Quorum Queues
概述
RabbitMQ 的 Quorum Queues 是一种现代队列类型,它实现了基于 Raft 共识算法 的持久化、复制队列,在需要复制、高可用队列时应优先考虑使用。
Quorum Queues 在设计上注重卓越的数据安全性以及可靠和快速的领导者选举特性,以确保即使在升级或其他动荡期间也能实现高可用性。
Quorum Queues 针对某些 用例 进行了优化,这些用例将 数据安全性 放在首位。这在 动机 部分进行了介绍。
Quorum Queues 在 行为上 与经典队列有所不同,并且存在一些 限制,在将应用程序从经典队列迁移到 Quorum Queues 时,了解这些限制非常重要。
某些功能是 Quorum Queues 特有的,例如 毒消息处理、至少一次死信 以及使用 AMQP 时的 modified 结果。
对于需要复制和可重复读取的场景,Streams 可能比 Quorum Queues 更好。
Quorum Queues 和 Streams 是可用的两种复制数据结构。经典队列镜像从 RabbitMQ 4.0 开始已被移除。
涵盖的主题
本文档涵盖的主题包括:
- Quorum Queues 是什么 及其引入的原因
- 它们与经典队列有何不同
- Quorum Queues 的主要 用例 以及何时不应使用它们
- 如何 声明 Quorum Queue
- 复制 相关主题:成员管理、领导者重新平衡、最佳成员数量等
- Quorum Queues 在 领导者故障处理、数据安全性 和 可用性 方面提供的保证
- 持续 成员一致性检查
- Quorum Queues 支持的附加 死信 功能
- Quorum Queues 的 内存和磁盘占用
- Quorum Queues 的 性能 特征
- Quorum Queues 的 性能调优,包括 小消息 和 大消息 的工作负载
- 毒消息处理(故障重传循环保护)
- 从镜像经典队列迁移
- 放松 属性等价性检查 的选项
- Quorum Queues 的 可配置设置
等等。
在学习 Quorum Queues 时,熟悉 RabbitMQ 集群 会很有帮助。
动机
Quorum Queues 采用了不同的复制和共识协议,并放弃了对某些“临时性”功能的 C++支持,这导致了一些限制。这些限制将在后续的信息中介绍。
Quorum Queues 通过了 重构且更具挑战性的版本 的 原始 Jepsen 测试。这确保了它们在网络分区和故障场景下的行为符合预期。新的测试会持续运行以发现可能的回归,并且会定期增强以测试新功能(例如 死信)。
什么是 Quorum?
如果故意简化,分布式系统中的 Quorum 可以定义为大多数节点之间的协议((N/2)+1,其中 N 是系统参与者的总数)。
当应用于 RabbitMQ 集群 中的队列镜像时,这意味着大多数成员(包括当前选定的队列领导者)都同意队列的状态及其内容。
用例
Quorum Queues 的预期用途是在队列存在很长时间并且对应用程序架构的某些方面至关重要的拓扑中。
好的用例示例包括销售系统中的入站订单或选举系统中投下的选票,这些情况下丢失消息可能会对整体系统正确性和功能产生重大影响。
Quorum Queues 并非为解决所有问题而设计。股票行情显示器、即时通讯系统和 RPC 回复队列使用 Quorum Queues 的收益较小或没有收益。
发布者应 使用发布者确认,因为这是客户端与 Quorum Queues 共识系统交互的方式。发布者确认 仅在 已发布的消息成功复制到 Quorum 成员后并被视为队列“安全”时才发出。
消费者应使用 手动确认,以确保未成功处理的消息被退回队列,以便另一个消费者可以重试处理。
何时不使用 Quorum Queues
在某些情况下不应使用 Quorum Queues。它们通常涉及:
- 临时队列:瞬时或独占队列,高队列周转率(声明和删除速率)
- 最低延迟:底层共识算法由于其数据安全特性而具有固有的较高延迟
- 当数据安全性不是优先事项时(例如,应用程序不使用 手动确认且未使用的发布者确认)
- 非常长的队列积压(500万+条消息)(Streams 可能是更好的选择)
- 大的扇出(fanout):(Streams 可能是更好的选择)
功能
Quorum Queues 与其他 队列 类型共享大部分基本功能。
与经典队列的比较
以下操作对于 Quorum Queues 和经典队列的工作方式相同:
某些队列操作存在细微差异:
- 声明
- 为消费者设置预取
功能矩阵
| 功能 | 经典队列 | Quorum Queues |
|---|---|---|
| 非持久化队列 | 是 | 否 |
| 消息复制 | 否 | 是 |
| 独占性 | 是 | 否 |
| 每条消息持久化 | 每条消息 | 总是 |
| 成员变更 | 否 | 半自动 |
| 消息 TTL (生存时间) | 是 | 是 |
| 队列 TTL | 是 | 部分(队列重新声明时不会续订租约) |
| 队列长度限制 | 是 | 是(除了 x-overflow:reject-publish-dlx) |
| 将消息保留在内存中 | 参见 经典队列 | 从不(参见 资源使用) |
| 消息优先级 | 是 | 是 |
| 单一活动消费者 | 是 | 是 |
| 消费者独占性 | 是 | 否(使用 单一活动消费者) |
| 消费者优先级 | 是 | 是 |
| 死信交换器 | 是 | 是 |
| 遵循 策略 | 是 | 是(参见 策略支持) |
| 毒消息处理 | 否 | 是 |
| 服务器命名的队列 | 是 | 否 |
现代 Quorum Queues 还为许多工作负载提供了 更高的吞吐量和更低的延迟变化。
队列和每条消息的 TTL
