RabbitMQ 3.10 性能改进

RabbitMQ 3.10 已于 2022 年 5 月 3 日发布,具有许多新功能和改进。本文概述了该版本中的性能改进。简而言之,您可以期待更高的吞吐量、更低的延迟和更快的节点启动速度,尤其是在启动时导入大型定义文件的情况下。
概述
首先,请参阅3.10 版本概述博客文章,了解该版本的新功能概览。在这里,我们将仅关注性能改进和具有性能影响的功能。此处介绍的一些改进已向后移植到 3.9.x 版本,因此为了演示差异,我们将使用 3.9.0 作为参考点。
如果您暂时无法升级到 3.10,请确保您至少运行最新的 3.9.x 补丁版本,以利用这些优化。
RabbitMQ 3.9 vs 3.10
让我们在几种不同的场景下比较 RabbitMQ 3.9 和 3.10。请牢记,这些是特定的基准测试,可能反映您的工作负载的性质和性能,也可能不反映。
您可以使用 RabbitMQ 负载测试工具 perf-test 和 stream-perf-test 自己运行这些或类似的测试。
环境
这些测试是使用以下环境执行的:
- 一个带有 e2-standard-16 节点的 GKE 集群
- 使用我们的 Kubernetes Operator 部署的 RabbitMQ 集群,具有以下资源和配置:
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: ...
spec:
replicas: 1 # or 3
image: rabbitmq:3.10.1-management # or rabbitmq:3.9.0-management
resources:
requests:
cpu: 8
memory: 16Gi
limits:
cpu: 8
memory: 16Gi
persistence:
storageClassName: premium-rwo
