集群容量规划和其他注意事项
这是我们开始查看 RabbitMQ 集群容量规划的短系列文章的开篇。实际容量规划完全取决于您的硬件和工作负载,因此,我们不会告诉您应该配置多少 CPU 和多少 RAM,而是会制定一些通用指南,并使用案例研究来展示您应该考虑的事项。
常见问题
您的 RabbitMQ 集群的最佳虚拟机大小和数量组合是什么?是应该选择三个节点、32 个 CPU 线程进行横向扩展?还是应该选择九个节点、8 个 CPU 线程进行纵向扩展?哪种类型的磁盘最具性价比?您需要多少内存?哪种硬件配置更适合吞吐量、延迟和拥有成本?
首先,没有唯一的答案。如果您在云上运行,那么选项会少一些,但如果您在本地运行,那么现有的虚拟化、存储和网络产品以及配置数量庞大,这使得这个问题不可能有标准答案。
虽然没有一个带有硬性数字的单一容量规划指南,但我们可以进行容量规划分析,希望这能帮助您进行自己的容量规划。
一些常见注意事项
队列和客户端的数量
客户端连接和队列需要计算时间和内存。如果您有数千个队列和客户端,那么这将影响您的容量规划。数量越多,您可能需要的 CPU 核心和内存就越多。队列和客户端数量少,RabbitMQ 处理起来效率更高——CPU 上下文切换更少,内存开销也更小。因此,如果您有一个拥有数千个队列和客户端的工作负载,那么与只有少数队列和客户端相比,您将需要更大的虚拟机或更多的虚拟机才能获得相同的总吞吐量。
各种类型的“耗竭”会影响集群
- 连接耗竭(连接的打开和关闭)
- 队列和队列绑定耗竭(队列和绑定的创建和删除)
什么是高吞吐量?
每天一百万条消息听起来可能很多,但当您将其计算为每秒的速率时,它就变成了每秒略低于 12 条消息。当您的吞吐量低于每秒 100 条消息时,您很可能可以将虚拟机的大小设置得非常小。除非您有数千个队列和客户端,否则不太可能出现资源瓶颈。如果使用集群,在此速率下,它将纯粹是为了冗余而非性能。
一旦您超过每秒 1000 条消息(每天 8600 万条或每月 25 亿条),您就需要花更多时间进行容量规划分析。对于每秒 1000 条消息,您仍然可以做得非常小,但可能会出现一些资源瓶颈。
超过 10000 条(每天 8.6 亿条或每月 250 亿条), 我建议您在容量规划分析方面更加彻底。我们常说“快乐的 Rabbit 是空的 Rabbit”。当队列为空时,RabbitMQ 提供最佳的吞吐量和最低的延迟。消息是从内存中提供的,通常根本不写入磁盘。当您有大量积压消息时,消息很可能在磁盘上读/写,数据结构更大且效率较低,并且不可避免地,集群能够处理的最大吞吐量会下降。当您拥有高吞吐量集群时,积压消息可能会迅速从零增长到数百万,因此您需要确保对容量进行规划。不要只为理想情况进行规划,也要为不理想的情况进行规划。我们将在后面详细讨论这一点。
哪些工作负载需要更多内存?
经典队列和经典镜像队列会将消息保存在内存中,但在内存不足时会开始将其逐出。由于其动态行为,很难预测。一个好的做法是,如果您有非常大的队列,请使用惰性队列,因为惰性队列会很早地从内存中逐出,并且通常使用更少的内存。
默认情况下,配额队列会一直将所有消息存储在内存中,即使在内存不足的情况下也是如此。这意味着,除非您更改默认设置,否则当队列变长时,您更有可能触发内存警报(这会阻塞所有发布者)。好消息是,可以使用几个队列属性(例如 x-max-in-memory-length)来配置这一点,这些属性将一次只将此配置数量的消息保留在内存中。这可能应该设置在您所有的配额队列上。这意味着更多的消息将从磁盘读取,所以这不是免费的。
冗余如何影响容量规划?