Quorum Queues 支持 队列 TTL 和消息 TTL(自 RabbitMQ 3.10 起)(包括 队列中的每队列消息 TTL 和 发布者中的每条消息 TTL)。当使用任何形式的消息 TTL 时,每条消息的内存开销会增加 2 字节。
长度限制
Quorum Queues 支持 队列长度限制。
支持 drop-head 和 reject-publish 的溢出行为,但它们不支持 reject-publish-dlx 配置,因为 Quorum Queues 的实现方法与经典队列不同。
当前 reject-publish 溢出行为的实现并不严格强制执行限制,允许 Quorum Queue 超出其限制至少一条消息,因此在需要精确限制的场景中应谨慎使用。
当 Quorum Queue 达到最大长度限制并配置了 reject-publish 时,它会通知每个发布通道,之后通道将拒绝所有消息返回给客户端。这意味着 Quorum Queues 可能会超出其限制少量的消息,因为在通道被通知时可能有消息正在传输中。接收队列的额外消息数量将根据当时正在传输的消息数量而变化。
死信
Quorum Queues 支持 通过死信交换器 (DLX) 进行死信。
传统上,在集群环境中使用的 DLX 并 不安全。
Quorum Queues 支持一种更安全的死信形式,它对队列之间的消息传输提供 至少一次 的保证(带有如下所述的限制和注意事项)。
这是通过实现一个特殊的内部死信消费者进程来实现的,该进程的工作方式类似于具有手动确认的普通队列消费者,只不过它只消费已死信的消息。
这意味着源 Quorum Queue 将保留死信消息,直到它们被确认。内部消费者将消费死信消息并使用发布者确认将它们发布到目标队列。它仅在收到发布者确认后才会确认,从而提供 至少一次 的保证。
至多一次 仍然是 Quorum Queues 的默认死信策略,适用于死信消息更具信息性质且在队列之间传输时丢失无关紧要的场景,或者在溢出配置限制不适合时。
激活至少一次死信
要激活或开启源 Quorum Queue 的 至少一次 死信,请按如下方式调整 启用死信的策略:
- 将
dead-letter-strategy设置为at-least-once(默认为at-most-once)。 - 将
overflow设置为reject-publish(默认为drop-head)。 - 配置
dead-letter-exchange - 如果
stream_queue功能标志 未启用,请启用它。
建议另外配置 max-length 或 max-length-bytes 以防止源 Quorum Queue 中消息的过度积压(参见下面的注意事项)。
可选地,配置 dead-letter-routing-key。
限制
至少一次 死信功能不适用于默认的 drop-head 溢出策略,即使未设置队列长度限制。因此,如果配置了 drop-head,死信将回退到 至多一次。请使用 reject-publish 溢出策略。
注意事项
至少一次 死信会消耗更多的系统资源,例如内存和 CPU。因此,只有在死信消息不应丢失时才应开启 至少一次。
至少一次 的保证开启了一些需要处理的特定故障情况。由于源 Quorum Queue 会保留死信消息,直到它们被死信目标队列安全接受为止,这意味着它们必须计入队列资源限制,例如最大长度限制,以便队列可以拒绝接受更多消息,直到其中一些已被移除。理论上,队列可以 *只* 包含死信消息,例如,当目标死信队列长时间不可用以接受消息,而普通队列消费者消耗了大部分消息时。
死信消息在被死信目标队列确认之前被视为“活动”消息。
在少数情况下,死信消息可能无法及时从源队列中删除:
- 配置的死信交换器不存在。
- 消息无法路由到任何队列(等同于
mandatory消息属性)。 - 一个(可能存在的多个)路由到的目标队列未确认收到消息。这可能发生在目标队列不可用时,或者目标队列拒绝消息时(例如,由于超过队列长度限制)。
死信消费者进程会定期重试上述任一情况,这意味着在 DLX 目标队列中可能会出现重复消息。
对于每个启用了 至少一次 死信的源 Quorum Queue,将有一个内部死信消费者进程。内部死信消费者进程与 Quorum Queue 领导者节点一起运行。它将所有死信消息体保留在内存中。它使用 32 条消息的预取大小来限制内存中消息体的数量,除非从目标队列收到确认。
如果需要高死信吞吐量(每秒数千条消息),可以通过 rabbit 应用部分中的 dead_letter_worker_consumer_prefetch 设置在 高级配置 文件中增加此预取大小。
对于源 Quorum Queue,可以在 至多一次 和 至少一次 之间动态切换死信策略。如果死信策略被更改,无论是直接从 至少一次 更改为 至多一次,还是间接更改(例如,将溢出从 reject-publish 更改为 drop-head),任何尚未被所有目标队列确认的死信消息都将被删除。
发布到源 Quorum Queue 的消息无论消息传递模式(瞬时或持久化)如何都会被持久化到磁盘。然而,被源 Quorum Queue 死信的消息将保留原始的消息传递模式。这意味着,如果目标队列中的死信消息应在代理重启后存活,则目标队列必须是持久化的,并且在向源 Quorum Queue 发布消息时,消息传递模式必须设置为持久化。
优先级
Quorum Queue 的优先级支持从 RabbitMQ 4.0 开始提供。但是,Quorum Queues 和经典队列实现优先级的方式有所不同。
Quorum Queues 支持 消费者优先级,并且从 4.0 版本开始,它们还支持一种与 经典队列消息优先级 非常不同的消息优先级。
