集群规模案例研究 - 镜像队列 第一部分
在本系列规模分析的第一篇文章中,我们讨论了AWS EC2上的工作负载、集群和存储卷配置。在本文中,我们将进行镜像队列的规模分析。
我们规模分析的第一阶段将评估我们每个集群和存储卷能够轻松处理的负载强度,以及哪些负载过高。
所有测试均使用以下策略
- ha-mode: exactly
- ha-params: 2
- ha-sync-mode: manual
理想条件 - 递增负载测试
在之前的文章中,我们讨论了运行基准测试的选项。您可以使用以下命令以这些强度运行此工作负载:
bin/runjava com.rabbitmq.perf.PerfTest \
-H amqp://guest:guest@10.0.0.1:5672/%2f,amqp://guest:guest@10.0.0.2:5672/%2f,amqp://guest:guest@10.0.0.3:5672/%2f \
-z 1800 \
-f persistent \
-q 1000 \
-c 1000 \
-ct -1 \
--rate 50 \
--size 1024 \
--queue-pattern 'perf-test-%d' \
--queue-pattern-from 1 \
--queue-pattern-to 100 \
--producers 200 \
--consumers 200 \
--consumer-latency 10000 \
--producer-random-start-delay 30
只需更改每个测试所需的 --rate 参数,并请记住它是每个发布者的速率,而不是总合并速率。由于消费者处理时间(消费者延迟)设置为 10ms,因此我们还需要为更高的发布速率增加消费者数量。