如果您使用配额队列或镜像队列,那么每条消息都将传递给多个代理。如果您有一个包含三个代理的集群,并且配额队列的复制因子为 3,那么每个代理都将接收每条消息。在这种情况下,我们仅为了冗余而创建了集群。但我们也可以创建更大的集群以实现可伸缩性。我们可以有一个包含 9 个代理的集群,配额队列的复制因子为 3,现在我们已经分散了负载,可以处理更大的总吞吐量。
增加冗余会降低总吞吐量,因此为了抵消这一点,您可以向集群添加更多代理以分散负载。
消息大小如何影响容量规划?
小于 1kb 的小消息不太可能使网络或磁盘饱和。如果您遇到资源瓶颈,很可能是 CPU。但是,使用较大的消息大小,我们可以轻松地使网络和磁盘饱和。如果您有 1MB 的消息和 5Gbps 的网络,那么对于经典队列,您将在略高于 300 条消息/秒时使网络饱和。如果您使用配额队列或镜像队列,则会更低,因为消息不仅必须接收/发送给客户端,还要在代理之间复制。
您是否计划使用 Federation?
Federation 涉及在 RabbitMQ 代理上运行 AMQP 客户端。这意味着它们会争夺与通道和队列相同的资源。这可能意味着您需要增加虚拟机的大小/数量。还要考虑:
- 如果您对本地队列(充当发件箱)使用镜像队列,那么您将把这些出站消息复制到整个集群中。冗余是有代价的。
- 消息将通过网络传输到另一个代理,这会增加您的网络容量规划。
在您的容量规划测试中始终包含 Federation 设置。
容量规划 - AWS 案例研究
现在我们将进行一个案例研究,其中包括识别工作负载,定义我们关于端到端延迟和弹性的要求,最后是一系列测试,用于衡量不同虚拟机大小和数量是否满足这些要求。
请记住,这是一个案例研究,因此您自己的要求和工作负载可能与此非常不同。它也是一个详细的分析,适用于 RabbitMQ 是您基础设施的关键组成部分的情况,并且值得投入时间进行彻底的容量规划分析。
案例研究工作负载
在我们的案例研究中,我选择了一个中等规模、高强度的工作负载。这意味着我们有适量的队列和客户端,但要通过它们传递大量消息。
- 200 个发布者
- 100 个队列
- 200 个消费者
- 无扇出 - 使用默认交换机进行点对点通信
- 1kb 消息大小
- 每条消息处理时间 10 毫秒
- Java 客户端
- 恒定速率
我们的大部分时间都有相对稳定的 5000 条消息/秒的吞吐量,但峰值可达 20,000 条消息/秒,可持续时间从几小时到一两个小时不等。我们预计明年的流量可能会增加 10%。
我们的要求
我们希望根据峰值吞吐量再加上另外 10,000 条消息/秒来确定集群大小,以防流量意外升高,这也能覆盖预期的 10% 增长。我们不需要根据超出此范围的预期增长来确定大小,因为将来我们可以轻松升级 EC2 实例。
我们希望使用复制队列,因为这些消息对企业具有金钱价值。因此,我们将针对镜像队列和较新的配额队列进行容量规划分析。
在延迟方面,只要我们能保持在 99% 百分位端到端(从发布到消费消息的时间)低于 1 秒,我们就满意。
最后,我们希望确保即使在不利条件下(例如丢失一个代理或下游出现影响消费者吞吐量的中断)也能达到我们的吞吐量峰值。如果队列积压因为消费者运行缓慢而增长,我们希望能够吸收消息入口(保持发布速率)。发布速度减慢会给我们带来金钱损失。
测试
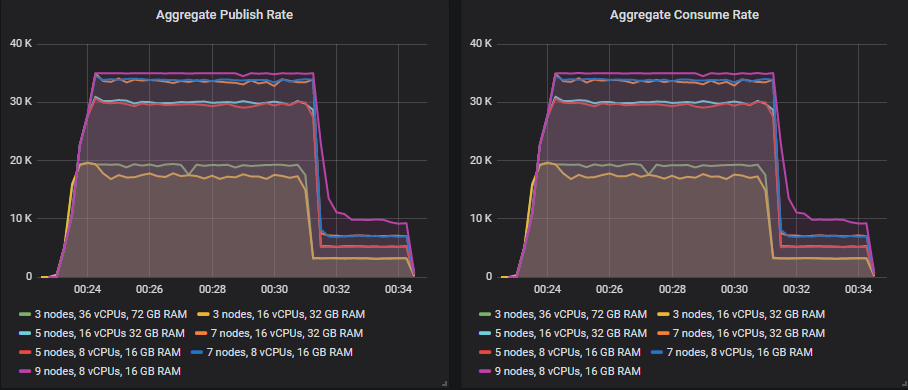
理想条件 - 强度递增测试
对于发布速率,我们将进行一系列基准测试,发布速率从 5k 到 30k 条消息/秒不等,甚至更高。目的是确定在什么速率下,选定的容量规划能提供必要的结果,以及何时会开始出现问题且不满足要求。这是理想情况,RabbitMQ 可能会保持为空(并最快)运行,因为消费者始终跟得上(直到集群达到其容量)。
我们将使用以下速率(所有发布者的总和)