storage: "3000Gi"
rabbitmq:
advancedConfig: |
[
{rabbit, [
{credit_flow_default_credit,{0,0}}
]}
].
关于环境的一些说明
- 对于许多测试(甚至生产工作负载),这些资源设置都是过度的。然而,这是我们团队在 RabbitMQ 负载测试中的标准配置。
- 您应该能够使用更好的硬件(包括 Google Cloud)达到更高的值。
- 信用流已禁用,因为否则单个快速发布者会被限制(以防止过载并给其他发布者公平的机会),这在生产环境中是正确的做法,但在服务器负载测试中没有意义。
场景 1:一个队列,快速发布者和消费者
在第一个场景中,我们将只使用 1 个队列,带有 2 个发布者和 2 个消费者。我们将测试消息大小为 10、100、1000 和 5000 字节。
我们使用 2 个发布者,因为在某些配置下,单个发布者无法完全利用队列,尤其是在消息非常小的情况下。请注意,RabbitMQ 3.11(当前在 master 分支)已有一些路由效率改进,因此未来的版本可能不会出现这种情况。
在此工作负载中使用了以下 perf-test 标志:
# classic queues (with an exactly=3 mirroring policy where applicable)
perf-test --producers 2 --consumers 2 --confirm 3000 --multi-ack-every 3000 --qos 3000 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--auto-delete false --flag persistent --queue cq