在运行 PerfTest 之前,您需要创建一个策略,将创建的队列转换为镜像队列,并设置一个主队列和您希望测试的镜像数量。
io1 - 高性能 SSD
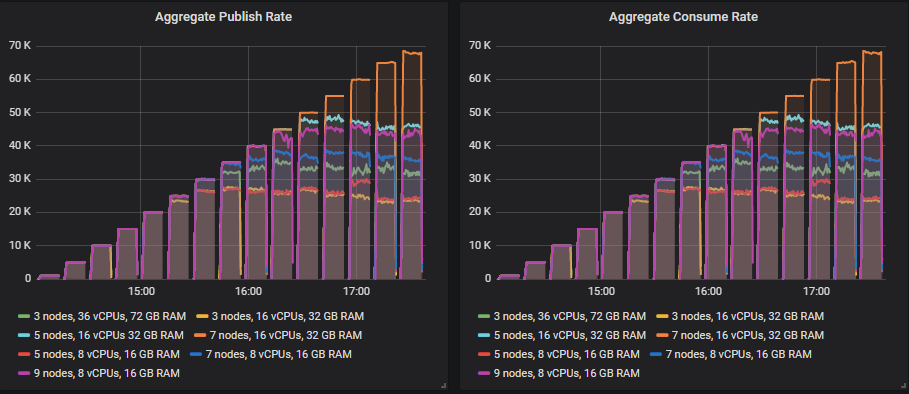
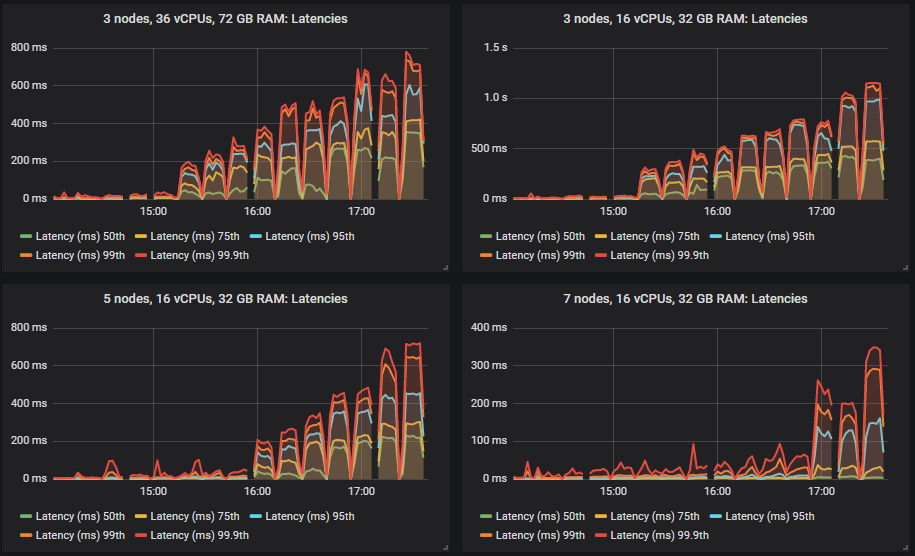
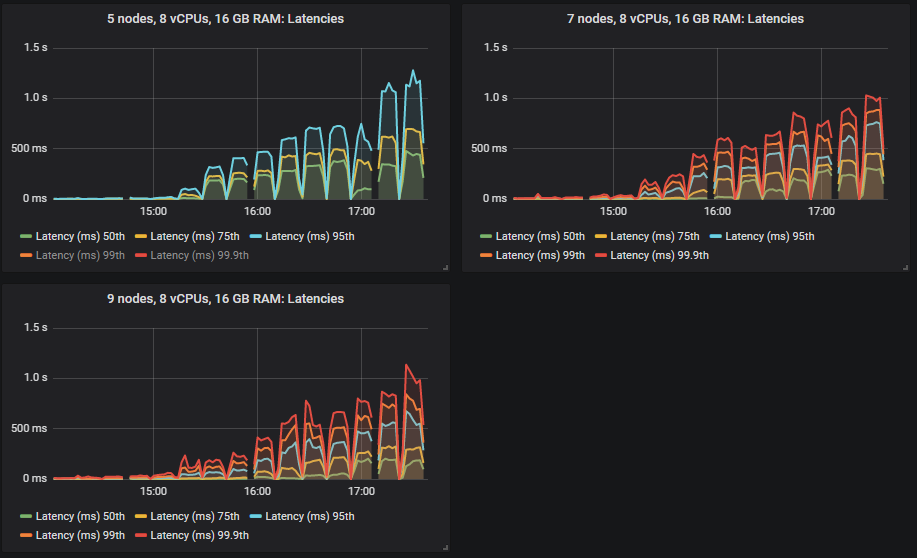
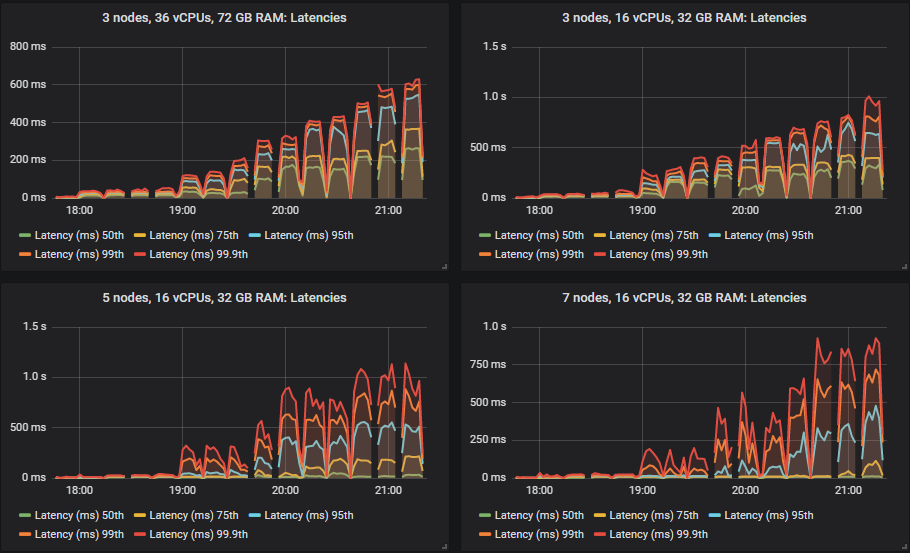
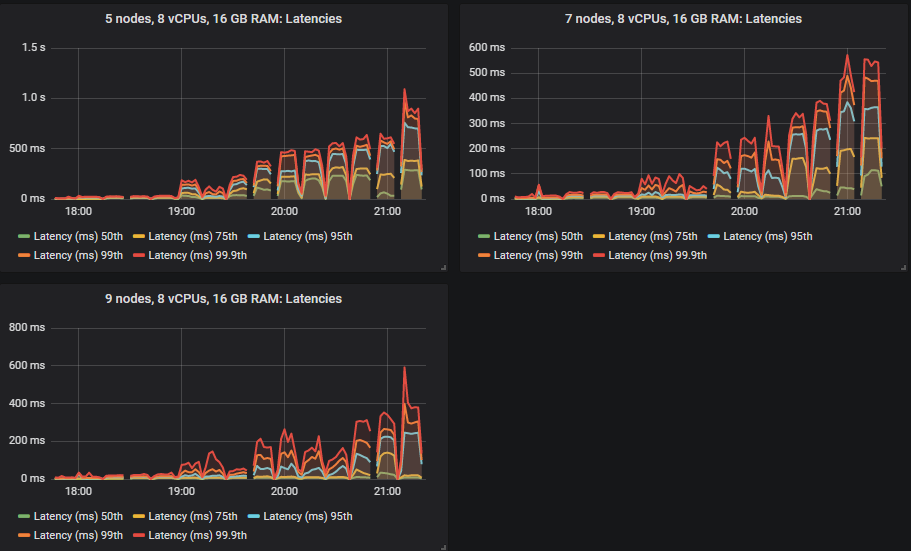
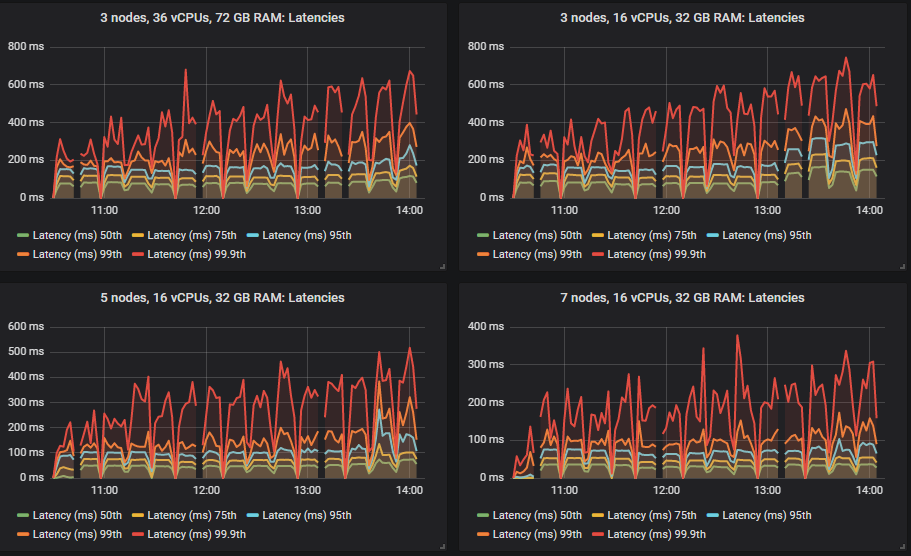
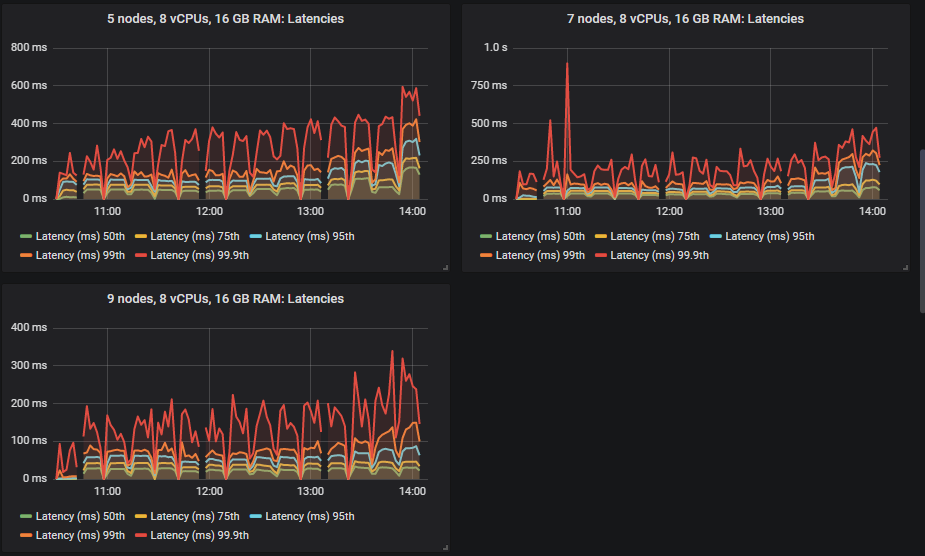
不同的集群能够达到不同的负载强度,但除一项外,所有测试的 99% 百分位数端到端延迟都保持在 1 秒以内。
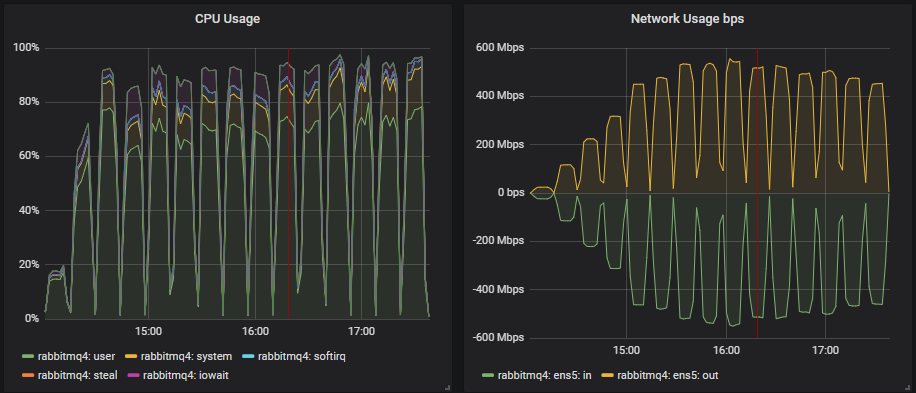
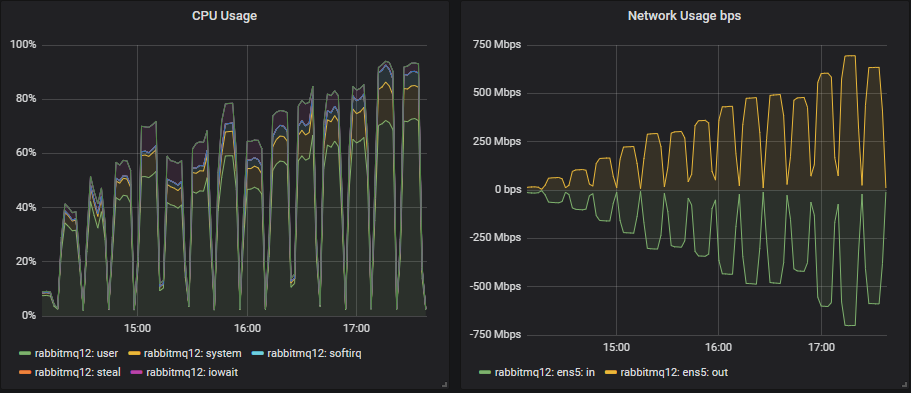
大多数测试的瓶颈是 CPU,因此拥有最多 CPU 的配置表现最好不足为奇。有趣的是,拥有第二高总 vCPU 数量的 3 节点、36 vCPU 集群(3x36)远低于 7x8 vCPU 集群。事实上,3x36 集群的 CPU 使用率并未超过 50%,这似乎是因为 Erlang 无法有效利用每个代理上的所有 36 个 vCPU(稍后详述)。
磁盘吞吐量远未达到容量,但在所有配置中,IOPS 达到了 8000-9000,写入大小约为 5-7kb。网络带宽低于 1gbit,都在所有 VM 的限制范围内。
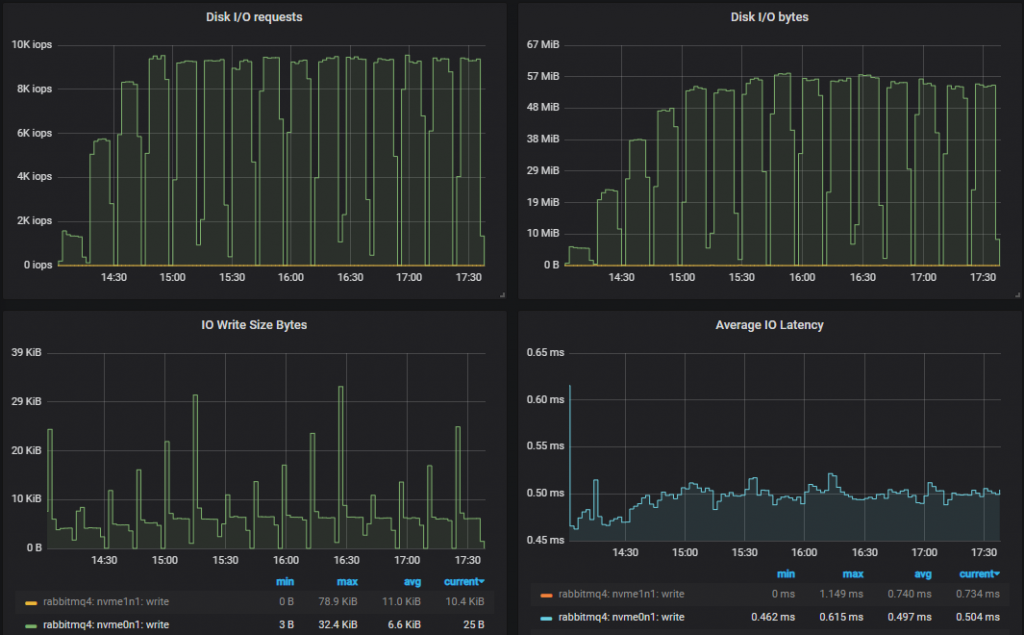
吞吐量最低的集群 (3x16):