Quorum Queue 的消息优先级始终处于激活状态,无需策略即可工作。一旦 Quorum Queue 接收到具有设置优先级的消息,它将启用优先级处理。
Quorum Queues 在内部只支持两种优先级:高和普通。没有设置优先级的消息将映射到普通优先级,优先级 0-4 也是如此。优先级高于 4 的消息将映射到高优先级。
高优先级消息将以 2:1 的比例优先于普通优先级消息,即每传递 2 条高优先级消息,队列将传递 1 条普通优先级消息(如果可用)。因此,Quorum Queues 实现了一种非严格的“公平份额”优先级处理。这确保了普通优先级消息始终能够取得进展,但高优先级消息的比例为 2:1。
如果一条高优先级消息先于一条普通优先级消息发布,即使轮到普通优先级了,高优先级消息也会先被传递。
更高级的场景
对于更高级的消息优先级场景,应为不同类型(优先级)的消息使用单独的队列。用于更重要消息类型的队列通常应有更多(过量配置)的消费者。
毒消息处理
Quorum Queue 支持处理 毒消息,即导致消费者反复重新排队交付的消息(可能由于消费者故障),导致消息永远无法完全被消费并 被 RabbitMQ 正面确认 以便被标记为删除。
Quorum Queues 会跟踪不成功的(重新)传递尝试次数,并在“x-delivery-count”头中公开,该头包含在任何重传的消息中。
当消息被重传的次数超过限制时,该消息将被丢弃(删除)或 死信(如果配置了 DLX)。
对于预取 (prefetch) 大于 1 的消费者,所有待处理的未确认交付都可能被此机制丢弃,如果它们因为消费者应用程序实例故障等原因被作为一个组多次重新排队。
建议所有 Quorum Queues 都配置某种死信机制,以确保消息不会被意外丢弃和丢失。使用一个单独的 Stream 来实现低优先级死信策略,是一种保留已丢弃消息一段时间的低资源方法。
从 RabbitMQ 4.0 开始,Quorum Queues 的传递限制默认为 20。
可以通过在声明队列时设置 x-delivery-limit=-1 可选参数 来恢复 3.13.x 版本中没有限制的行为。
有关更多详细信息,请参阅 重复重排。
配置限制
可以使用 策略 参数 delivery-limit 为队列设置传递限制。
值 -1(禁用限制)目前无法通过策略设置 - 只能在队列声明时使用 x-delivery-limit=-1 队列参数进行设置。
覆盖限制
以下示例将限制设置为 50,适用于名称以 qq 开头的队列。
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\." '{"delivery-limit": 50}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\." "{""delivery-limit"": 50}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.",
"definition": {"delivery-limit": 50},
"priority": 1,
"apply-to": "quorum_queues"}
导航到
Admin>Policies>Add / update a policy。在 Name 旁输入策略名称(例如“qq-overrides”),在 Pattern 旁输入模式(例如“^qq.”),然后使用
Apply to下拉菜单选择策略应应用于的实体类型(本例中为 quorum queues)。在
Policy旁的第一行中,将“delivery-limit”作为策略参数,将 50 作为其值。点击
Add policy。
禁用限制
以下示例为名称以 qq.unlimited 开头的队列禁用限制。
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\.unlimited" '{"delivery-limit": -1}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\.unlimited" "{""delivery-limit"": -1}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.unlimited",
"definition": {"delivery-limit": -1},
"priority": 1,
"apply-to": "quorum_queues"}
导航到
Admin>Policies>Add / update a policy。在 Name 旁输入策略名称(例如“qq-overrides”),在 Pattern 旁输入模式(例如“^qq.unlimited”),然后使用
Apply to下拉菜单选择策略应应用于的实体类型(本例中为 quorum queues)。在
Policy旁的第一行中,将“delivery-limit”作为策略参数,将 -1 作为其值。点击
Add policy。
配置限制并设置死信
重传次数超过限制的消息将被丢弃(删除)或 死信。
以下示例配置了限制和一个用于死信(重新发布)此类消息的交换器。本示例中的目标交换器名为“redeliveries.limit.dlx”。声明它并设置其拓扑(绑定队列和/或 Streams)不在此示例中。
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\." '{"delivery-limit": 50, "dead-letter-exchange": "redeliveries.limit.dlx"}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\." "{""delivery-limit"": 50, ""dead-letter-exchange"": ""redeliveries.limit.dlx""}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.",
