使用 Prometheus 和 Grafana 进行监控
概述
本指南介绍了如何使用两个流行的工具监控 RabbitMQ:Prometheus,一个监控工具包;以及 Grafana,一个指标可视化系统。
这些工具共同构成了一个强大的工具集,用于长期指标收集和监控 RabbitMQ 集群。虽然 RabbitMQ 管理 UI 也提供对部分指标的访问,但它本身并不旨在成为一个长期的指标收集解决方案。
请先阅读主要的 监控指南。监控原则和可用指标在很大程度上与使用 Prometheus 和 Grafana 相关。
本指南涵盖的一些关键主题包括
- Prometheus 支持基础
- Grafana 支持基础
- 快速入门,用于本地实验
- 安装步骤,适用于生产系统
- 两种抓取端点响应类型:聚合指标 vs. 独立实体指标
Grafana 仪表盘遵循一系列约定,以提高系统的可观测性并更容易发现反模式。其设计决策在多个章节中进行了解释
内置 Prometheus 支持
RabbitMQ 附带内置的 Prometheus 和 Grafana 支持。
Prometheus 指标收集器的支持包含在 rabbitmq_prometheus 插件中。该插件在专用的 TCP 端口上以 Prometheus 文本格式公开所有 RabbitMQ 指标。
这些指标提供了对 RabbitMQ 节点和运行时状态的深入洞察。它们使得理解 RabbitMQ、使用它的应用程序以及各种基础设施元素的行为更加明智。
Grafana 支持
收集到的指标除非被可视化,否则用处不大。Team RabbitMQ 提供了一套预构建的 Grafana 仪表盘,它们以特定上下文的方式可视化了大量可用的 RabbitMQ 和运行时指标。
有许多可用的仪表盘
等等。每个仪表盘都旨在深入了解系统的特定部分。结合使用时,它们能够详细解释 RabbitMQ 和应用程序的行为。
请注意,Grafana 仪表盘是有倾向性的,并使用一系列约定,例如,以更快地发现系统健康问题或实现跨图表引用。与所有 Grafana 仪表盘一样,它们也是高度可定制的。它们所假设的约定被认为是良好的实践,因此推荐使用。
一个示例
当 RabbitMQ 与 Prometheus 和 Grafana 集成时,RabbitMQ 概览仪表盘的外观如下
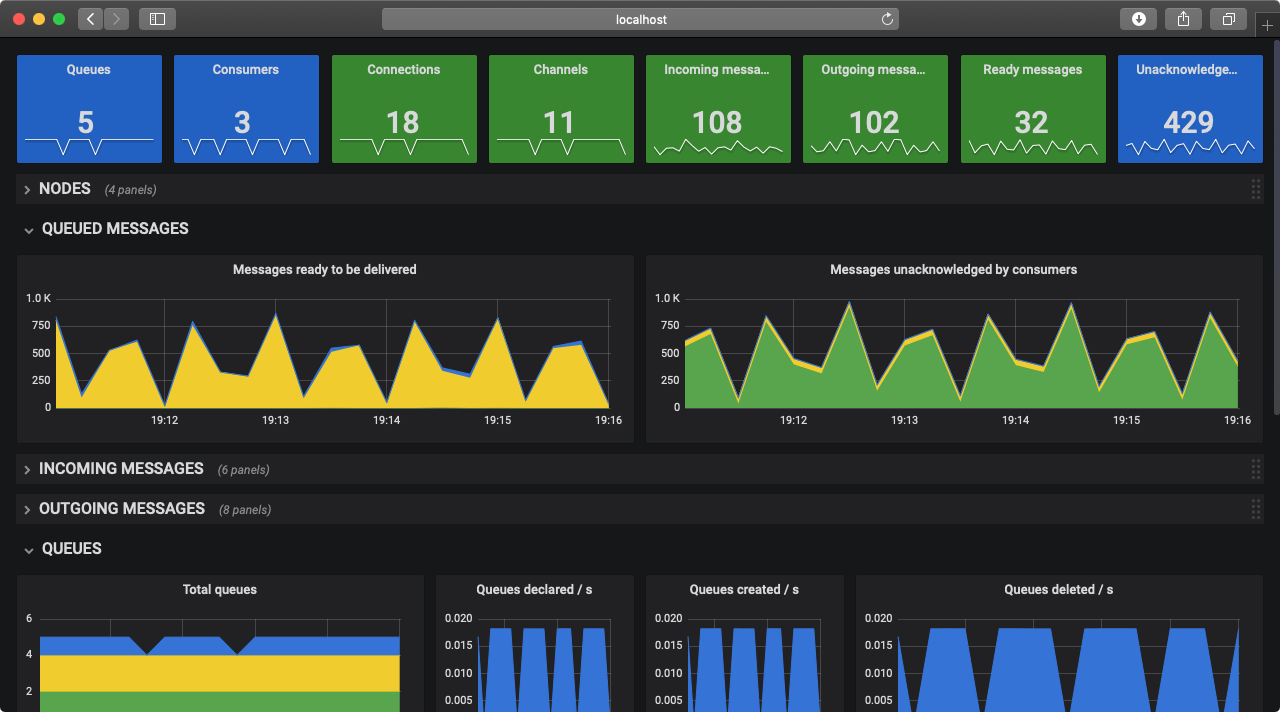
快速入门
开始之前
本节将介绍如何设置一个带有 Prometheus 和 Grafana 仪表盘的 RabbitMQ 集群,以及一些将产生活动和有意义指标的应用程序。
通过此设置,您将能够与本地运行的 RabbitMQ、Prometheus 和 Grafana 进行交互。您还将能够尝试不同的负载配置,以了解所有这些如何协同工作,并理解仪表盘、面板等。
这仅仅是一个示例;rabbitmq_prometheus 插件和我们的 Grafana 仪表盘不需要使用下面演示的 Docker Compose。
先决条件
以下说明假定您已在主机上安装了某些工具
- 一个用于运行命令的终端
- Git 用于克隆存储库
- Docker Desktop 用于在本地使用 Docker Compose
- 一个 Web 浏览器,用于浏览仪表盘