吞吐量最高的集群 (7x16)
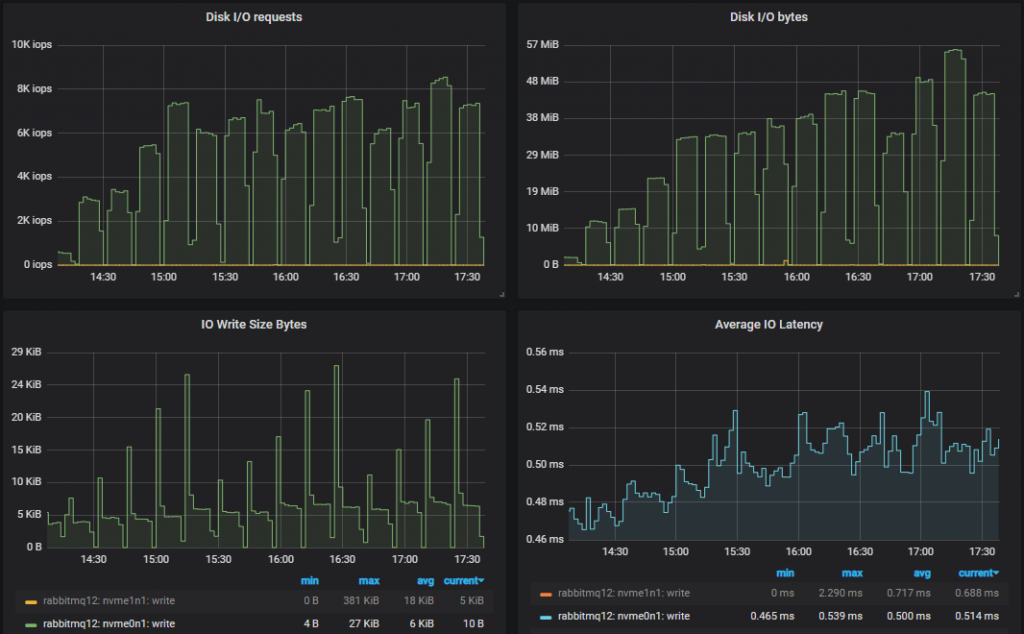
洞察:性能较低的 3x16 集群的磁盘写入吞吐量略高于性能最好的 7x16 集群。这是因为如果消息在执行 fsync 时已被消费,则不会持久化到磁盘。因此,当消费者跟上时,磁盘写入量较低。如果我们查看两者都能处理的最高 25k msg/s 的测试,我们会发现 3x16 集群的 95% 百分位数延迟约为 250ms,而 7x16 集群约为 4ms。Fsync 大约每 200ms 发生一次。因此,性能较高的集群写入次数较少。
匹配目标吞吐量的排行榜
每个集群规模能够达到的最高吞吐量,在此吞吐量下可以精确达到目标速率。
- 集群:7 节点,16 vCPU (c5.4xlarge)。速率:65k 消息/秒
- 集群:5 节点,16 vCPU (c5.4xlarge)。速率:45k 消息/秒
- 集群:9 节点,8 vCPU (c5.2xlarge)。速率:45k 消息/秒
- 集群:7 节点,8 vCPU (c5.2xlarge)。速率:40k 消息/秒
- 集群:3 节点,36 vCPU (c5.9xlarge)。速率:30k 消息/秒
- 集群:5 节点,8 vCPU (c5.2xlarge)。速率:20k 消息/秒
- 集群:3 节点,16 vCPU (c5.4xlarge)。速率:20k 消息/秒
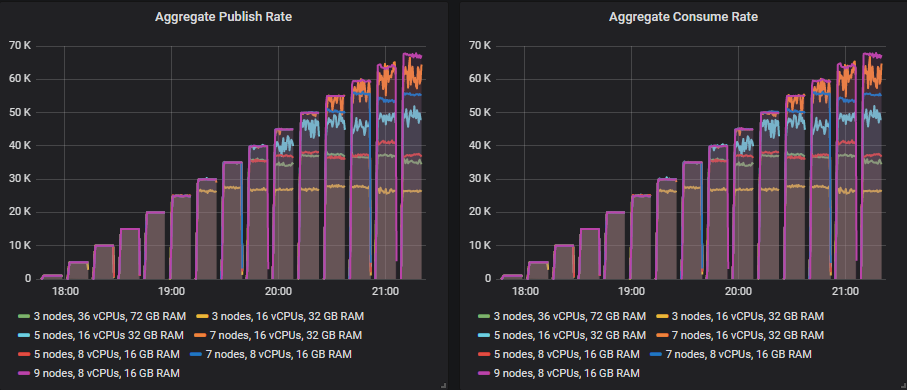
我们发现,横向扩展和纵向扩展相结合提供了最佳吞吐量,而仅横向扩展也表现不错。纵向扩展效果不佳。
按最高吞吐量计算,每 1000 消息/秒/月的成本排行榜。
- 集群:5 节点,16 vCPU。成本:134 美元 (45k 消息/秒)
- 集群:7 节点,16 vCPU。成本:140 美元 (65k 消息/秒)