"definition": {"delivery-limit": 50, "dead-letter-exchange": "redeliveries.limit.dlx"},
"priority": 1,
"apply-to": "quorum_queues"}
导航到
Admin>Policies>Add / update a policy。在 Name 旁输入策略名称(例如“qq-overrides”),在 Pattern 旁输入模式(例如“^qq.”),然后使用
Apply to下拉菜单选择策略应应用于的实体类型(本例中为 quorum queues)。在
Policy旁的第一行中,将“delivery-limit”作为策略参数,将 50 作为其值,然后将“dead-letter-exchange”作为第二个键,将“redeliveries.limit.dlx”作为其值。点击
Add policy。
要了解更多关于死信的信息,请查阅其 专门指南。
策略支持
Quorum Queues 可以通过 RabbitMQ 策略进行配置。下表总结了它们遵守的策略键。
| 定义键 | 类型 |
|---|---|
max-length | 数字 |
max-length-bytes | 数字 |
overflow | “drop-head”或“reject-publish” |
expires | 数字(毫秒) |
dead-letter-exchange | 字符串 |
dead-letter-routing-key | 字符串 |
delivery-limit | 数字 |
不支持的功能
临时(非持久化)队列
经典队列可以是 非持久化 的。Quorum Queues 始终是持久化的,这与其假定的 用例 相符。
独占性
独占队列 与其声明连接的生命周期相关联。Quorum Queues 本质上是复制和持久化的,因此独占属性在它们的上下文中没有意义。因此,Quorum Queues 不能是独占的。
Quorum Queues 不打算用作 临时队列。
全局 QoS
Quorum Queues 不支持全局 QoS 预取,即通道为使用该通道的所有消费者设置一个预取限制。如果尝试从具有全局 QoS 激活的通道的 Quorum Queue 进行消费,将返回通道错误。
请使用 每消费者 QoS 预取,这是许多流行客户端中的默认设置。
用法
Quorum Queues 与其他 队列 类型共享大部分基本功能。任何能够指定 可选队列参数 的 AMQP 0.9.1 客户端库在声明时都可以使用 Quorum Queues。
首先,我们将介绍如何使用 AMQP 0.9.1 声明 Quorum Queue。
声明
要声明 Quorum Queue,请将 x-queue-type 队列参数设置为 quorum(默认值为 classic)。此参数必须由客户端在队列声明时提供;不能使用 策略 设置或更改。这是因为策略定义或适用的策略可以动态更改,但队列类型不能。它必须在声明时指定。
声明一个 x-queue-type 参数设置为 quorum 的队列将声明一个最多包含三个成员的 Quorum Queue(默认 复制因子),每个成员对应一个 集群节点。
例如,一个包含三个节点的集群将有三个成员,每个节点一个。在包含五个节点的集群中,三个节点将各有一个副本,而两个节点将不托管任何成员。
声明后,Quorum Queue 可以像其他任何 RabbitMQ 队列一样绑定到任何交换器。
如果使用 管理 UI 进行声明,则必须使用队列类型下拉菜单指定队列类型。
客户端操作
以下操作对于 Quorum Queues 和经典队列的工作方式相同:
某些队列操作存在细微差异:
复制因子和成员管理
声明 Quorum Queue 时,必须在集群中启动其初始数量的成员。默认情况下,启动的成员数量最多为三个,每个 RabbitMQ 节点一个。
三个节点是 Quorum Queue 的 **实际最小** 成员数。在拥有更多节点的 RabbitMQ 集群中,添加超过 Quorum(多数)的成员数量不会在 Quorum Queue 可用性 方面带来任何改进,但会消耗更多集群资源。
因此,Quorum Queue 的 **推荐成员数量** 是集群节点的 Quorum(但不少于三个)。这假设一个 完全形成的 至少三个节点的集群。
控制初始复制因子
例如,一个包含三个节点的集群将有三个成员,每个节点一个。在包含七个节点的集群中,三个节点将各有一个副本,而另外四个节点将不托管新声明队列的任何成员。
Quorum Queues 的复制因子(队列拥有的成员数量)是可配置的。
实际有意义的最小因子值为三个。强烈建议因子为奇数。这样可以计算出明确的节点 Quorum(多数)。例如,在两个节点的集群中不存在“多数”。这将在 容错和最少在线副本数 部分提供更多示例。
这可能不适用于大型集群或偶数个节点的集群。要控制 Quorum Queue 成员数量,请在声明队列时设置 x-quorum-initial-group-size 队列参数。提供的组大小参数应为一个大于零且小于等于当前 RabbitMQ 集群大小的整数。Quorum Queue 将在声明时在集群中存在的 RabbitMQ 节点的一个随机子集上启动。
如果 Quorum Queue 在所有集群节点加入集群之前被声明,并且初始副本计数大于集群成员总数,则实际使用的值将等于集群节点总数。当更多节点加入集群时,副本计数不会自动增加,但可以 由操作员增加。