# quorum queues
perf-test --producers 2 --consumers 2 --confirm 3000 --multi-ack-every 3000 --qos 3000 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--quorum-queue --queue qq
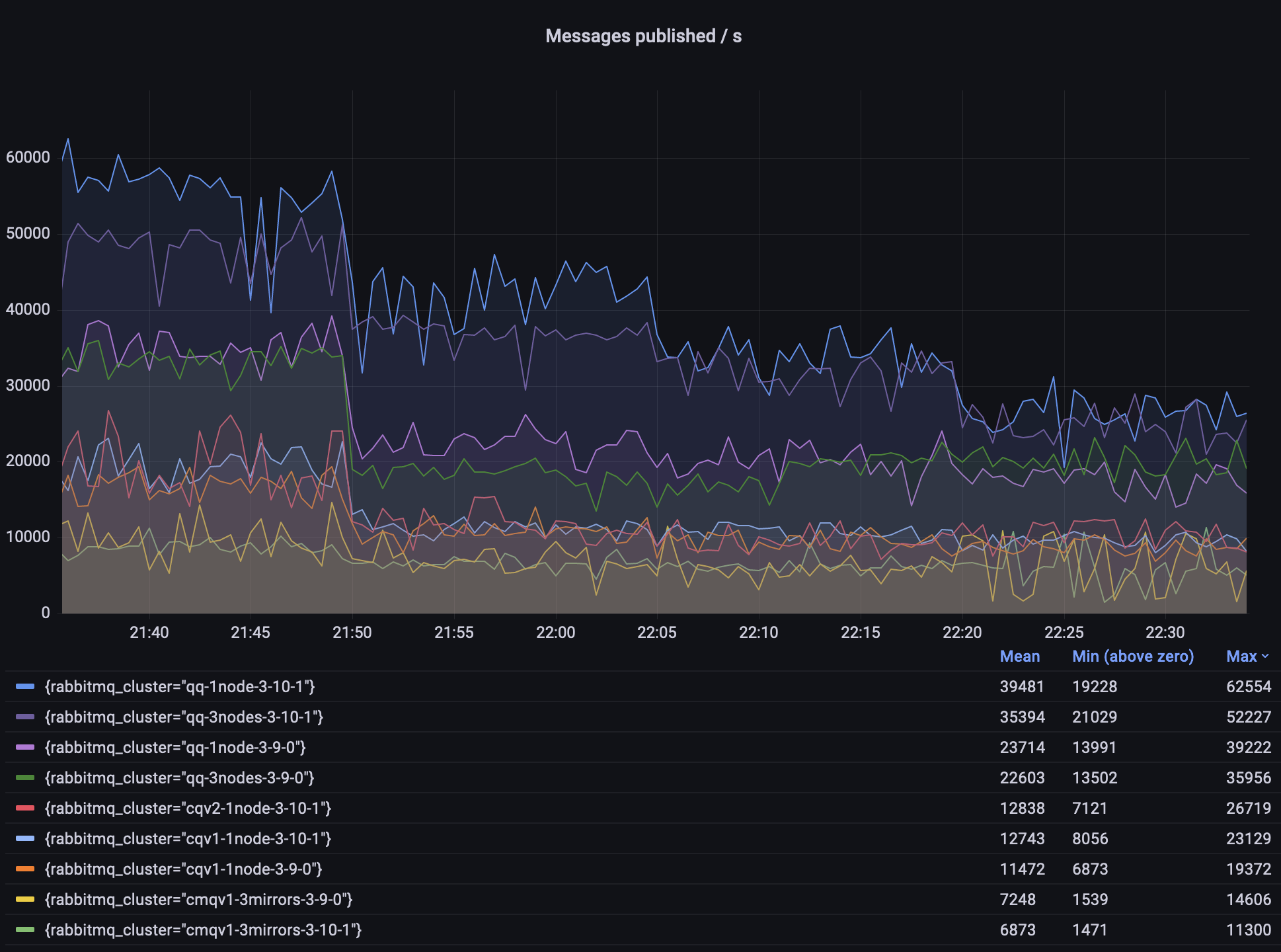
观察结果
- 仲裁队列 (quorum queues) 的吞吐量是经典镜像队列 (CMQs) 的几倍。
- 在某些场景下,3.10 的仲裁队列吞吐量可以提高 50%。
- 在某些场景下,经典队列 v2 比 v1 稍好。
- CMQ 未获得任何新改进,将在 RabbitMQ 4.0 中删除;请根据需要迁移到仲裁队列、流 (streams) 或非镜像经典队列。
场景 2:一个队列,10000 条消息/秒
在之前的场景中,RabbitMQ 中的一些代码路径始终以最大速度或接近最大速度运行。这次,我们将设置一个固定的目标吞吐量为 10000 条消息/秒,并随着消息大小的增加来比较不同环境是否能维持此工作负载。
由于预期的吞吐量是已知的,我们将重点测量延迟及其变化。
在此场景中使用了以下 perf-test 标志:
# classic queues (with an exactly=3 mirroring policy where applicable)
perf-test --rate 10000 --confirm 3000 --multi-ack-every 3000 --qos 3000 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--auto-delete false --flag persistent --queue cq