- 集群:7 节点,8 vCPU。成本:170 美元 (40k 消息/秒)
- 集群:3 节点,16 vCPU。成本:182 美元 (20k 消息/秒)
- 集群:3 节点,36 vCPU。成本:182 美元 (30k 消息/秒)
- 集群:9 节点,8 vCPU。成本:194 美元 (45k 消息/秒)
- 集群:5 节点,8 vCPU。成本:242 美元 (20k 消息/秒)
在目标吞吐量为 30k 消息/秒时,每 1000 消息/秒/月的成本排行榜。
- 集群:3 节点,36 vCPU。成本:183 美元
- 集群:5 节点,16 vCPU。成本:202 美元
- 集群:7 节点,8 vCPU。成本:226 美元
- 集群:9 节点,8 vCPU。成本:291 美元
- 集群:7 节点,16 vCPU。成本:307 美元
虽然使用较小 VM 进行横向扩展的吞吐量尚可,但由于磁盘是我们最昂贵的项目,这被抵消了。由于磁盘昂贵,成本效益最高的集群是实例数量最少的集群,然而,这个 3x36 集群在理想条件测试的峰值勉强达标,在更困难的测试中不太可能坚持下来。因此,如果我们忽略 3x36 集群,那么成本效益最高的是横向和纵向扩展相结合的中间方案。
我们真的需要那些昂贵的 io1 SSD 吗?我们不需要它们用于 IO 吞吐量,但那 10000 IOPS 几乎被充分利用。3000 IOP gp2 能否应对更高的负载强度?
gp2 - 通用 SSD
同样,不同的集群处理了不同的吞吐量,但都符合端到端延迟要求。
gp2 卷带来了新的赢家:9x8 集群,其次是 7x8 集群。7x16 和 5x16 在达到并超过其最大容量后,吞吐量出现了一些波动。最后的两个是相同的:3x36 和 3x16 集群。
那么 RabbitMQ 如何处理较低 IOPs 的卷呢?