管理成员
Quorum Queue 的副本由操作员显式管理。当向集群添加新节点时,除非操作员显式将其添加到 Quorum Queue 或一组 Quorum Queues 的成员(副本)列表中,否则它不会托管任何 Quorum Queue 成员。
当节点需要退役(永久从集群中移除)时,forget_cluster_node 命令将自动尝试移除退役节点上的所有 Quorum Queue 成员。或者,可以使用下面的 shrink 命令在节点移除之前将任何成员移到新节点。
另请参阅 持续成员一致性检查,了解更自动化的 Quorum Queues 增长方式。
提供了几个 CLI 命令 来执行上述操作:
rabbitmq-queues add_member [-p <vhost>] <queue-name> <node>
rabbitmq-queues delete_member [-p <vhost>] <queue-name> <node>
rabbitmq-queues grow <node> <all | even> [--vhost-pattern <pattern>] [--queue-pattern <pattern>]
rabbitmq-queues shrink <node> [--errors-only]
要成功添加和删除成员,队列中必须有 Quorum 成员可用,因为成员变更被视为队列状态变更。
在执行涉及成员变更的维护操作时,需要小心,以免因在操作过程中丢失 Quorum 而意外导致队列不可用。
替换集群节点时,更安全的方法是先添加一个新节点,然后增长任何需要在新节点上拥有成员的 Quorum Queues,最后退役要替换的节点。
队列领导者位置
每个 Quorum Queue 都有一个主副本。该副本称为 *队列领导者*。所有队列操作首先通过领导者,然后复制到跟随者。这是保证消息 FIFO 顺序所必需的。
为避免集群中的某些节点托管大部分队列领导者成员并处理大部分负载,队列领导者应在集群节点之间相对均匀地分布。
当声明一个新的 Quorum Queue 时,将随机选择托管其成员的节点集,但始终包括声明该队列的客户端连接到的节点。
初始领导者副本可以通过三个选项进行控制:
- 设置
queue-leader-locator策略 键(推荐) - 通过在 配置文件 中定义
queue_leader_locator键(推荐) - 使用
x-queue-leader-locator可选队列参数
支持的队列领导者定位器值包括:
client-local:选择声明该队列的客户端所连接的节点。这是默认值。balanced:如果总共有少于 1000 个队列(经典队列、Quorum Queues 和 Streams),则选择托管最少 Quorum Queue 领导者的节点。如果总共有超过 1000 个队列,则选择一个随机节点。
重新平衡副本
声明后,RabbitMQ Quorum Queue 的领导者可能在 RabbitMQ 集群中分布不均。要重新平衡,请使用 rabbitmq-queues rebalance 命令。重要的是要了解,这不会改变 Quorum Queues 跨越的节点。要修改成员关系,请参阅 管理成员。
# rebalances all quorum queues
rabbitmq-queues rebalance quorum
可以按名称选择一部分队列进行重新平衡
# rebalances a subset of quorum queues
rabbitmq-queues rebalance quorum --queue-pattern "orders.*"
或者特定虚拟主机中的 Quorum Queues
# rebalances a subset of quorum queues
rabbitmq-queues rebalance quorum --vhost-pattern "production.*"
持续成员一致性检查 (CMR)
持续成员一致性检查 (CMR) 功能是显式副本管理(explicit replica management)的补充,而非替代。在某些节点被永久从集群中移除的情况下,显式移除 Quorum Queue 成员可能仍然是必要的。
除了通过初始目标大小和 显式副本管理 来控制 Quorum Queue 副本成员关系之外,还可以通过启用持续成员一致性检查功能,将节点配置为自动尝试将 Quorum Queue 副本成员关系扩展到配置的目标组大小。
激活后,每个 Quorum Queue 领导者副本将定期检查其当前的成员组大小(配置成员的数量)并将其与目标值进行比较。
如果队列小于目标值,RabbitMQ 将尝试在当前未托管该队列成员的可用节点上(如果有)增长队列,直到达到目标值。
何时触发持续成员一致性检查?
默认的检查间隔为 60 分钟。此外,自动检查会由集群中的某些事件触发,例如添加新节点、永久移除节点或 Quorum Queue 相关策略的更改。
请注意,节点或 Quorum Queue 副本的故障不会触发自动成员检查。
如果节点发生不可恢复的故障并且无法恢复,则必须将其从集群中显式移除,或者操作员必须选择启用 quorum_queue.continuous_membership_reconciliation.auto_remove 设置。
这也意味着 升级 不会触发自动成员检查,因为节点预计会恢复,并且一次只停止少数(通常只有一个)节点进行升级。
CMR 配置
通过 rabbitmq.conf
rabbitmq.conf 配置键 | 描述 |
|---|---|
| 启用或禁用持续成员一致性检查。
|
| 队列成员的目标副本计数(组大小)。
|