- 1000 条消息/秒(每小时 360 万条,每天 8640 万条,每月 25 亿条)
- 5000 条消息/秒(每小时 1800 万条,每天 4.32 亿条,每月 129 亿条)
- 10000 条消息/秒(每小时 3600 万条,每天 8.64 亿条,每月 258 亿条)
- 15000 条消息/秒(每小时 5400 万条,每天 13 亿条,每月 389 亿条)
- ...
- 70000 条消息/秒(每小时 2.52 亿条,每天 60 亿条,每月 1814 亿条)
不利条件 - 丢失代理测试
我们将测试选定的集群大小即使在代理发生故障时也能处理峰值速率(30k 条消息/秒)。代理可能由于多种原因而发生故障:我们作为操作系统补丁安装的一部分重启机器,磁盘发生故障,网络分区等。最糟糕的情况是发生在峰值负载期间。
不利条件 - 消费速率下降,产生积压的测试
数据库服务器过载,或者下游系统出现网络延迟,或者第三方 API 运行缓慢。无论哪种情况,处理每条消息的时间从 10 毫秒增加到 30 毫秒,消费速率下降。我们能否在不受影响的情况下继续接受发布速率并吸收积压?
不利条件 - 发布速率急剧升高,超过消费者容量的测试
营销活动病毒式传播,流量远超预期,以至于我们的处理系统无法应对负载。我们能否将流量吸收为大量队列积压,以便稍后处理?
集群
集群大小和存储卷
我们在 AWS EC2 上运行,而云又是什么呢?不就是一个巨大的 API 吗?我们可以轻松地自动化创建任何大小的集群或任何我们想要的 EC2 实例类型。
我们将在 7 种不同的集群配置和三种不同的存储卷类型(io1、gp2、st1)上运行所有这些测试。
集群
- 3 个节点,c5.9xlarge,36 个 vCPU,72 GB RAM = 108 个 vCPU
- 3 个节点,c5.4xlarge,16 个 vCPU,32 GB RAM = 48 个 vCPU
- 5 个节点,c5.4xlarge,16 个 vCPU,32 GB RAM = 80 个 vCPU
- 7 个节点,c5.4xlarge,16 个 vCPU,32 GB RAM = 112 个 vCPU
- 5 个节点,c5.2xlarge,8 个 vCPU,16 GB RAM = 40 个 vCPU
- 7 个节点,c5.2xlarge,8 个 vCPU,16 GB RAM = 56 个 vCPU
- 9 个节点,c5.2xlarge,8 个 vCPU,16 GB RAM = 72 个 vCPU
c5.9xlarge 可以被认为是一个非常大的虚拟机,绝对是您可能选择的最大虚拟机。c5.4xlarge 可以被认为是大型实例,c5.2xlarge 是中型实例。这是一个相当密集的 I/O 工作负载,这就是为什么我们在分析中包含这些大型实例类型的原因。许多 I/O 强度较低的工作负载可能适用于较小的实例类型,例如 c5.xlarge(4 个 vCPU)或 c5.large。如果这些计算优化实例的内存出现问题,较大的内存实例类型(m5、r5)也是一个选择。
卷
- io1(预配 IOPS SSD),200GB,10000 IOPS,500MiB/s 最大 = 每月 725 美元
- gp2(通用 SSD),1000GB,3000 IOPS,250 MiB/s 最大 = 每月 100 美元
- st1(高吞吐量 HDD),7000GB,280 MB/s 基线,500MiB/s 最大 = 每月 315 美元
io1 的 IOPS 数量相对于其大小来说很大,价格昂贵。选择它的部分原因是为了展示更昂贵的磁盘如何在容量规划分析中发挥作用。从案例研究中您可以看到,我们可以选择 IOPS 较少的 io1,这样会更具成本效益。