吞吐量最低的集群 (3x16)
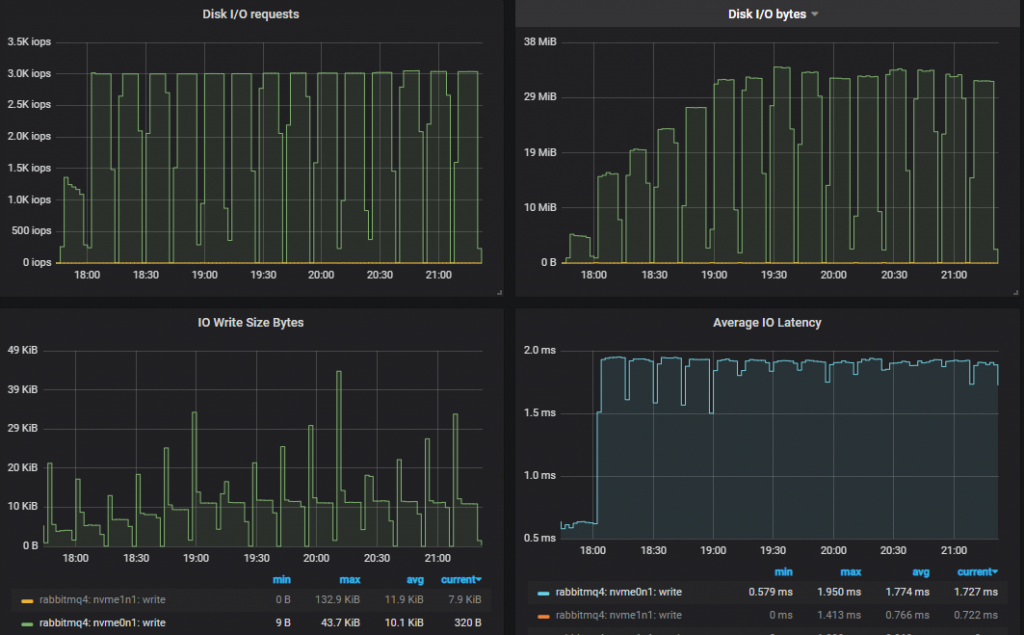
从 5000 消息/秒的速率开始,我们达到了 3000 IOPs 的限制。随着测试的进行,为了应对更大的磁盘吞吐量,IO 大小会增加。因此,看来我们并不需要所有这些 IOPs。
吞吐量最高的集群 (9x8)
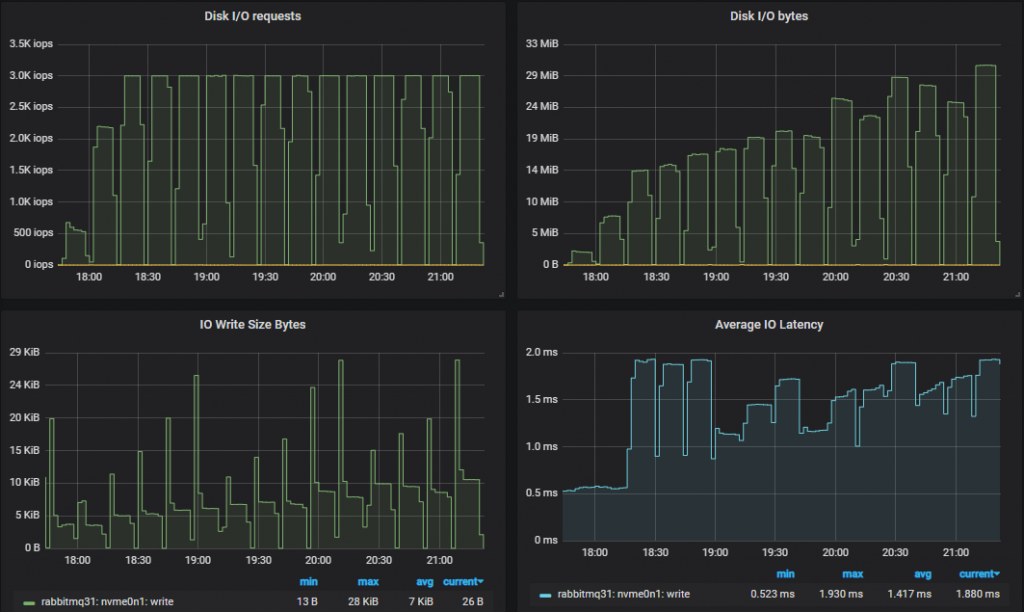
最高性能集群的情况完全相同 - RabbitMQ 适应了较低的可用 IOPs。
匹配目标吞吐量的排行榜
- 集群:9 节点,8 vCPU (c5.2xlarge)。速率:65k 消息/秒
- 集群:7 节点,8 vCPU (c5.2xlarge)。速率:50k 消息/秒
- 集群:7 节点,16 vCPU (c5.4xlarge)。速率:50k 消息/秒
- 集群:5 节点,16 vCPU (c5.4xlarge)。速率:40k 消息/秒
- 集群:3 节点,36 vCPU (c5.9xlarge)。速率:35k 消息/秒
- 集群:5 节点,8 vCPU (c5.2xlarge)。速率:35k 消息/秒
- 集群:3 节点,16 vCPU (c5.4xlarge)。速率:25k 消息/秒
这次,横向扩展显然是最有效的。纵向扩展效果不佳。
按最高吞吐量计算,每 1000 消息/月的成本排行榜。
- 集群:9 节点,8 vCPU。成本:48 美元 (65k 消息/秒)
- 集群:7 节点,8 vCPU。成本:48 美元 (50k 消息/秒)
- 集群:5 节点,8 vCPU。成本:49 美元 (35k 消息/秒)
- 集群:3 节点,16 vCPU。成本:71 美元 (25k 消息/秒)
- 集群:5 节点,16 vCPU。成本:74 美元 (40k 消息/秒)
- 集群:7 节点,16 vCPU。成本:96 美元 (50k 消息/秒)
- 集群:3 节点,36 vCPU。成本:103 美元 (35k 消息/秒)
就每 1000 消息/秒/月的成本而言,排序是:核心数降序,节点数降序。
在目标为 30k 消息/秒时,每 1000 消息/月的成本排行榜。
- 集群:5 节点,8 vCPU。成本:58 美元
- 集群:7 节点,8 vCPU。成本:81 美元
- 集群:5 节点,16 vCPU。成本:98 美元
- 集群:9 节点,8 vCPU。成本:104 美元
- 集群:3 节点,36 vCPU。成本:120 美元
