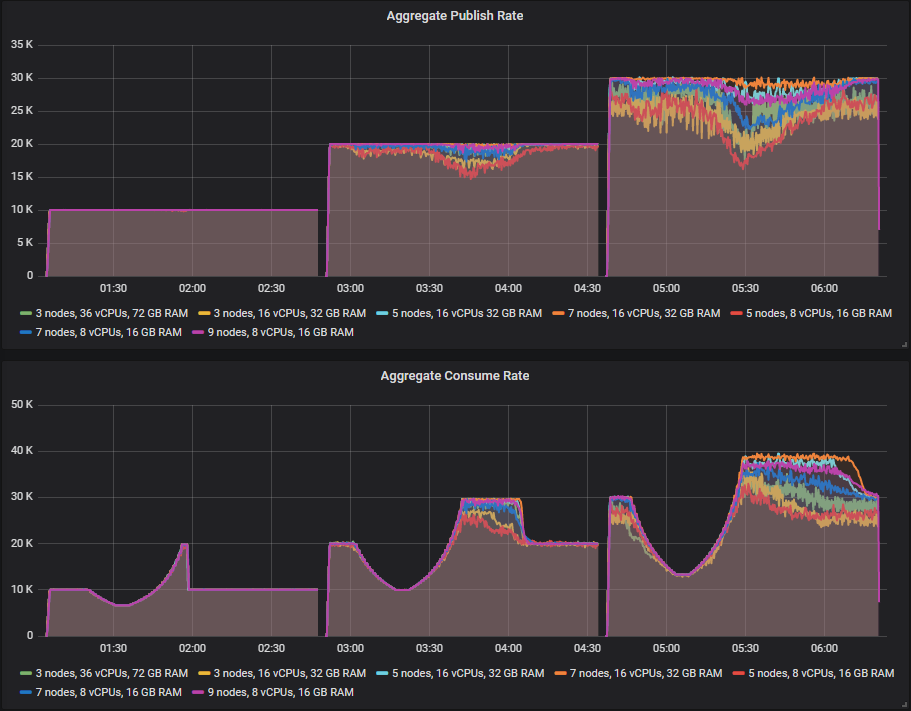
首先要注意的是,Quorum Queues 的表现比镜像队列好得多。在镜像队列测试中,没有任何集群能够在此测试中维持每秒 30k 条消息的发布速率,但对于 Quorum Queues,7x16 集群刚刚勉强处理了。
看看队列积压有多大的一些例子。
3x16 集群
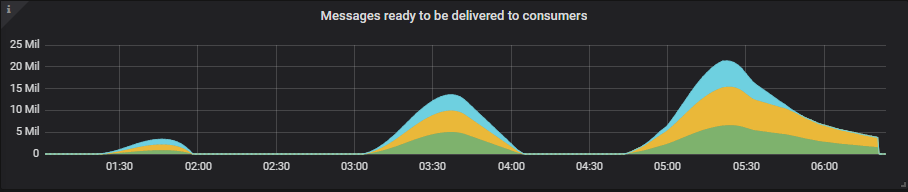
7x16 集群
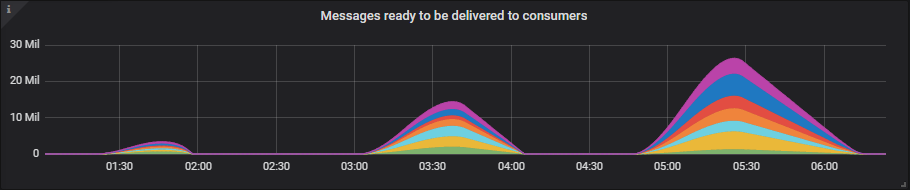
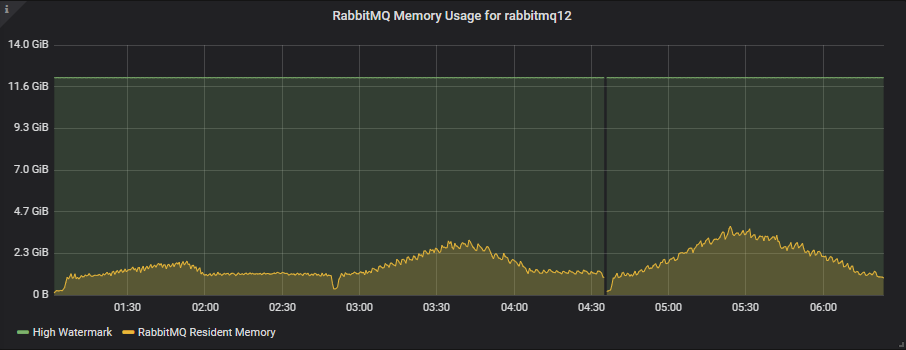
9x8 集群
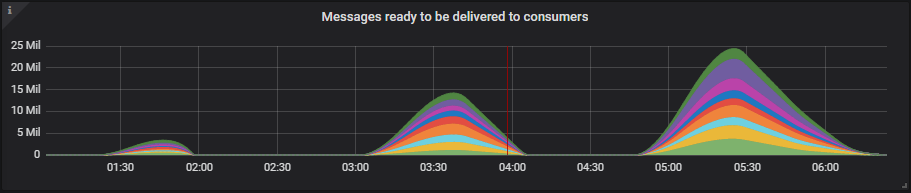
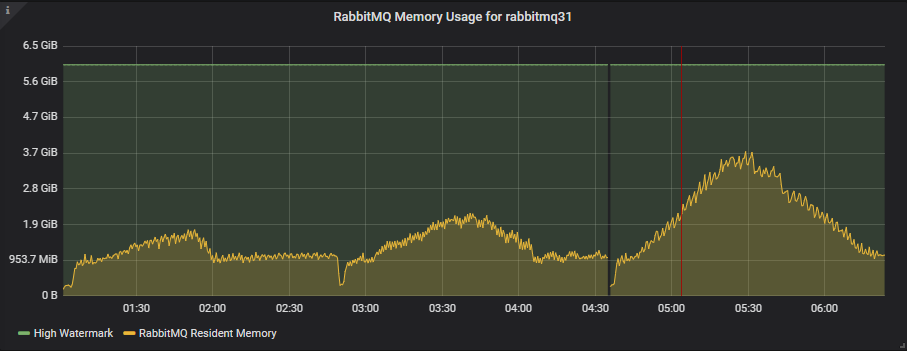
尽管 100 个队列的积压消息高达 2500 万条,但内存使用量仍远低于高水位线(届时内存警报将阻止发布者)。
所有集群都成功处理了每秒 10k 条消息的测试。在每秒 20k 条消息的测试中,只有两个集群(7x16 和 9x8)成功处理。7x16 集群是此测试中的明显赢家,因为它成功处理了非常严苛的每秒 30k 条消息的测试,该测试产生了高达 2500 万条消息的积压。
您可以使用 PerfTest (2.12 版本及更高版本) 运行此类测试
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-c 1000 \
-ct -1 \
-ad false \
--rate 100 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
-qa auto-delete=false,durable=false,x-queue-type=quorum \
--producers 200 \
--consumers 200 \
--producer-random-start-delay 30 \
-vl 10000:300 \
-vl 11000:60 -vl 12000:60 -vl 13000:60 -vl 14000:60 -vl 15000:60 -vl 16000:60 -vl 17000:60 -vl 18000:60 -vl 19000:60 \