我们选择了较大的 gp2,因为较小的卷会获得突发积分,这可能会让您感到意外。同样,我们选择了 7TB HDD 也是因为突发积分。此大小仍然具有突发能力,但这些工作负载不会深入利用突发能力,并且是成本的平衡(此大小可以处理 2 小时的峰值)。对于 I/O 强度较低的工作负载,我们可以选择更小的容量并节省一些钱。
这是一个使用 1TB HDD 进行的测试,其中突发积分已用完。
每月成本(按需定价)
io1 SSD
成本为:VM + 卷 = 总计
- 3 个节点,c5.9xlarge = 36 个 vCPU,每月成本 3300 美元 + 2175 美元 = 5475 美元
- 3 个节点,c5.4xlarge = 16 个 vCPU,每月成本 1468 美元 + 2175 美元 = 3643 美元
- 5 个节点,c5.4xlarge = 16 个 vCPU,每月成本 2445 美元 + 3625 美元 = 6070 美元
- 7 个节点,c5.4xlarge = 16 个 vCPU,每月成本 4123 美元 + 5075 美元 = 9198 美元
- 5 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1225 美元 + 3625 美元 = 4850 美元
- 7 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1715 美元 + 5075 美元 = 6790 美元
- 9 个节点,c5.2xlarge = 8 个 vCPU,每月成本 2205 美元 + 6525 美元 = 8730 美元
gp2 SSD
成本为:VM + 卷 = 总计
- 3 个节点,c5.9xlarge = 36 个 vCPU,每月成本 3300 美元 + 300 美元 = 3600 美元
- 3 个节点,c5.4xlarge = 16 个 vCPU,每月成本 1468 美元 + 300 美元 = 1768 美元
- 5 个节点,c5.4xlarge = 16 个 vCPU,每月成本 2445 美元 + 500 美元 = 2945 美元
- 7 个节点,c5.4xlarge = 16 个 vCPU,每月成本 4123 美元 + 700 美元 = 4823 美元
- 5 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1225 美元 + 500 美元 = 1725 美元
- 7 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1715 美元 + 700 美元 = 2415 美元
- 9 个节点,c5.2xlarge = 8 个 vCPU,每月成本 2205 美元 + 900 美元 = 3105 美元
st1 HDD
成本为:VM + 卷 = 总计
- 3 个节点,c5.9xlarge = 36 个 vCPU,每月成本 3300 美元 + 945 美元 = 4245 美元
- 3 个节点,c5.4xlarge = 16 个 vCPU,每月成本 1468 美元 + 945 美元 = 2413 美元
- 5 个节点,c5.4xlarge = 16 个 vCPU,每月成本 2445 美元 + 1575 美元 = 4020 美元
- 7 个节点,c5.4xlarge = 16 个 vCPU,每月成本 4123 美元 + 2205 美元 = 6328 美元
- 5 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1225 美元 + 1575 美元 = 2800 美元
- 7 个节点,c5.2xlarge = 8 个 vCPU,每月成本 1715 美元 + 2205 美元 = 3920 美元
- 9 个节点,c5.2xlarge = 8 个 vCPU,每月成本 2205 美元 + 2835 美元 = 5040 美元