- 集群:7 节点,16 vCPU。成本:161 美元
在 30k 消息/秒的目标速率下,5x8 是最好的。结论是,横向扩展较小的 VM 既能提供更好的性能,又能提供最佳的成本效益。原因是 gp2 卷相对便宜,而且我们不会像使用昂贵的 io1 卷时那样,因为横向扩展而受到惩罚。
st1 - 硬盘
到目前为止,我们已经看到 RabbitMQ 利用了它可用的 IOPs,通过根据需要调整到较低的 IOPs。硬盘专为低 IOPs 的大容量顺序工作负载而设计,那么 RabbitMQ 是否能够再次调整其磁盘操作,以进行更少但更大的磁盘操作?让我们看看。
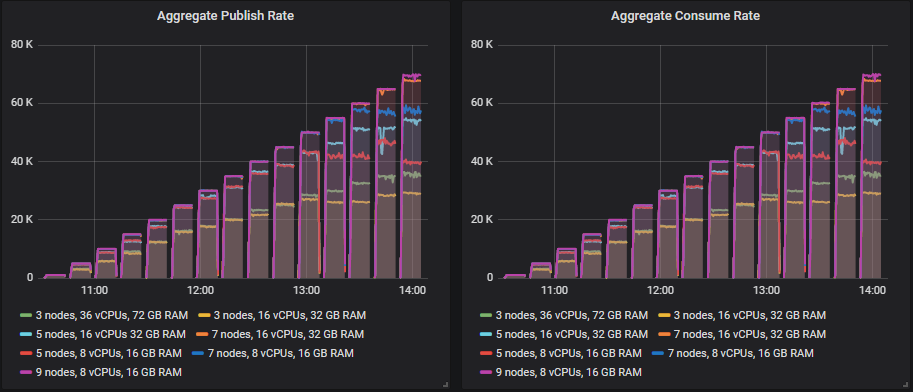
从吞吐量来看,硬盘在最高吞吐量方面表现最好,实际上达到了 70k 消息/秒的最高负载强度。端到端延迟呈现不同的模式。对于 SSD,延迟一开始非常小,然后随着负载的增加而增长。但硬盘一开始的延迟要高得多,并且增长速度要慢得多。
让我们看看 RabbitMQ 如何使用可用的 IOPs。
吞吐量最低的集群 (3x16)
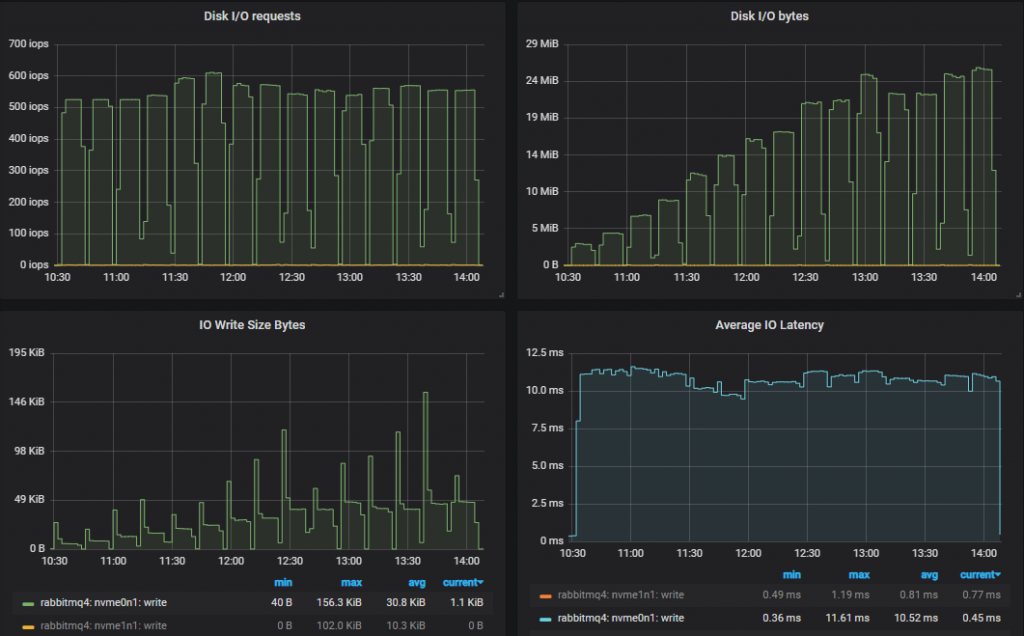
我们现在降到了 500-600 IOPS,平均写入大小接近 50kb(忽略初始峰值)。操作次数少得多,但 IO 操作大得多。IO 延迟要高得多。我们从 0.5ms (io1)、2ms (gp2) 提高到了 10ms (st1),这可能是 IO 大小和存储驱动器执行随机 IO 能力的综合结果。稍后,我们将比较三种卷类型的端到端延迟。
吞吐量最高的集群 (9x8)
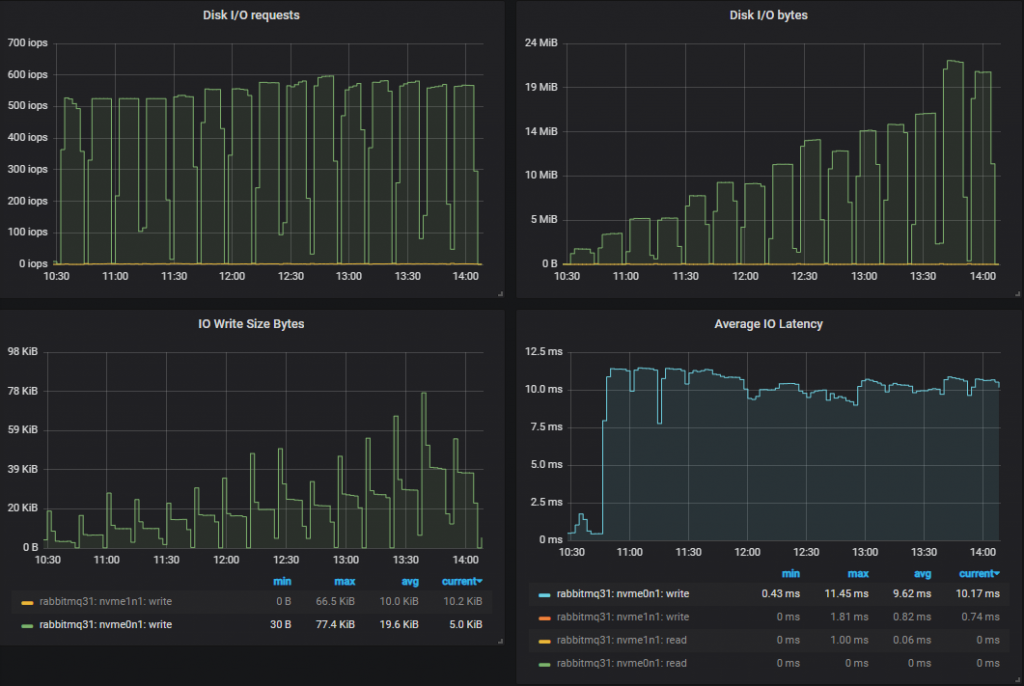
吞吐量排行榜
只有三个规模能够达到目标,其余的即使在每个测试中吞吐量都在攀升,也始终达不到目标。我们也许可以通过不同的发布者确认在途限制来提高吞吐量,更高的限制可能会使高延迟的硬盘受益。
能够达到目标的赢家是
- 集群:9 节点,8 vCPU (c5.2xlarge)。速率:70k 消息/秒
- 集群:7 节点,16 vCPU (c5.4xlarge)。速率:65k 消息/秒
- 集群:7 节点,8 vCPU (c5.2xlarge)。速率:55k 消息/秒
其余集群在每次测试中都未能达到目标,但随着测试的进行,吞吐量仍然有所提高。
- 集群:5 节点,16 vCPU (c5.4xlarge)。速率:55k 消息/秒
- 集群:5 节点,8 vCPU (c5.2xlarge)。速率:43k 消息/秒