| 启用或禁用自动移除不再属于集群但仍是 Quorum Queue 成员的成员节点。
|
| 默认评估间隔(毫秒)。
|
| 触发事件(例如,集群中添加或删除节点,或适用策略更改)发生时使用的检查延迟(毫秒)。此延迟仅应用一次,然后将再次使用常规间隔。
|
策略键
| 策略键 | 描述 |
|---|---|
| 定义匹配队列的目标副本计数(组大小)。此策略可由用户和操作员设置。
|
| 可选参数键 | 描述 |
|---|---|
| 定义匹配队列的目标副本计数(组大小)。此键可由操作员策略覆盖。
|
Quorum Queue 行为
Quorum Queue 依赖于名为 Raft 的共识协议来确保数据一致性和安全性。
每个 Quorum Queue 都有一个主副本(在 Raft 术语中称为*领导者*)和零个或多个次要成员(称为*跟随者*)。
当集群首次形成或领导者变得不可用时,会选举出领导者。
领导者选举和故障处理
Quorum Queue 需要其声明节点的 Quorum 可用才能运行。当托管 Quorum Queue *领导者* 的 RabbitMQ 节点发生故障或停止时,托管该 Quorum Queue *跟随者* 的另一个节点将被选为领导者并恢复操作。
失败并重新加入的跟随者将与领导者重新同步(“赶上”)。对于 Quorum Queues,临时副本故障不需要与当前选定的领导者进行完全同步。如果重新加入的副本落后于领导者,则只传输增量。这个“赶上”过程不会影响领导者的可用性。
当 添加 新副本时,它将从领导者同步整个队列状态。
容错和最少在线副本数
共识系统可以提供关于数据安全的某些保证。这些保证确实意味着在它们变得相关之前需要满足某些条件,例如需要最少三个集群节点来提供容错,并要求超过一半的成员可用才能正常工作。
各种规模集群的容错特性可以用表格描述:
| 集群节点数 | 可容忍的节点故障数 | 容忍网络分区 |
|---|---|---|
| 1 | 0 | 不适用 |
| 2 | 0 | 否 |
| 3 | 1 | 是 |
| 4 | 1 | 如果一侧存在多数则可以 |
| 5 | 2 | 是 |
| 6 | 2 | 如果一侧存在多数则可以 |
| 7 | 3 | 是 |
| 8 | 3 | 如果一侧存在多数则可以 |
| 9 | 4 | 是 |
如上表所示,少于三个节点的 RabbitMQ 集群不能充分受益于 Quorum Queue 的保证。偶数个 RabbitMQ 节点的集群在将 Quorum Queue 成员分布在所有节点上时没有优势。对于这些系统,Quorum Queue 的大小应限制在较小的奇数节点数量上。
Quorum Queue 节点数量超过 5 个时,性能会显著下降。我们不建议在超过 7 个 RabbitMQ 节点上运行 Quorum Queues。默认的 Quorum Queue 大小为 3,可以通过 x-quorum-initial-group-size 队列参数 进行控制。
数据安全性
Quorum Queues 的设计目的是在网络分区和故障场景下提供数据安全性。只要托管 Quorum Queue 的大多数 RabbitMQ 节点没有永久不可用,那么使用 发布者确认 功能成功确认给发布者的消息就不应丢失。
通常,Quorum Queues 倾向于数据一致性而不是可用性。
Quorum Queues 无法为尚未 确认给发布者 的消息提供任何安全保证。这些消息可能会“在传输中”丢失,在操作系统缓冲区中,或者未能到达目标节点或队列领导者。
可用性
Quorum Queue 应该能够容忍少数队列成员不可用,而对可用性没有或只有很小的影响。
请注意,根据使用的 分区处理策略,RabbitMQ 在恢复过程中可能会自行重启并重置节点,但只要不发生这种情况,这种可用性保证就应该有效。
例如,一个拥有三个成员的队列可以容忍一次节点故障而不会丢失可用性。拥有五个成员的队列可以容忍两次,依此类推。
如果无法恢复 Quorum 节点(例如,如果 3 个 RabbitMQ 节点中有 2 个永久丢失),则队列将永久不可用,需要强制删除并重新创建。
断开与领导者连接或参与领导者选举的 Quorum Queue 跟随者成员将忽略发送给它的队列操作,直到它们得知新的领导者。在这种情况下,日志中会出现警告(received unhandled msg 等)。一旦副本发现新的领导者,它将同步它没有的来自领导者的队列操作日志条目,包括丢弃的条目。因此,Quorum Queue 的状态将保持一致。
性能特征
Quorum Queues 在 RabbitMQ 4.1.x 中得到了进一步优化,现在 具有更低的内存占用和更高的消费者传递率,以及在高峰负载下的并行处理能力。
Quorum Queues 的设计目的是在延迟和吞吐量之间进行权衡,并已在具有不同消息大小的 3、5 和 7 节点配置中进行了测试。
在使用消费者确认和发布者确认的场景中,Quorum Queues 的吞吐量优于经典镜像队列(2021 年弃用,2024 年 RabbitMQ 4.0 中移除)。例如,请查看 3.10 的基准测试 和 3.12 的另一个基准测试。
由于 Quorum Queues 在执行任何操作之前都会将所有数据持久化到磁盘,因此建议使用最快的磁盘以及某些 性能调优 设置。
Quorum Queues 还受益于消费者使用更高的预取值,以确保消费者在确认信息流经系统时不会被饿死,并允许消息及时传递。
由于 Quorum Queues 的磁盘 I/O 密集型特性,其吞吐量随着消息大小的增加而降低。
Quorum Queue 的吞吐量也受成员数量的影响。Quorum Queue 的成员越多,其吞吐量通常越低,因为需要更多的工作来复制数据和达成共识。