它们的安装超出了本指南的范围。请使用
git version
docker info && docker-compose version
命令行来验证是否已安装必要的工具。
克隆包含清单的存储库
第一步是克隆一个 Git 存储库,rabbitmq-server,其中包含运行 RabbitMQ 集群、Prometheus 和一组应用程序所需的清单及其他组件
git clone https://github.com/rabbitmq/rabbitmq-server.git
cd rabbitmq-server/deps/rabbitmq_prometheus/docker
运行 Docker Compose
接下来,使用 Docker Compose 清单运行一个预配置的 RabbitMQ 集群、一个 Prometheus 实例和一个基本工作负载,该工作负载将生成 RabbitMQ 概览仪表盘中显示的指标
docker-compose -f docker-compose-metrics.yml up -d
docker-compose -f docker-compose-overview.yml up -d
上面的 docker-compose 命令也可以使用 make 目标执行
make metrics overview
当上述命令成功完成后,将在一个容器集中运行一个功能性的 RabbitMQ 集群和一个收集其指标的 Prometheus 实例。
访问 RabbitMQ 概览 Grafana 仪表盘
现在,在 Web 浏览器中导航到 https://:3000/dashboards。这将显示登录页面。用户名和密码都使用 admin。首次登录时,Grafana 会建议更改密码。出于示例目的,我们建议跳过此步骤。
导航到 **RabbitMQ-Overview** 仪表盘,其外观如下
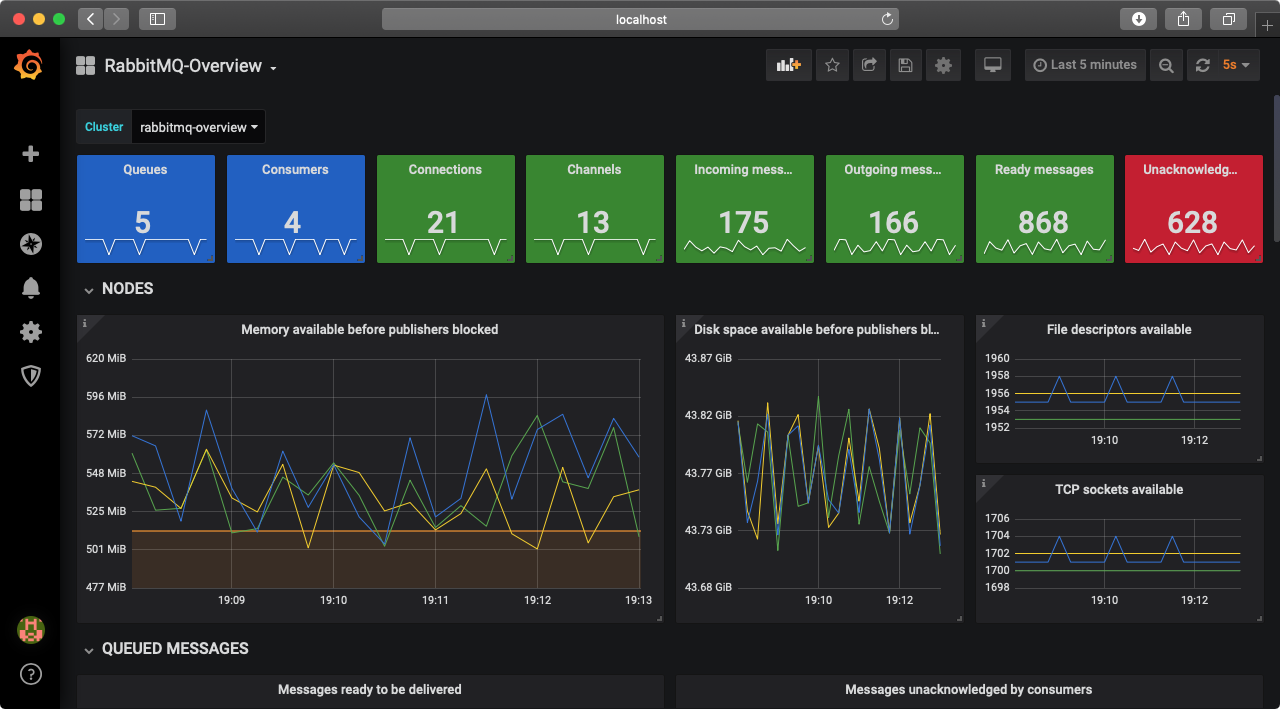
恭喜!您现在已经拥有一个本地运行的、与 Prometheus 和 Grafana 集成的 3 节点 RabbitMQ 集群。现在是深入了解可用仪表盘的最佳时机。
RabbitMQ 概览仪表盘
management UI 概览页面中所有可用的指标都在概览 Grafana 仪表盘中提供。它们按对象类型分组,重点关注 RabbitMQ 节点和消息速率。
健康指标
仪表盘顶部的单个状态指标捕获了 RabbitMQ 集群的健康状况。在这种情况下,只有一个 RabbitMQ 集群,名为 **rabbitmq-overview**,如仪表盘标题下方的 **Cluster** 下拉菜单中所示。
所有 RabbitMQ Grafana 仪表盘上的面板都使用不同的颜色来表示以下指标状态
- 绿色 表示指标值在健康范围内
- 蓝色 表示利用不足或某种形式的性能下降
- 红色 表示指标值低于或高于被视为健康的范围

单个状态指标 的默认范围**并非适用于所有** RabbitMQ 部署。例如,在有许多消费者和/或高预取值(prefetch values)的环境中,拥有超过 1,000 条未确认消息可能是完全正常的。默认阈值可以轻松调整,以适应当前的工作负载和系统。鼓励用户重新审视这些范围,并根据他们的工作负载、监控和操作实践以及对误报的容忍度进行调整。