# quorum queues
perf-test --rate 10000 --confirm 3000 --multi-ack-every 3000 --qos 3000 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--quorum-queue --queue qq
再次,仲裁队列自信地超越了经典镜像队列 (CMQs)。
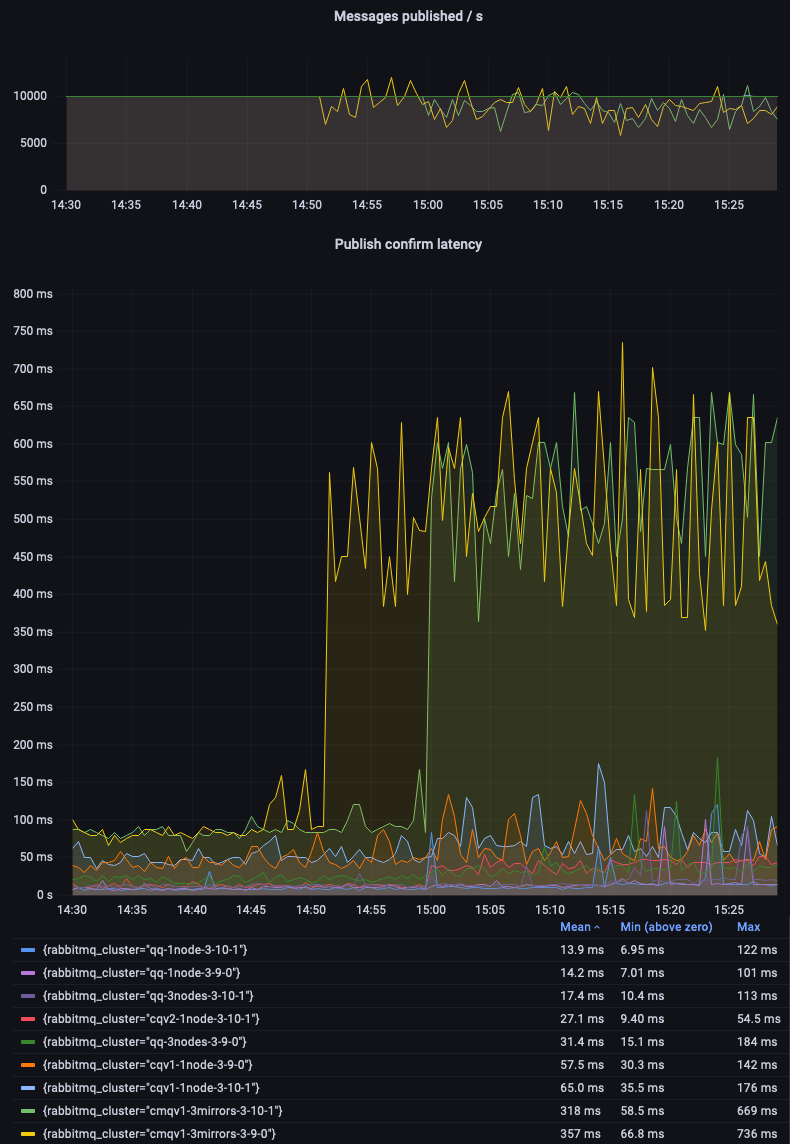
让我们深入研究非镜像经典队列,以比较 v1 和 v2 的消息存储和队列索引实现。我们可以看到 CQv2 提供更低且更一致的延迟。
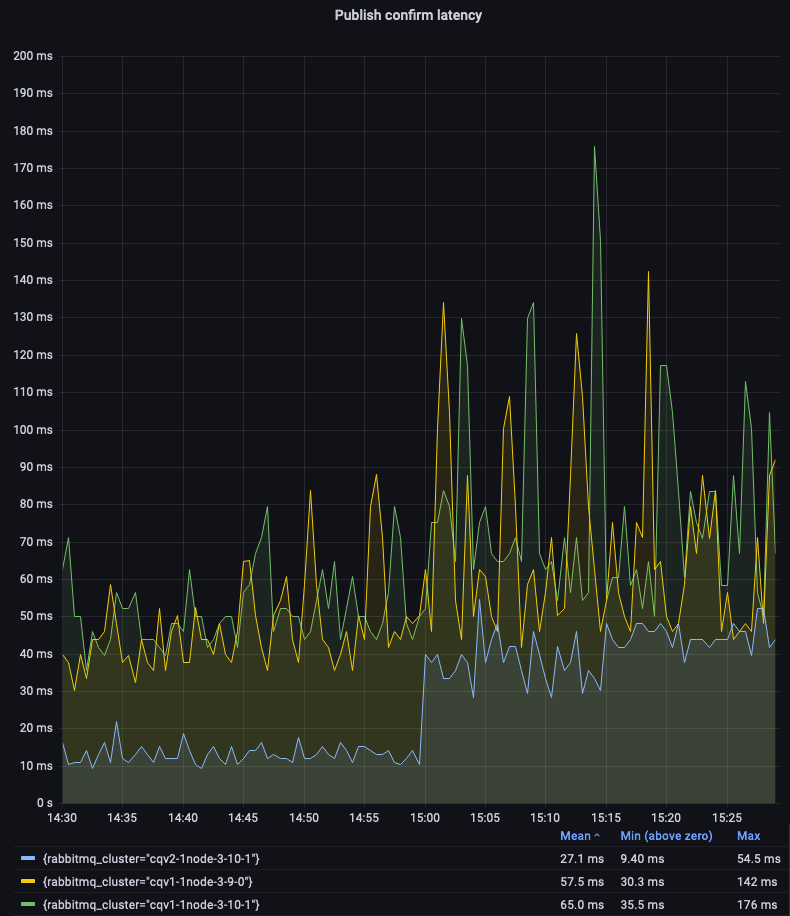
单节点仲裁队列 3.9 和 3.10 在此测试中的表现非常相似(请参见第一个图例)。让我们关注 3 节点集群。
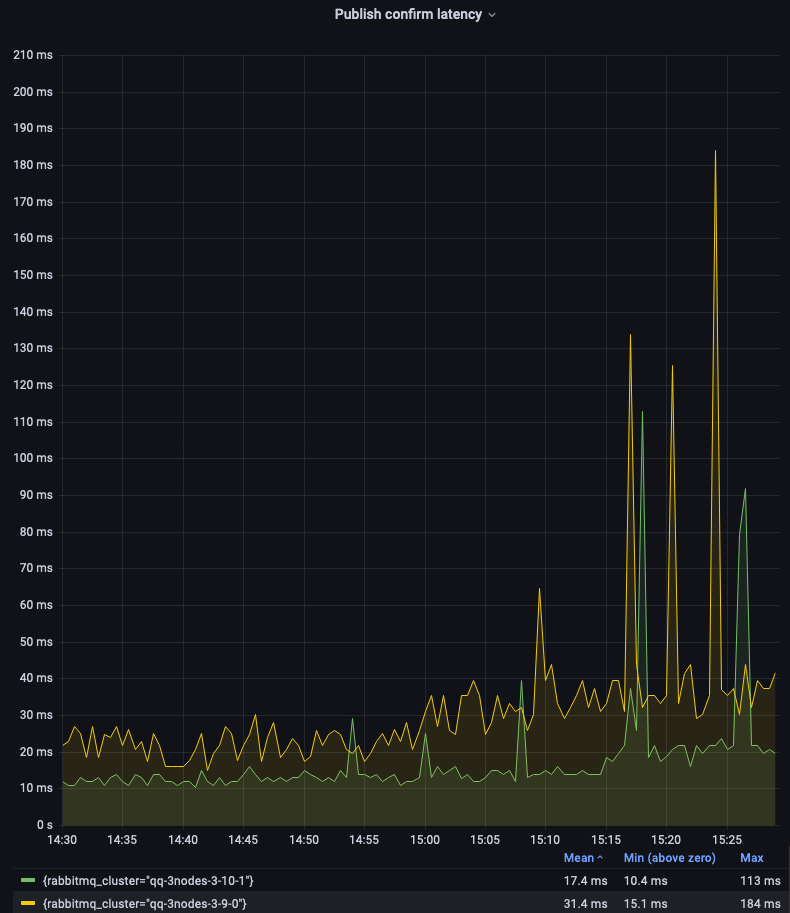
正如您所见,3.10 版本的仲裁队列提供了显著更低且更一致的延迟。由于某些仲裁队列操作的批处理或周期性性质,仍然存在峰值。这是未来版本的一个改进领域。
场景 3:500 个队列,总计 5000 条消息/秒
在此场景中,我们将有 500 个队列,每个队列有 1 个发布者每秒发布 10 条消息,以及一个消费这些消息的消费者。因此,预期的总吞吐量为每秒 5000 条消息。我们再次将此场景运行了一小时,每 15 分钟更改一次消息大小(10、100、1000 和 5000 字节)。
# classic queues (with an exactly=3 mirroring policy where applicable)
perf-test --producers 500 --consumers 500 --publishing-interval 0.1 --confirm 