-vl 20000:60 -vl 21000:60 -vl 22000:60 -vl 23000:60 -vl 24000:60 -vl 25000:60 -vl 26000:60 -vl 27000:60 -vl 28000:60 -vl 29000:60 \
-vl 30000:300 \
-vl 29000:60 -vl 28000:60 -vl 27000:60 -vl 26000:60 -vl 25000:60 -vl 24000:60 -vl 23000:60 -vl 22000:60 -vl 21000:60 -vl 20000:60 \
-vl 19000:60 -vl 18000:60 -vl 17000:60 -vl 16000:60 -vl 15000:60 -vl 14000:60 -vl 13000:60 -vl 12000:60 -vl 11000:60 -vl 10000:60 \
-vl 10000:3000
不利条件 – 发布速率峰值超过消费者容量
与消费者缓慢类似,我们最终也面临发布速率超过消费速率导致消息积压的情况。但这次是由发布速率的大幅峰值引起的,我们的后端系统无法处理。吸收发布速率的峰值是选择消息队列的原因之一。您无需扩展后端系统来处理峰值负载(这可能很昂贵),而是允许消息队列吸收额外的流量。然后,您可以在一段时间内处理积压的消息。
在此测试中,我们将处理时间保持在 10ms,但增加发布速率然后降低发布速率
- 5 分钟,基础速率
- 在 20 分钟内,从基础速率增长到峰值
- 5 分钟,峰值
- 在 20 分钟内,从峰值降低到基础速率
- 50 分钟,基础速率
我们将运行三个测试
- 基础发布速率为每秒 10k 条消息,峰值为每秒 20k 条消息。200 个消费者,最高消费速率为每秒 13k 条消息。
- 基础发布速率为每秒 20k 条消息,峰值为每秒 30k 条消息。300 个消费者,最高消费速率为每秒 23k 条消息。
- 基础发布速率为每秒 30k 条消息,峰值为每秒 40k 条消息。400 个消费者,最高消费速率为每秒 33k 条消息。
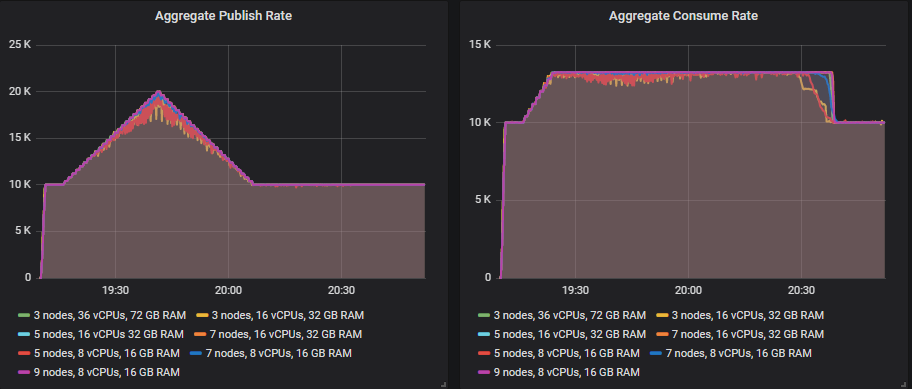