指标和图表
大多数 RabbitMQ 和运行时指标在 Grafana 中表示为图表:它们是随时间变化的值。这是可视化系统某个方面如何变化的最简单、最清晰的方式。基于时间的图表易于理解关键指标的变化:消息速率、集群中每个节点使用的内存,或并发连接数。除健康指标外,所有指标都是**节点特定的**,即它们代表单个节点上的指标值。
某些指标,例如分组在 **CONNECTIONS** 下的面板,是堆叠的,以捕获**整个集群**的状态。这些指标是在各个节点上收集的,并通过视觉方式进行分组,这使得很容易注意到例如一个节点承担了不成比例的连接数。
我们将这种 RabbitMQ 集群称为**不平衡**,这意味着至少在某些方面,少数节点承担了大部分工作。
在下面的示例中,连接大部分时间都在所有节点之间均匀分布
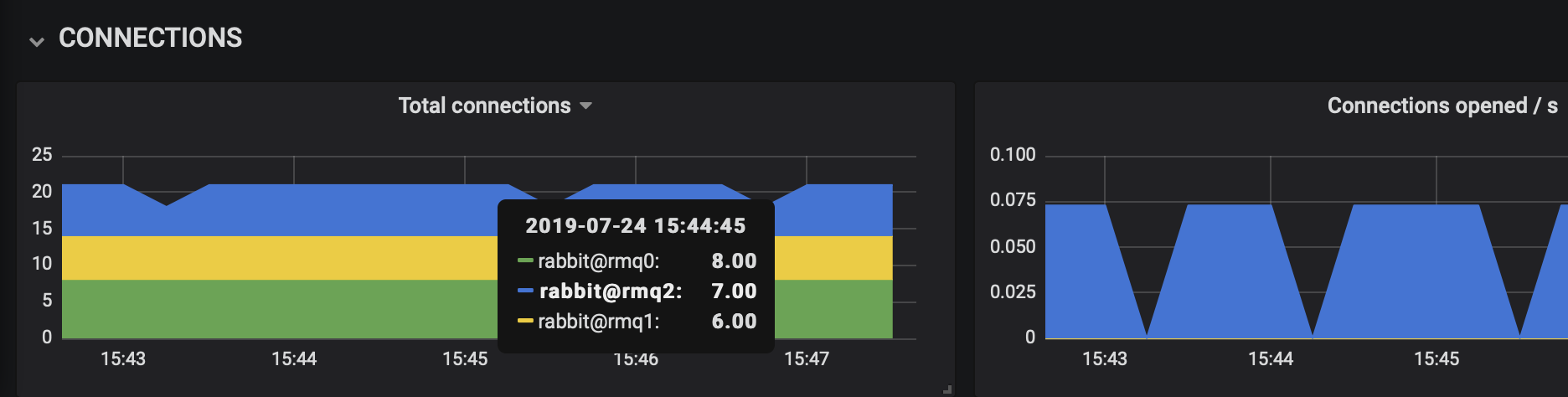
图表中的颜色标签
所有图表上的所有指标都与特定的节点名称相关联。例如,所有以绿色绘制的指标都属于名称中包含 0 的节点,例如 rabbit@rmq0。这使得跨图表关联特定节点的指标变得容易。第一个节点的指标(假设其名称中包含 0)在所有图表中始终显示为绿色。
在使用 RabbitMQ 概览仪表盘时,记住这一点很重要。**如果使用了不同的节点命名约定,颜色在图表中将不一致**:绿色可能在一个图表中代表例如 rabbit@foo,而在另一个图表中代表例如 rabbit@bar。
在这种情况下,必须更新面板以使用不同的节点命名方案。
图表中的阈值
大多数指标都有预先配置的阈值。它们定义了指标的预期操作边界。在图表中,它们显示为半透明的橙色或红色区域,如下面的示例所示。
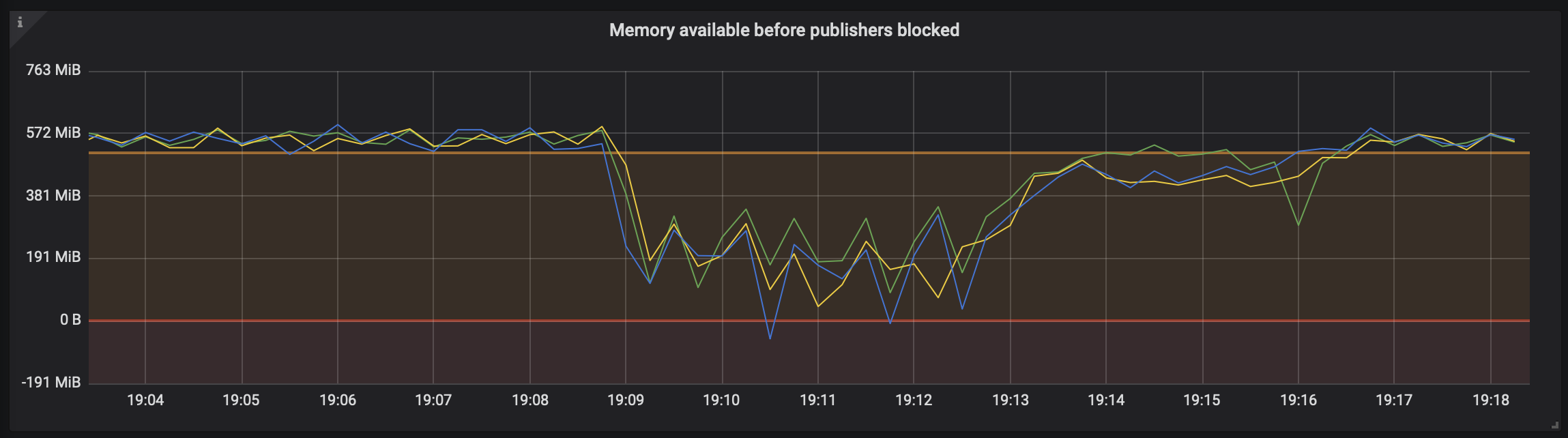
位于橙色区域的指标值表示已超过某个预定义阈值。这可能是可以接受的,尤其是当指标恢复时。接近橙色区域的指标被认为处于健康状态。
位于红色区域的指标值需要关注,并可能表明某种形式的服务降级。例如,红色区域中的指标可能表明一个警报正在生效,或者节点文件描述符不足,无法接受更多连接或打开新文件。
在上面的示例中,我们的 RabbitMQ 集群运行在最佳内存容量下,略高于警告阈值。如果发布的邮件激增,需要存储在 RAM 中,节点使用的内存量将增加,图表上的指标将下降(因为它表示**可用**内存量)。
由于系统可用的内存量超过了分配给运行其的 RabbitMQ 节点的内存量,因此我们注意到内存使用量下降到 0 B 以下。这强调了为操作系统、导致短期内存使用量激增的后台任务以及其他进程留出备用内存的重要性。当 RabbitMQ 节点耗尽其允许使用的所有内存时,会触发内存警报,并且整个集群中的发布者将被阻止。
在图表的右侧,我们可以看到消费者赶上来了,内存使用量下降了。这消除了节点上的内存警报,因此发布者也解除了阻止。集群中的此指标及相关指标随后应恢复到最佳状态。
许多指标没有“正确”的阈值
请注意,Grafana 仪表盘使用的阈值必须有一个默认值。无论仪表盘开发人员选择什么值,它们**都不适用于所有环境和工作负载**。
某些工作负载可能需要更高的阈值,而其他工作负载可能选择降低它们。虽然在许多情况下默认值可能足够,但**操作员必须审查和调整阈值**以满足其特定需求。