10 --multi-ack-every 100 --qos 100 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--queue-pattern cq-%d --queue-pattern-from 1 --queue-pattern-to 500 \
--auto-delete false --flag persistent
# quorum queues
perf-test --producers 500 --consumers 500 --publishing-interval 0.1 --confirm 10 --multi-ack-every 100 --qos 100 \
--variable-size 10:900 --variable-size 100:900 --variable-size 1000:900 --variable-size 5000:900 \
--quorum-queue --queue-pattern qq-%d --queue-pattern-from 1 --queue-pattern-to 500
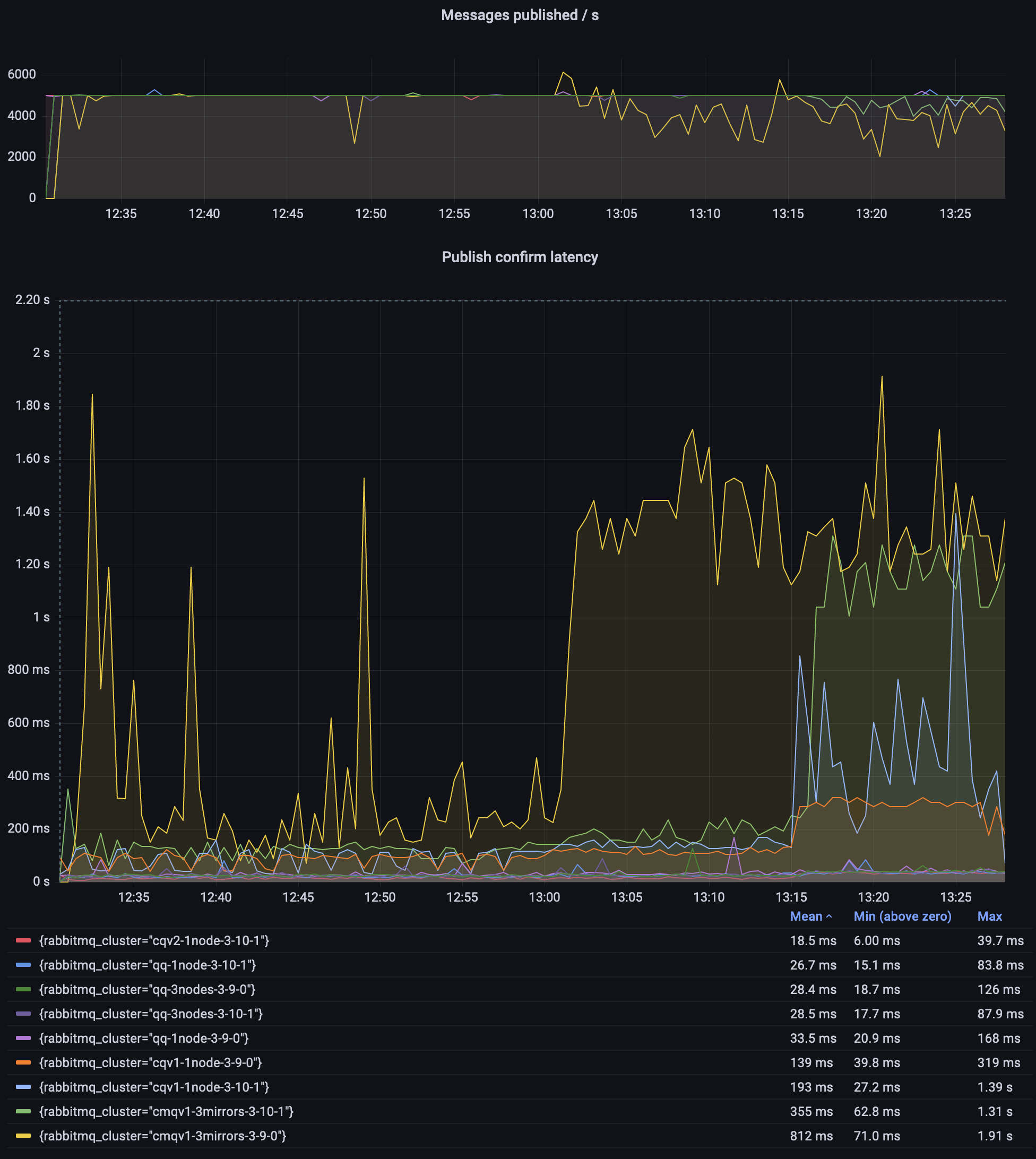
观察结果
- 只有 CMQ 在维持预期的 5000 条消息/秒吞吐量方面遇到困难。
- 经典队列 v2 在整个测试过程中具有最低且最稳定的延迟。
- 3.9.0 CMQ 环境下的发布延迟异常高;我没有调查原因,只需使用仲裁队列或流!
由于经典队列(尤其是镜像的 3.9.0 环境)在图表中占据了大部分位置,因此这里是同一张图,但侧重于经典队列 v2 和 3.10 仲裁队列。
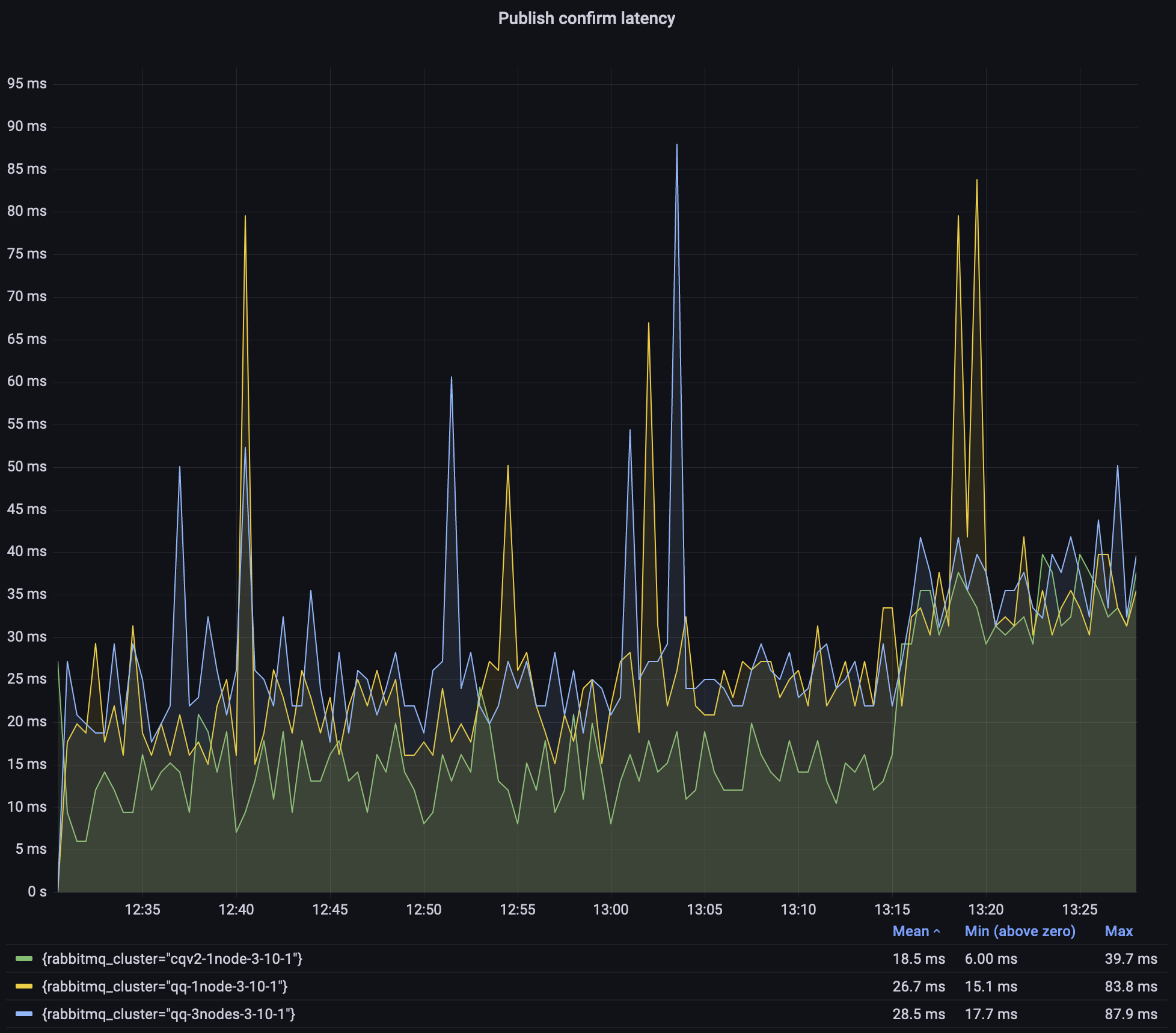