使用蓝绿部署从 RabbitMQ 3.13.x 的镜像经典队列迁移到 Quorum Queues
rabbitmqadmin v2 提供了使用 蓝绿部署策略 自动从使用经典镜像队列的 3.13.x 集群迁移到 Quorum Queues 的命令。
请参阅 使用蓝绿升级策略从经典镜像队列迁移到 Quorum Queues。
可配置设置
可以使用 高级 配置文件调整几个新的配置参数。
请注意,所有与 资源占用 相关的设置都记录在单独的部分。
ra 应用程序(Quorum Queues 使用的 Raft 库)具有 其自身的参数。
rabbit 应用程序具有几个与 Quorum Queues 相关的可用配置项。
advanced.config 配置键 | 描述 | 默认值 |
|---|---|---|
| rabbit.quorum_cluster_size | 设置默认的 Quorum Queue 集群大小(可在声明时通过 | 3 |
| rabbit.quorum_commands_soft_limit | 这是一个流量控制相关的参数,定义了通道在进入流量控制状态之前的最大未确认消息数。当前默认值旨在为多个发布者发送到同一 Quorum Queue 提供良好的性能和稳定性。如果应用程序通常只有一个发布者,则可以增加此限制以提供稍好的入口速率。 | 32 |
Quorum Queue 配置示例
以下 rabbitmq.conf 示例修改了上面列出的所有值:
quorum_queue.initial_cluster_size = 3
quorum_queue.commands_soft_limit = 32
放松属性等价性检查的选项
当客户端重新声明队列时,RabbitMQ 节点会 执行属性等价性检查。如果某些属性不相等,声明将以 通道错误 失败。
在应用程序通过 x-queue-type 参数显式设置队列类型但无法快速更新和/或重新部署的环境中,可以通过一个选择加入的设置来忽略 x-queue-type 的等价性检查。
quorum_queue.property_equivalence.relaxed_checks_on_redeclaration = true
如果 quorum_queue.property_equivalence.relaxed_checks_on_redeclaration 设置为 true,则在队列重新声明时将忽略“x-queue-type”头(不进行等价性比较)。
这可以简化应用程序的升级,这些应用程序出于历史原因显式设置“x-queue-type”为“classic”,但未设置任何可能冲突或显著改变队列行为和语义的其他属性,例如 'exclusive' 字段。
资源使用
Quorum Queues 在 RabbitMQ 4.1.x 中得到了进一步优化,现在 具有更低的内存占用和更高的消费者传递率,以及在高峰负载下的并行处理能力。
Quorum Queues 针对数据安全和性能进行了优化。每个 Quorum Queue 进程维护一个内存中的队列消息索引,每个消息至少需要 32 字节的元数据(如果消息被退回或设置了 TTL,则需要更多)。因此,一个 Quorum Queue 进程每 30000 条消息至少会使用 1MB(消息大小无关紧要)。您可以根据队列数量和预期或最大消息数量进行估算)。保持队列简短是维持低内存使用的最佳方式。设置最大队列长度 是限制总内存使用量的好方法,以防队列因任何原因变长。
内存、WAL 和段文件如何交互
给定节点上的 Quorum Queues 共享一个用于所有操作的写前日志 (WAL)。WAL 包含队列上近期操作的有限数量。WAL 条目同时存储在内存中并写入磁盘。当当前 WAL 文件达到预定义限制时,它将被刷新到每个 Quorum Queue 成员在节点上的段文件中,系统将开始释放该批日志条目使用的内存。
然后,随着消费者 确认传递,段文件会随着时间被压缩。压缩是回收磁盘空间的进程。
WAL 文件大小限制(在此之后将其刷新到磁盘)是可控的:
# Flush current WAL file to a segment file on disk once it reaches 64 MiB in size
raft.wal_max_size_bytes = 64000000
默认值为 512 MiB。这意味着在稳定负载下,WAL 表的内存占用可能达到 512 MiB。
由于内存不保证会被 运行时 立即释放,我们建议为 RabbitMQ 节点分配至少是有效 WAL 文件大小限制 3 倍的内存。高吞吐量系统需要更多。对于这些系统,4 倍是一个不错的起点。
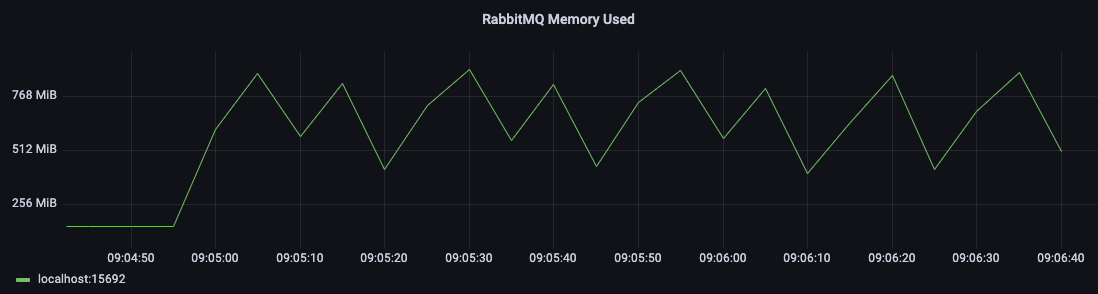
Quorum Queues 的内存占用模式通常如下所示:
磁盘空间
在 Quorum Queues 使用量大和/或大消息在其之间流动的情况下,超额配置磁盘空间(即拥有额外的可用容量)非常重要。这遵循了现代发布系列 存储的通用建议。
对于大消息(例如,1 MiB 及以上),Quorum Queue 的磁盘占用可能很大。根据工作负载,特别是待 消费者确认 的消息数量,段文件的移除可能会很慢,导致磁盘占用不断增长。
这导致了几个建议:
- 在 Quorum Queues 使用量大和/或大消息在其之间流动的情况下,超额配置磁盘空间(即拥有额外的可用容量)非常重要。
- Quorum Queues 严重依赖消费者及时确认消息,因此必须使用 相对较低的传递确认超时。
- 对于较大的消息,减小每个段文件的条目数 可能有助于减小段文件的大小,并允许更频繁地截断(删除)这些文件。
- 较大的消息可以存储在 blob 存储中作为替代,并将相关元数据传递在 Quorum Queues 中流动的消息中。
何时发生段文件截断?