我们不包括数据传输成本。
我们发现 gp2 对我们来说实际上是最便宜的选择。当然,st1 HDD 的每 GB 成本要低一半,但如果我们选择更小的容量,我们就无法实现更高的吞吐量。因此,对于我们的需求来说,SSD 可能是最具成本效益的选择。当然,它最多只能处理 250 MiB/s,所以如果这是限制因素,那么您将被迫选择昂贵的 io1 或 st1。
案例研究
在接下来的几篇文章中,我们将使用镜像队列和配额队列进行容量规划分析。
可能适用于您工作负载的其他测试
根据您的工作负载,您可能需要运行一些额外的测试。例如:
- 您可能希望在峰值负载下运行长时间测试。这些案例研究中的测试很短 - 在 10 分钟到 1 小时 40 分钟之间。如果您确定了特定的强度和集群配置,可以尝试运行 24 小时以确保您的选择。显然,如果您有突发网络/磁盘,这可能会在您长时间以峰值进行测试时产生影响。
- 您可能会不时收到来自批量作业的非常大的消息,您想对此进行测试。顺便说一句,我们建议使用对象存储(如 s3)来处理大消息(将 URI 作为消息传递)。
- 您可能希望通过完全停止和启动集群来测试带积压的恢复时间。
- 您可能拥有可变数量的客户端连接到您的集群。使用正常到最坏情况下的连接客户端数量来测试您的候选集群大小。
- 连接耗竭(连接的打开和关闭)也会给集群带来压力。如果您拥有可变数量的连接耗竭,请使用正常和最坏情况进行测试。另请参阅 /docs/networking.html#tuning-for-large-number-of-connections-tcp-buffer-size。
- 您可能拥有可变数量的队列。使用正常到最坏情况下的队列数量来测试您的候选集群大小。
最后的思考
您在容量规划上投入的精力可能与您在系统中有多少依赖 RabbitMQ 以及其无法提供必要性能所涉及的成本有关。如果您有一个不关键的小型工作负载,那么您可能不想在容量规划上花费太多时间。尝试几个小型选项并进行监控。
如果您拥有大型工作负载或业务关键型工作负载,那么花时间进行正确的容量规划和大小调整可能会节省您以后更多的时间和麻烦。
花时间回顾配额队列和镜像队列的案例研究,但如果您没有时间,那么这里有一些提炼到一个部分的指导方针。
高可用性(HA)是一个常见的要求,也是我们使用复制队列(配额、镜像)的原因。我们不希望丢失消息,并且即使发生故障也希望保持可用性。不要忘记,容量规划对于实现这些目标至关重要。
容量规划就是模拟您的工作负载或工作负载,在理想和不利条件下进行。峰值负载通常是企业盈利最多的时期,也是不利条件最有可能发生的时候。根据不利条件进行容量规划是正确进行容量规划的关键部分。
在适当规划的情况下,RabbitMQ 仍能有效运行的不利条件是:
- 丢失代理(磁盘故障、虚拟机重启、网络分区)
- 队列积压(由消费者减速或发布峰值引起)
- 大量 TCP 连接
- 大量队列
在这些因素中,代理丢失对 RabbitMQ 来说可能压力最小。RabbitMQ 最难处理的事情之一是巨大的队列积压。在我们的案例研究中,我们看到,通过适当的规划,RabbitMQ 尽管存在巨大的积压,但仍能处理这种高吞吐量工作负载,但前提是集群最大。较小的集群在理想条件下表现良好,但在队列开始积压时迅速恶化。
如果您已经自动化了生产和 QA 环境的部署,那么测试不同的虚拟机大小和数量应该很容易。如果您可以使用实际应用程序运行这些容量规划测试,那么可能会获得最准确的结果。如果使用自己的应用程序生成负载太困难,那么可以尝试设计一个尽可能接近真实世界的合成工作负载。
案例研究包含 PerfTest 命令,另外还有这篇文章提供了运行性能测试的指导和选项。
希望这些容量规划指南有所帮助,并能帮助 RabbitMQ 成为您架构中坚实的一部分。