图表的相关文档
大多数指标在面板的左上角都有一个帮助图标。
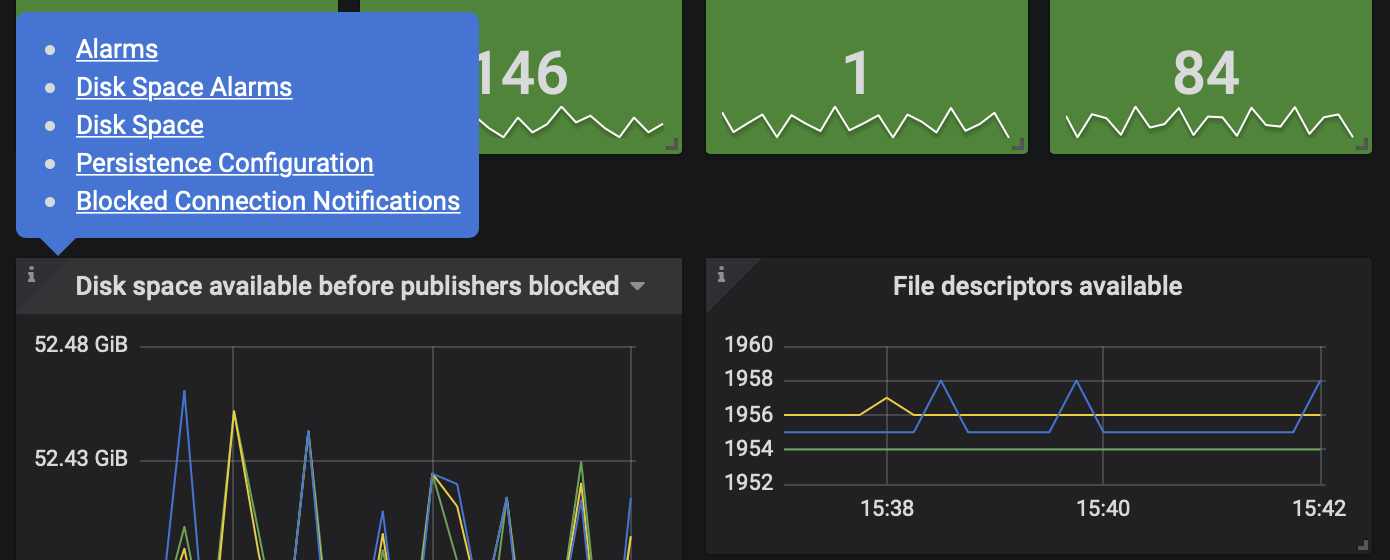
其中一些,如可用磁盘空间指标,链接到 RabbitMQ 文档 中的专用页面。这些页面包含与指标相关的信息。强烈建议熟悉链接的指南,这将有助于操作员更好地理解指标的含义。
使用图表识别反模式
任何以红色显示的指标都可能暗示系统存在反模式。这些图表试图突出 RabbitMQ 的次优使用。**显示红色的图表应进行调查**。这些指标可能表明 RabbitMQ 配置中存在问题,或者客户端(发布者或消费者)采取了次优操作。
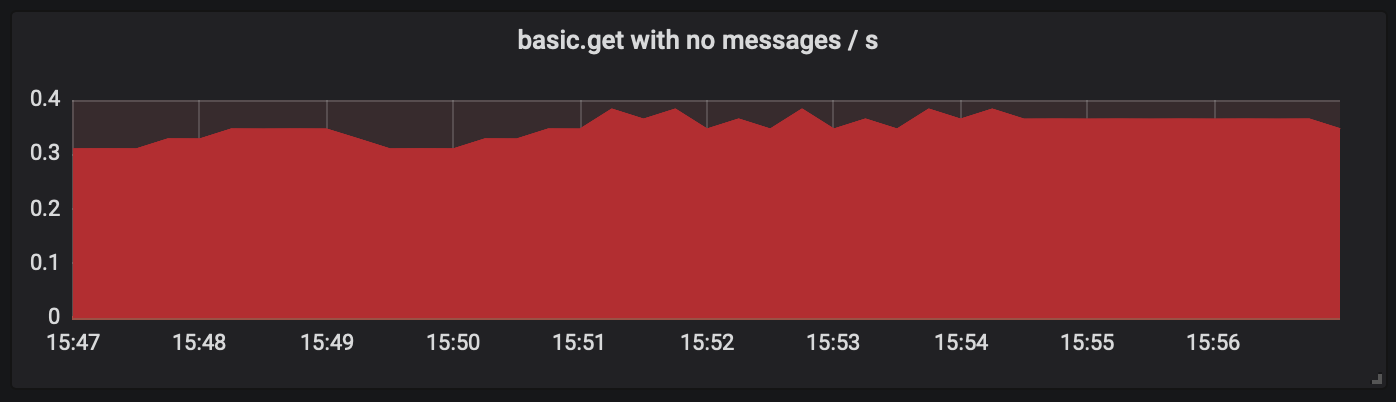
在下面的示例中,我们可以看到效率极低的轮询消费者的使用,它们不断轮询,即使大多数甚至所有轮询操作都未返回消息。像任何基于轮询的算法一样,它是浪费的,应尽可能避免。
让 RabbitMQ 将消息推送到消费者要有效得多。
示例工作负载
rabbitmq_prometheus 插件存储库包含使用PerfTest 模拟不同工作负载的示例工作负载。它们的目标是运行 RabbitMQ 概览仪表盘中的所有指标。这些示例旨在供开发人员和操作员在探索各种指标、其阈值和行为时进行编辑和扩展。
要部署工作负载应用程序,请运行 docker-compose -f docker-compose-overview.yml up -d。修改文件后,相同的命令将重新部署应用程序。
要删除所有工作负载容器,请运行 docker-compose -f docker-compose-overview.yml down 或
gmake down
更多仪表盘:节点间连接(链接)、Raft 和 Erlang 运行时
还有两个 Grafana 仪表盘可用:**RabbitMQ-Raft** 和 **Erlang-Distribution**。它们收集和可视化与 Raft 共识算法(用于Quorum Queues 和其他功能)以及更底层的运行时指标(如节点间连接(通信链接)的状态,例如它们的缓冲区)相关的指标。
这些仪表盘具有相应的 RabbitMQ 集群和 PerfTest 实例,它们以与概览仪表盘相同的方式启动和停止。请随意尝试包含在同一 docker 目录中的其他工作负载。
例如,docker-compose-dist-tls.yml Compose 清单旨在测试节点间通信链接。此工作负载消耗大量系统资源。docker-compose-qq.yml 包含一个 Quorum Queue 工作负载。
要停止并删除工作负载使用的所有容器,请运行 docker-compose -f [file] down 或
make down
安装
与上面的快速入门不同,本节涵盖了面向生产用途的监控设置。
我们将假定已准备好并运行以下工具
- 一个 3 节点 RabbitMQ 3.11 集群
- Prometheus,包括与所有 RabbitMQ 集群节点的网络连接
- Grafana,包括将上述 Prometheus 实例列为数据源之一的配置
RabbitMQ 配置
集群名称
第一步是为 RabbitMQ 集群命名,以便将其与其他集群区分开来。