除 3x16 和 5x8 集群外,所有集群都成功达到了每秒 20k 条消息的发布速率峰值。
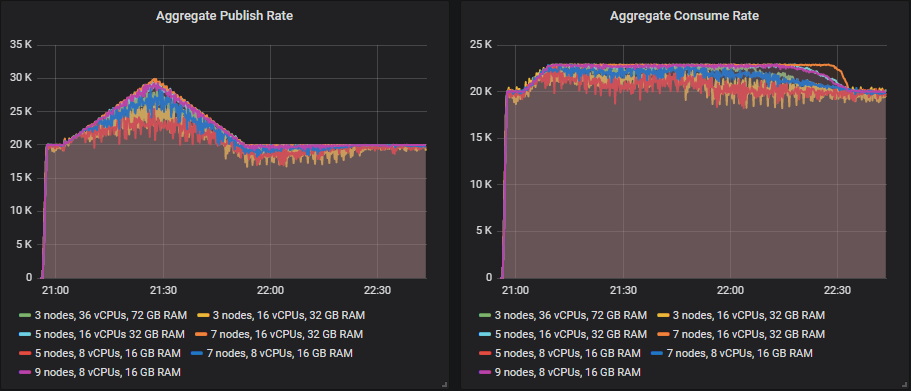
只有较大的 5x16、7x18 和 9x8 集群达到了每秒 30k 条消息的峰值。
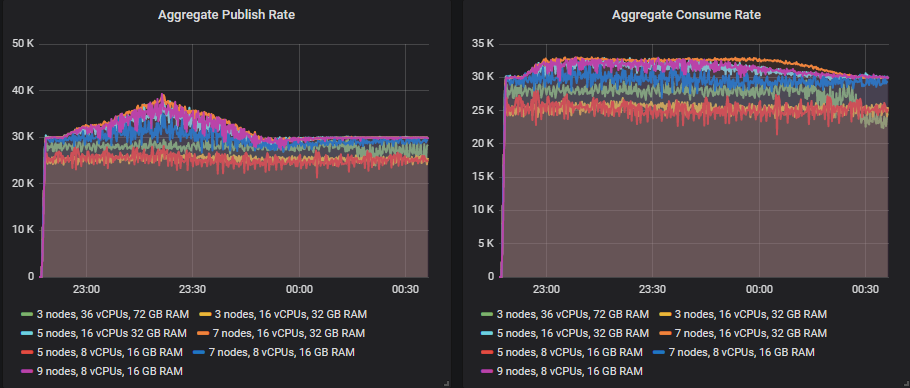
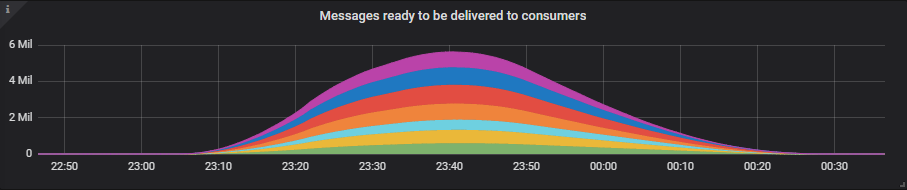
7x16 集群勉强达到了每秒 40k 条消息的峰值,其消息积压接近 600 万条,但它仍然处理了。
您可以使用 PerfTest 运行此类测试
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-ct -1 \
-ad false \
-c 1000 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
-qa auto-delete=false,durable=false,x-queue-type=quorum \
--producers 200 \
--consumers 200 \
--producer-random-start-delay 30 \
--consumer-latency 10000 \
-vr 100:300 \
-vr 102:60 -vr 104:60 -vr 106:60 -vr 108:60 -vr 110:60 -vr 112:60 -vr 114:60 -vr 116:60 -vr 118:60 -vr 120:60 \
-vr 122:60 -vr 124:60 -vr 126:60 -vr 128:60 -vr 130:60 -vr 132:60 -vr 134:60 -vr 136:60 -vr 138:60 -vr 140:60 \
-vr 142:60 -vr 144:60 -vr 146:60 -vr 148:60 -vr 150:60 \
-vr 148:60 -vr 146:60 -vr 144:60 -vr 142:60 -vr 140:60 -vr 138:60 -vr 136:60 -vr 134:60 -vr 132:60 -vr 130:60 \