- 集群:3 节点,36 vCPU (c5.9xlarge)。速率:35k 消息/秒
- 集群:3 节点,16 vCPU (c5.4xlarge)。速率:29k 消息/秒
对于硬盘,关键在于横向扩展,而不是纵向扩展。
按最高速率计算,每 1000 消息/月的成本排行榜。
- 集群:5 节点,8 vCPU。成本:65 美元 (43k 消息/秒)
- 集群:7 节点,8 vCPU。成本:71 美元 (55k 消息/秒)
- 集群:9 节点,8 vCPU。成本:72 美元 (70k 消息/秒)
- 集群:5 节点,16 vCPU。成本:73 美元 (55k 消息/秒)
- 集群:3 节点,16 vCPU。成本:83 美元 (29k 消息/秒)
- 集群:7 节点,16 vCPU。成本:97 美元 (65k 消息/秒)
- 集群:3 节点,36 vCPU。成本:121 美元 (35k 消息/秒)
在目标为 30k 消息/秒时,每 1000 消息/月的成本排行榜。
- 集群:5 节点,8 vCPU。成本:93 美元
- 集群:7 节点,8 vCPU。成本:131 美元
- 集群:5 节点,16 vCPU。成本:134 美元
- 集群:3 节点,36 vCPU。成本:142 美元
- 集群:9 节点,8 vCPU。成本:168 美元
- 集群:7 节点,16 vCPU。成本:211 美元
在其最高吞吐量方面,显然较小的 VM 成本效益最高。但当考虑 30k 消息/秒的目标时,横向扩展/纵向扩展相结合的方案表现最好。这里再次出现了一个矛盾:横向扩展在性能和成本方面都最好(st1 卷有点贵)。因此,中间方案获胜。
端到端延迟和三种卷类型
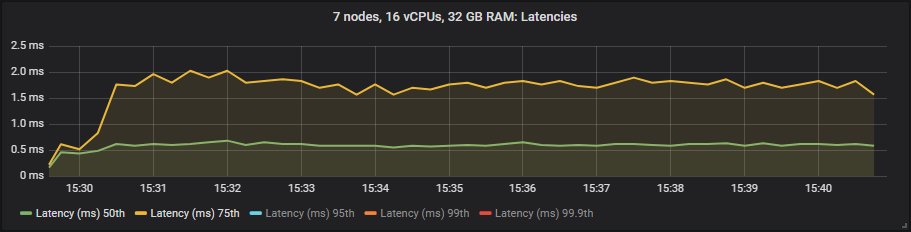
在这些测试中,我们将端到端延迟定义为消息发布和消耗之间的时间。如果我们查看 30k 消息/秒的目标速率和 7x16 集群类型,我们看到:
io1
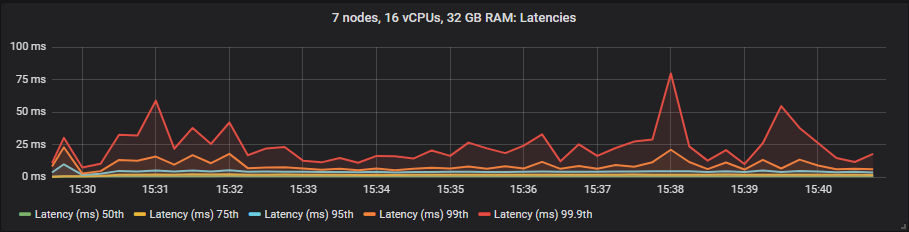
gp2
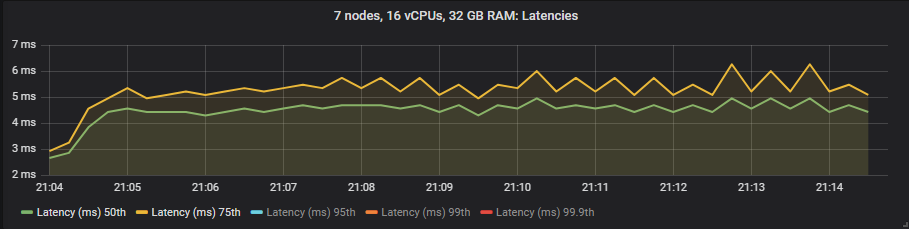
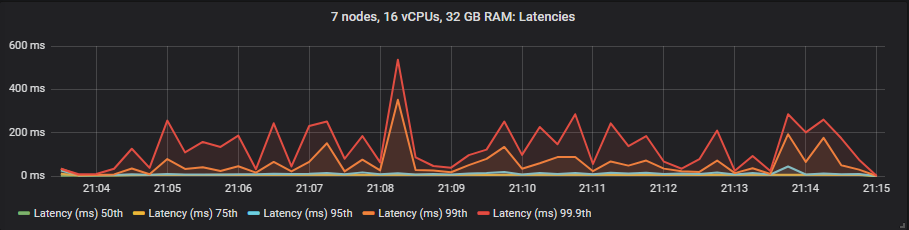
st1
我们看到 io1 在 95% 百分位数之前提供了最佳延迟,之后它与 gp2 大致相当。st1 硬盘的延迟要高得多,但仍在我们的 1 秒目标范围内。
CPU 利用率和 36 vCPU VM