要查找集群的当前名称,请使用
rabbitmq-diagnostics -q cluster_status
此命令可以针对任何集群节点执行。如果当前集群名称具有区别性且合适,则跳过本段其余部分。要更改集群的名称,请运行以下命令(此处使用的名称仅为示例)
rabbitmqctl -q set_cluster_name testing-prometheus
启用 rabbitmq_prometheus
接下来,在所有节点上启用 **rabbitmq_prometheus** 插件
rabbitmq-plugins enable rabbitmq_prometheus
输出将类似如下:
rabbitmq-plugins enable rabbitmq_prometheus
Enabling plugins on node rabbit@ed9618ea17c9:
rabbitmq_prometheus
The following plugins have been configured:
rabbitmq_management_agent
rabbitmq_prometheus
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@ed9618ea17c9...
The following plugins have been enabled:
rabbitmq_management_agent
rabbitmq_prometheus
rabbitmq_web_dispatch
started 3 plugins.
要确认 RabbitMQ 现在是否以 Prometheus 格式公开指标,请使用 curl 或类似工具获取前几行
curl -s localhost:15692/metrics | head -n 3
# TYPE erlang_mnesia_held_locks gauge
# HELP erlang_mnesia_held_locks Number of held locks.
erlang_mnesia_held_locks{node="rabbit@65f1a10aaffa",cluster="rabbit@65f1a10aaffa"} 0
请注意,RabbitMQ 在专用的 TCP 端口(默认情况下为 15692)上公开指标。
启用身份验证(可选)
可选地,您可以为指标端点启用 HTTP 身份验证。如果要执行此操作,请添加
prometheus.authentication.enabled = true
到 RabbitMQ 配置文件中。
Prometheus 配置
一旦 RabbitMQ 配置为向 Prometheus 公开指标,就应该让 Prometheus 知道它应该从哪里抓取 RabbitMQ 指标。有多种方法可以做到这一点。请参考官方的Prometheus 配置文档。还有一个面向初学者的 Prometheus 入门指南。
指标收集和抓取间隔
Prometheus 将定期抓取(读取)它所监控的系统的指标,默认情况下每 60 秒一次。RabbitMQ 指标也会定期更新,默认情况下每 5 秒一次。由于此值是可配置的,请通过在任何一个节点上运行以下命令来检查指标更新间隔