-vr 128:60 -vr 126:60 -vr 124:60 -vr 122:60 -vr 120:60 -vr 118:60 -vr 116:60 -vr 114:60 -vr 112:60 -vr 110:60 \
-vr 108:60 -vr 106:60 -vr 104:60 -vr 102:60 -vr 100:60 \
-vr 100:3000
不利条件测试 – 结论
在执行了理想条件测试后,我们有许多集群能够处理峰值负载,因此我们得出了每 1000 条消息/秒每月成本排名前 5 的集群排行榜。现在,在运行了不利条件测试之后,我们从原始集合中只剩下两个潜在选择。7x16 是唯一能够处理所有测试的集群,但如果您也对成本敏感,那么更便宜的 9x8 在积压测试中也非常接近通过。
- 集群:7 个节点,16 个 vCPU,gp2 SSD。成本:每 1000 条消息/秒 104 美元
- 集群:9 个节点,8 个 vCPU,gp2 SDD。成本:每 1000 条消息/秒 81 美元
在理想条件下,扩展更小的虚拟机可为我们带来最佳的总吞吐量和成本效益。但考虑到不利条件,7x16 是全能选手。
对于此工作负载,我将选择 Quorum Queues (带 gp2 卷) 而不是镜像队列,因为它们在出现消息积压的情况下具有更强的持续处理入口速率的能力。当然,除此之外还有其他选择 Quorum Queues 的原因
- 更好的数据安全性
- 处理滚动重启时更高的可用性
Quorum Queue 案例研究要点
要点与镜像队列案例研究相同:不要只在理想条件下进行测试。确保将不利条件测试纳入您的方法论,否则您可能会发现您的集群在最需要时无法处理您的工作负载。系统在重负载下更容易出现此类问题,因此请在预期峰值负载级别及以上进行测试。
底线是,RabbitMQ 在处理代理丢失方面表现相当好,但在处理队列积压方面则更具挑战性。我们的顶级集群,7x16 和 9x8 的配置在理想条件下达到了每秒 65-70k 条消息,但在我们最不利的条件下,仅达到了每秒 20-30k 条消息。我说仅每秒 20-30k 条消息,但这相当于每天 17-25 亿条消息,这比大多数 RabbitMQ 的使用场景要高。
最后……这是一个特定的工作负载,请查看第一篇文章中的其他建议,这些建议可能适用于其他工作负载和场景。