如上所述,仲裁队列的延迟不如我们期望的那样稳定,但大多数时候它们保持在 25ms 以内。这仍然是 500 个队列,总计 5000 条消息/秒,消息大小为 10/100/1000 字节,并且对于 5000 字节的消息,延迟没有显著增加。
对于 3 节点仲裁队列,这是一个退化(边缘情况)的集群,所有队列领导者和所有连接都在单个节点上。这样做是为了使单节点和 3 节点集群之间的测试结果更具可比性。
场景 4:长仲裁队列
在 3.10 之前,仲裁队列在队列很长时性能不佳——检索最旧消息对消费者来说是一项昂贵的操作。在此场景中,我们将首先使用 2 个发布者发布 1000 万条消息,然后使用两个消费者全部消费它们。
# publish 10 milion messages
perf-test --producers 2 --consumers 0 --confirm 3000 --pmessages 5000000 \
--queue-args x-max-in-memory-length=0 --quorum-queue --queue qq
# consume 10 milion messages
perf-test --producers 0 --consumers 2 --multi-ack-every 3000 --qos 3000 --exit-when empty \
--queue-args x-max-in-memory-length=0 --quorum-queue --queue qq
请注意,从 3.10 开始,仲裁队列会忽略 x-max-in-memory-length 属性。它仍然可以通过策略进行配置,但没有效果——队列将表现得好像它被设置为 0。
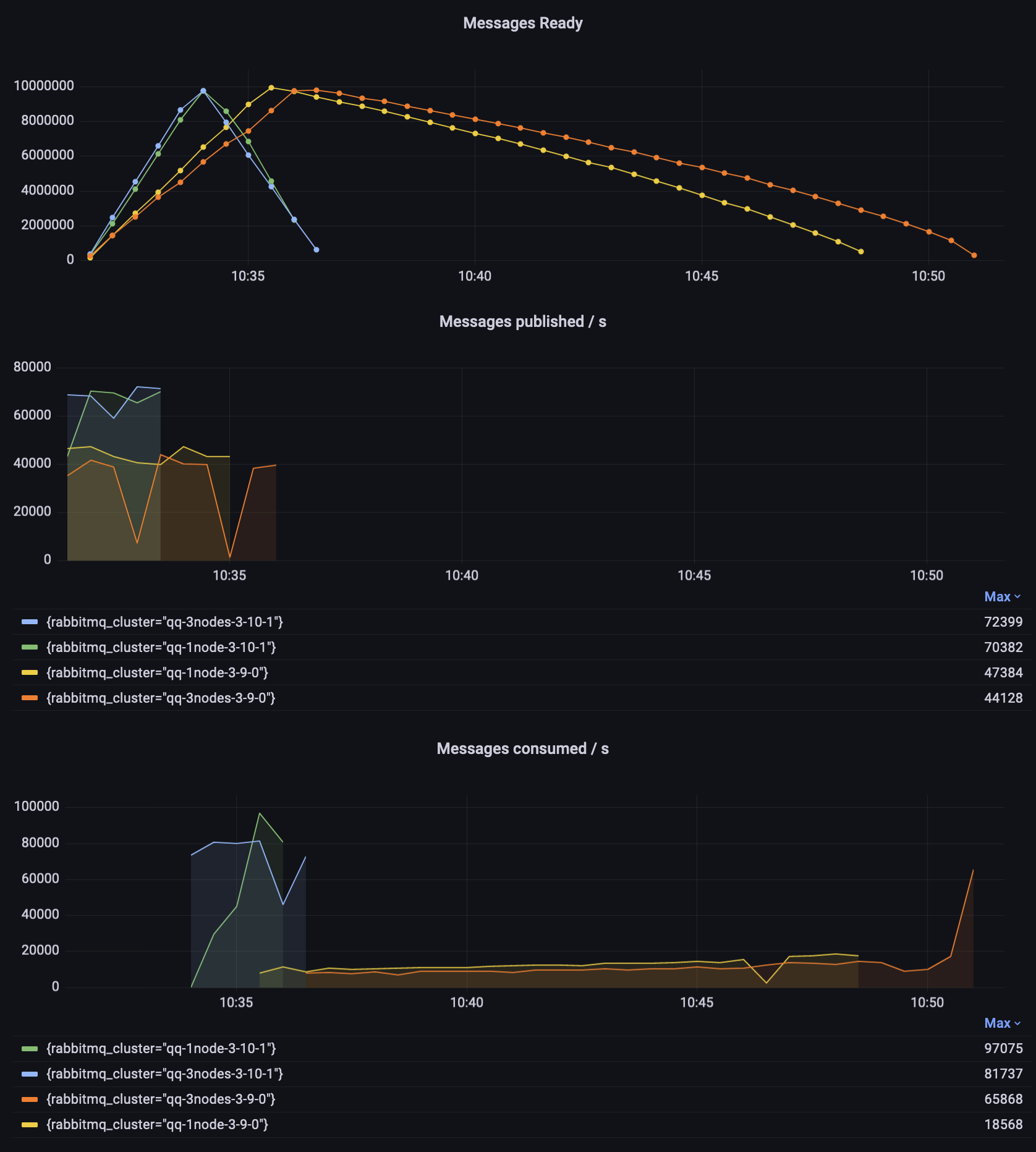
观察结果
- 在 3.10.1 中,发布和消费消息所需的时间大致相同(每个约 3 分钟)。
- 3.9.0 发布消息需要两倍的时间(约 6 分钟)。