rabbitmq-diagnostics environment | grep collect_statistics_interval
# => {collect_statistics_interval,5000}
返回的值将是**毫秒**。
对于生产系统,我们建议 Prometheus 抓取间隔的最小值为 15s,RabbitMQ 的 collect_statistics_interval 值为 10000 (10s)。使用这些值,Prometheus 不会过于频繁地抓取 RabbitMQ,RabbitMQ 也不会不必要地更新指标。如果您为 Prometheus 抓取间隔配置了不同的值,请记住在 Grafana 中可视化指标时使用 rate() 设置适当的间隔 - 抓取间隔的 4 倍被认为是安全的。
当使用 RabbitMQ 的管理 UI 默认的 5 秒自动刷新时,保持默认的 collect_statistics_interval 设置是最佳的。出于这个原因,这两个间隔的默认值都是 5000 毫秒(5 秒)。
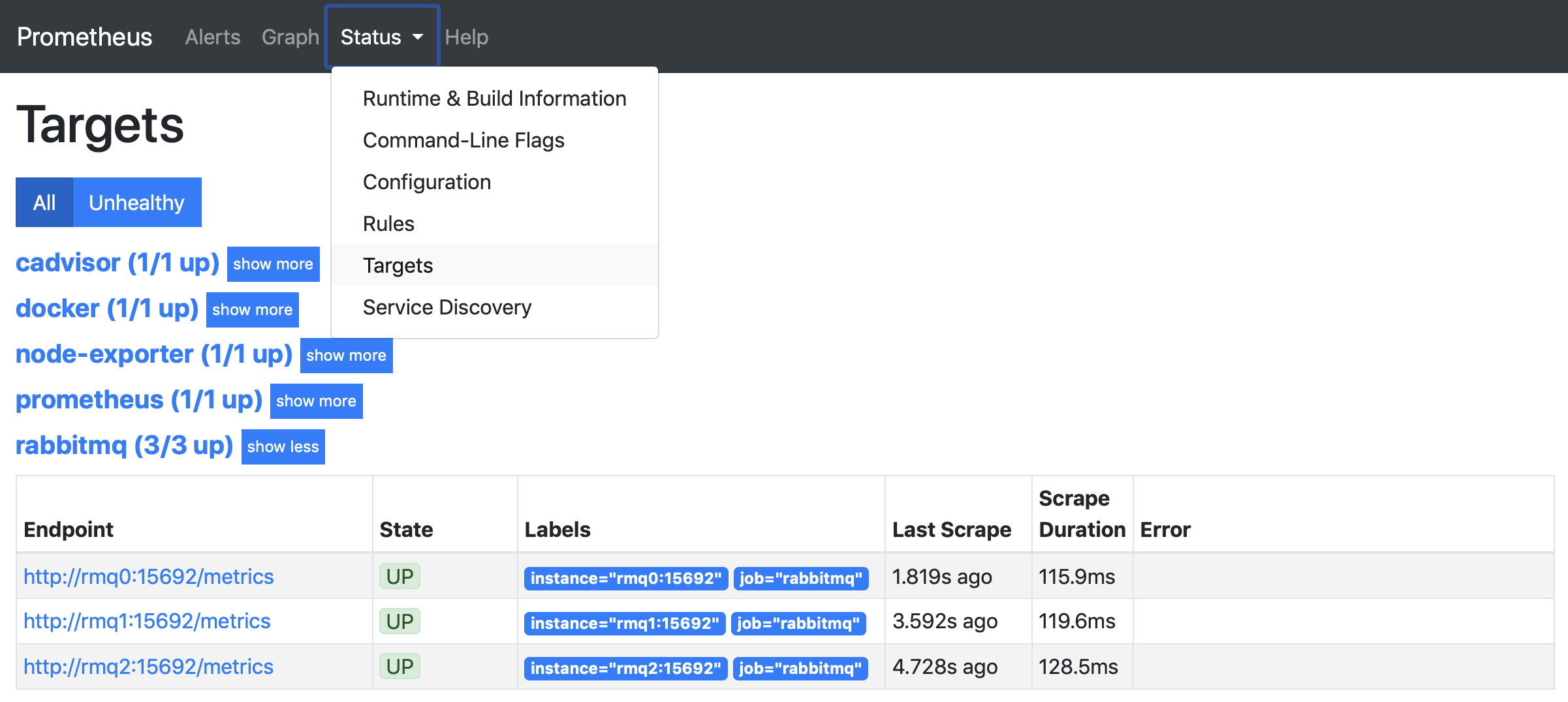
要确认 Prometheus 正在从所有节点抓取 RabbitMQ 指标,请确保 Prometheus Targets 页面上的所有 RabbitMQ 端点都显示为 **Up**,如下图所示
网络接口和端口
端口通过 prometheus.tcp.port 键配置
prometheus.tcp.port = 15692
可以使用 prometheus.tcp.ip 键配置 Prometheus 插件 API 端点将使用的接口,这与消息传递协议监听器类似
prometheus.tcp.ip = 0.0.0.0
要检查运行中的节点使用的接口和端口,请使用 rabbitmq-diagnostics
rabbitmq-diagnostics -s listeners
# => Interface: [::], port: 15692, protocol: http/prometheus, purpose: Prometheus exporter API over HTTP
或者使用 lsof、ss 或 netstat 等工具。
聚合指标和按对象指标
RabbitMQ 可以以两种模式返回 Prometheus 指标
- 聚合:指标按名称聚合。此模式具有较低的性能开销,并且输出大小恒定,即使对象数量(例如连接和队列)增加。
- 按对象:**每个对象-指标对**的独立指标。当存在大量发出统计信息的实体时,例如大量的连接和队列,这可能会导致非常大的有效负载和大量的 CPU 资源用于将数据序列化为输出。
指标聚合对于大型部署来说是更可预测和实用的选择。通过保持响应大小和时间的较小,它能很好地扩展到系统中发出指标的对象数量(连接、通道、队列、消费者等)。它也易于可视化。
指标聚合的缺点是它会丢失数据保真度。聚合无法实现按对象指标和警报。独立对象指标虽然在某些情况下非常有用,但也很难可视化。考虑一个包含 200,000 个连接的图表会是什么样子,以及操作员是否能够理解它。
Prometheus 端点:/metrics
默认情况下,Prometheus(和其他 Prometheus 兼容的解决方案)期望指标在 /metrics 路径上可用。RabbitMQ 默认在此端点上返回聚合指标。