在 8 和 16 vCPU(CPU 线程)实例中,CPU 似乎是瓶颈。一旦 CPU 使用率超过 90%,我们就看不到吞吐量有任何进一步的增加。然而,36 vCPU 实例总是看起来像这样:
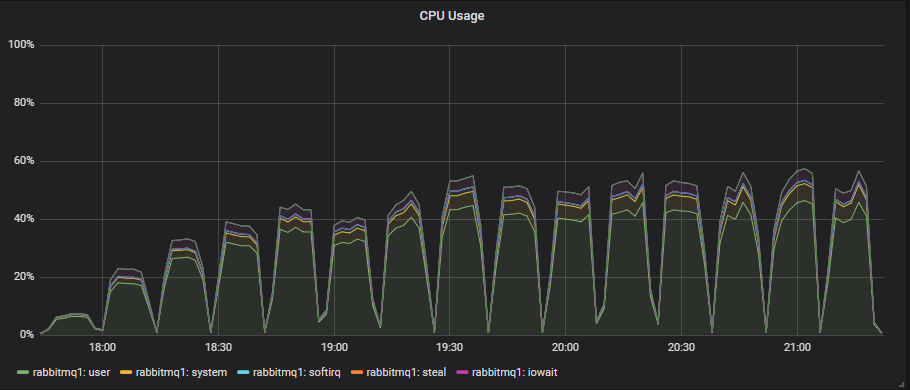
CPU 利用率和 Erlang 并不总是那么直观。Erlang 调度器在认为这样做更有效时会执行忙等待。这意味着调度器不会休眠,而是处于忙碌循环中,在等待新工作时会利用 CPU。这可能会给人一种 Erlang 应用程序正在做大量工作、消耗 CPU 的印象,但实际上它只是在等待工作。
在这种情况下,36 个 vCPU 纯粹是浪费。我们已经看到它们更昂贵,并且与横向扩展的较小 VM 相比,性能较差。
递增负载基准测试 - 结论
到目前为止的结论是:
- 昂贵的 io1 只有在我们非常关心端到端延迟时才值得。
- 价格便宜的 gp2 提供了性能和成本的最佳组合,是大多数工作负载的最佳选择。请记住,我们使用的是一个 1TB 的卷,它没有突发 IOPs,并且有一个 250 MiBs 的限制(我们从未达到)。
- 对于廉价的存储卷,横向扩展较小的 8 vCPU VM 在成本效益和性能方面都是最好的。
- 对于昂贵的卷,选择横向扩展和纵向扩展相结合的中间方案是最具成本效益的。
- CPU 利用率似乎是 16 和 8 vCPU 的瓶颈。大型 36 vCPU 实例的利用率不超过 60%,但也没有达到磁盘或网络限制。Erlang 就是无法有效地利用如此多的核心。
按 30k 消息/秒吞吐量计算,每 1000 消息/秒/月的成本排名前 5 的配置
- 集群:5 节点,8 vCPU,gp2 SSD。成本:58 美元
- 集群:7 节点,8 vCPU,gp2 SSD。成本:81 美元
- 集群:5 节点,8 vCPU,st1 HDD。成本:93 美元
- 集群:5 节点,16 vCPU,gp2 SSD。成本:98 美元
- 集群:9 节点,8 vCPU,gp2 SSD。成本:104 美元
我们只在理想条件下进行了测试……
我们从 21 种不同的集群配置和 15 种不同的工作负载强度中收集了大量数据。我们认为到目前为止,我们应该选择一个在廉价 gp2 卷上使用中等到大型集群的中小型 VM。但这只是测试了队列为空或接近为空的理想情况,此时 RabbitMQ 以其峰值性能运行。接下来,我们将进行更多测试,以确保尽管代理丢失和队列积压,我们选择的集群规模仍能提供我们所需性能。下一篇我们测试弹性。