- 单节点 3.9.1 需要近 15 分钟才能清空队列,而 3 节点集群则需要额外的 2 分钟。
- 两个 3.9 实例都以大约 10000 条消息/秒的速度开始消费,并随着时间的推移缓慢提高。3 节点 3.9.0 集群的消费速率在最后显着提高,当时队列较短。
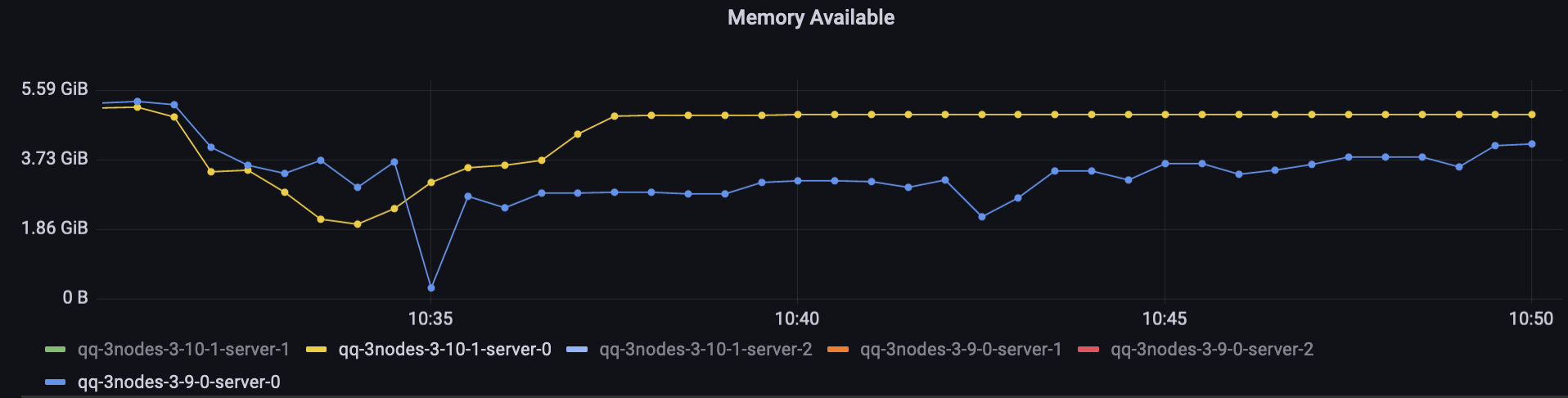
值得注意的是 3.9 发布者的图表(橙色线)中的两次下降。集群遇到了内存警报,因此发布者被暂时阻止。尽管 3.10 环境在此期间执行了更多工作(发布和消费速度更快),但并未发生这种情况。
3.10 测试中的仲裁队列平均使用的内存比经典队列多,因为它们在内存中保留了消息元数据,但它们使用的内存比 3.9 时少。
以下是对执行大部分工作的两个节点(托管了所有队列领导者和所有连接)的直接比较:
更快的导入和声明
对于那些在启动时导入定义的用户,升级到 3.10 后节点启动应该会更快。这归因于多项更改和功能,并且预期行为取决于您的定义以及您使用和将要使用/配置的功能。以下是摘要:
-
如果您使用
load_definitions配置选项,并且 JSON 文件中有许多定义,那么节点在不进行任何操作的情况下应该能更快地启动。这可以为拥有数千个队列的用户节省每次节点启动时的几分钟时间。这里的主要区别在于,在 3.10 中,重新声明已存在的实体应该快得多。集群中的节点通常共享相同的配置文件,因此每个节点都会尝试进行相同的导入,但除第一个节点之外的所有节点实际上都会重新导入现有实体。在节点重启时,假设您不删除这些实体,所有节点都可以更快地启动。 -
如果您设置新属性
definitions.skip_if_unchanged = true,如果定义文件的校验和与之前导入时相同,RabbitMQ 将完全跳过导入。这可以为拥有大型定义文件的集群节省每个节点几分钟的时间。这与上一点类似,除了您需要选择加入(设置属性),并且速度提升更大,因为不尝试导入显然比检查实体是否已存在更快。