如果您希望在 /metrics 端点上返回按对象(未聚合)的指标,请将 prometheus.return_per_object_metrics 设置为 true
# can result in a really excessive output produced,
# only suitable for environments with a relatively small
# number of metrics-emitting objects such as connections and queues
prometheus.return_per_object_metrics = true
Prometheus 端点:/metrics/memory-breakdown
此端点提供类似于 rabbitmq-diagnostics memory_breakdown 输出的指标。它按不同组件聚合内存使用情况,以提供有关内存分配位置的更详细视图。
内存分解是一个单独的端点,因为提供此信息需要遍历所有 Erlang 进程。这在大多数系统中都不是问题,但在大型部署中成本相对较高。在具有数万(或更多)连接和/或队列的系统中(每个连接和队列至少是一个进程),建议不要使用此端点,或者只不频繁地抓取它。
Prometheus 端点:/metrics/per-object
RabbitMQ 提供了一个专用端点
GET /metrics/per-object
无论 prometheus.return_per_object_metrics 的值如何,它始终返回按对象指标。因此,您可以保留 prometheus.return_per_object_metrics 的默认值 false,并且仍然在需要时通过在 Prometheus 目标配置中设置 metrics_path = /metrics/per-object 来抓取按对象指标(请检查 Prometheus 文档以获取更多信息)。
Prometheus 端点:/metrics/detailed
如前所述,在具有大量实体的环境中,使用按对象指标计算成本很高。例如,/metrics/per-object 返回系统中所有实体的所有指标,即使其中许多指标大多数客户端(如监控工具)都不使用。
这就是为什么有一个单独的按对象指标端点,允许调用者只查询他们需要的指标
GET /metrics/detailed
默认情况下,它不返回任何指标。所有必需的指标组和虚拟主机过滤器必须作为查询参数提供。例如,
GET /metrics/detailed?vhost=vhost-1&vhost=vhost-2&family=queue_coarse_metrics&family=queue_consumer_count
将只返回请求的指标,而排除例如此客户端不感兴趣的所有通道指标。
此端点支持以下参数
- 零个或多个
family值。将仅返回请求的指标系列。完整列表如下文档所示; - 零个或多个
vhost:如果提供,队列相关的指标(queue_coarse_metrics、queue_consumer_count、queue_metrics、queue_delivery_metrics、exchange_metrics和queue_exchange_metrics)将仅为提供的虚拟主机中的队列返回