段文件截断会定期发生,以响应客户端操作,当可以安全地进行时。Quorum Queues 会定期进行检查点和快照,并截断已知不再包含“活动”(可供传递或等待消费者确认)消息的段文件。
当没有客户端活动时,这些事件不会发生,段文件截断也不会发生。如果一个队列完全空闲且为空,但有大量来自早期高峰活动的磁盘段文件,确保队列为空然后 **清除它** 可能有助于强制进行段文件截断。
要清除队列,请使用:
- 使用管理 UI 队列页面上的
Purge Messages按钮 - 使用 AMQP 0-9-1 时,
queue.purge操作,在大多数 AMQP 0-9-1 客户端库中通过类似名称的函数或方法公开。 - 使用 AMQP 1.0 时,Team RabbitMQ 维护的 AMQP 1.0 客户端库中具有类似名称的函数或方法。
请注意,清除具有未确认交付的队列不会对所有段文件产生期望的效果,甚至可能没有任何效果。
重复重排的交付(传递-重排循环)
内部 Quorum Queues 使用日志实现,其中所有操作(包括消息)都会被持久化。为了避免此日志过大,需要定期截断。要截断日志的一部分,该部分中的所有消息都需要被确认。持续 拒绝或 nack 同一条消息并设置 requeue 标志为 true 的使用模式可能导致日志无界增长,并最终填满磁盘。因此,自 RabbitMQ 4.0 起,默认始终设置 delivery-limit 为 20,之后消息将被丢弃或死信。
如果消息被拒绝或 nack 回 Quorum Queue,并且没有设置 delivery-limit,它们将被返回到队列的 **末尾**。这可以避免上述日志无界增长的场景。如果设置了 delivery-limit,它将使用原始行为,将消息返回到队列的头部附近。
可以通过在队列参数或策略中将传递限制设置为 -1 来恢复旧的无限制传递限制行为。不建议这样做,但在某些罕见情况下,为了与 3.13.x 兼容可能需要。
增加原子(Atom)的使用量
仲裁队列(quorum queues)的内部实现会将队列名称转换为 Erlang 原子。如果不断创建和删除任意名称的队列,当原子表的大小达到默认的 500 万的限制时,可能会威胁到 RabbitMQ 系统的长期稳定性。
虽然仲裁队列并非为高吞吐量(high churn)环境而设计(非镜像的经典队列是最佳选择),但如果确实有必要,也可以增加该限制。
请参阅运行时指南以了解更多信息。
性能调优
Quorum Queues 在 RabbitMQ 4.1.x 中得到了进一步优化,现在 具有更低的内存占用和更高的消费者传递率,以及在高峰负载下的并行处理能力。
本节旨在介绍几个可调参数,这些参数可以提高仲裁队列在某些工作负载下的吞吐量。其他工作负载可能不会看到任何提升,甚至会观察到吞吐量下降。
将此处的值和建议作为起点,并进行自己的基准测试(例如,使用 PerfTest),以确定最适合特定工作负载的参数组合。
调优:Raft 段文件条目数
针对小消息
具有小消息和更高消息速率的工作负载可以受益于以下配置更改,该更改增加了允许存储在段文件中的 Raft 日志条目(例如,已入队的消息)的数量。
当从具有长积压(long backlog)的队列消费时,拥有更少的段文件是有益的。
# Positive values up to 65535 are allowed, the default is 4096.
# This value is reasonable for workloads with small (say, smaller than 8 kiB) messages
raft.segment_max_entries = 32768
值大于 65535 的情况不受支持。
针对大消息
具有大消息(100KB 甚至几 MB)的工作负载将受益于以下配置更改,该更改显著减少了允许存储在段文件中的 Raft 日志条目(例如,已入队的消息)的数量。
每个段文件具有显著更少的条目将使每个段文件的大小保持合理,并允许节点以更高的速率截断它们,因为每个段文件包含少量活动消息的可能性较低,而这些活动消息会使整个文件保留。
作为估算,考虑一个工作负载,它入队 4096 条每条 1MB 的消息。这将导致一个大小超过 4GB 的段文件,并且只要其中至少有一条消息处于活动状态(未被传递和确认),整个文件就无法删除。
例如,允许每个段文件只有 128 个条目
# The default is 4096.
# This value is only reasonable for workloads with messages of 1 MiB or even larger
raft.segment_max_entries = 128
调优:Linux 预读(Readahead)
此外,前面提到的具有更高速率小消息的工作负载可以受益于更高的 readahead,这是 Linux 上存储设备的配置块设备参数。
要检查有效的 readahead 值,请使用 blockdev --getra 并指定托管 RabbitMQ 节点数据目录的块设备。
# This is JUST AN EXAMPLE.
# The name of the block device in your environment will be different.
#
# Displays effective readahead value device /dev/sda.
sudo blockdev --getra /dev/sda
要配置 readahead,请使用 blockdev --setra 为托管 RabbitMQ 节点数据目录的块设备设置。
# This is JUST AN EXAMPLE.
# The name of the block device in your environment will be different.
# Values between 256 and 4096 in steps of 256 are most commonly used.
#
# Sets readahead for device /dev/sda to 4096.
sudo blockdev --setra 4096 /dev/sda