其他改进
Erlang 25
此版本支持Erlang 25,它引入了许多编译器和运行时效率改进。这在 64 位 ARM CPU 上最为明显,因为 Erlang 25 中的 JIT 现在支持该架构。
启动时导入定义
在节点在启动时导入定义的集群中,实际上集群中的每个节点都将导入相同的定义,因为所有节点都使用相同或几乎相同的配置文件。
这通常会导致以下两种问题之一,具体取决于事件的确切时序:
- 如果节点一个接一个地启动,由于在导入时集群中只有一个节点,因此所有队列通常最终会出现在一个节点上。
- 如果节点并行启动,则存在大量争用,多个节点尝试声明相同的定义。
在 RabbitMQ 3.10 中,一些重新导入优化通常有助于解决第二个问题。
此外,cluster_formation.target_cluster_size_hint 是一个可以设置的新设置,用于告知 RabbitMQ 集群完全形成后预计有多少个节点。
有了这些额外信息,只有最后一个加入集群的节点才会导入定义。主要的好处是仲裁队列应该在节点之间很好地平衡(受领导者放置设置的影响)。过去,如果导入发生在第一个节点启动后立即进行,那么其他节点将有效地启动为空,因为所有队列在它们启动时就已经在运行了。
结论
RabbitMQ 3.10 中已发布了许多改进,其中一些也已向后移植到最近的 3.9 补丁版本。
我们一直在努力提高性能。然而,RabbitMQ 的配置和使用方式多种多样,许多改进特定于工作负载。我们非常感谢您的帮助——如果您希望 RabbitMQ 在特定场景下更快,请联系我们并告诉我们您的工作负载。理想情况下,如果您可以使用 perf-test 重现问题,我们将很高兴看到我们能做些什么来提高吞吐量、降低延迟或减少内存使用。