返回的指标使用不同的前缀:rabbitmq_detailed_(而不是其他端点使用的 rabbitmq_)。这意味着该端点可以与 GET /metrics 一起使用,依赖于其他端点的工具将不受影响。
由于在几乎所有情况下,它查询和提供的数据都更少,因此该端点对系统的负载也较小。例如,
GET /metrics/detailed?family=queue_coarse_metrics&family=queue_consumer_count
提供足以确定队列中有多少消息以及这些队列有多少消费者。在某些环境中,此查询比查询 GET /metrics/per-object 来获取响应中的一小部分指标**效率高 60 倍**。
通用指标
这些是一些通用指标,不指向任何特定的队列/连接/等。
连接/通道/队列流失
分组在 connection_churn_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_connections_opened_total | 打开的总连接数 |
| rabbitmq_detailed_connections_closed_total | 关闭或终止的总连接数 |
| rabbitmq_detailed_channels_opened_total | 打开的总通道数 |
| rabbitmq_detailed_channels_closed_total | 关闭的总通道数 |
| rabbitmq_detailed_queues_declared_total | 声明的总队列数 |
| rabbitmq_detailed_queues_created_total | 创建的总队列数 |
| rabbitmq_detailed_queues_deleted_total | 删除的总队列数 |
Erlang VM/磁盘 IO (通过 RabbitMQ)
分组在 node_coarse_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_process_open_fds | 打开的文件描述符 |
| rabbitmq_detailed_process_open_tcp_sockets | 打开的 TCP 套接字 |
| rabbitmq_detailed_process_resident_memory_bytes | 使用的内存(字节) |
| rabbitmq_detailed_disk_space_available_bytes | 可用磁盘空间(字节) |
| rabbitmq_detailed_erlang_processes_used | 使用的 Erlang 进程数 |
| rabbitmq_detailed_erlang_gc_runs_total | Erlang 垃圾回收器运行的总次数 |
| rabbitmq_detailed_erlang_gc_reclaimed_bytes_total | Erlang 垃圾回收器回收的总内存字节数 |
| rabbitmq_detailed_erlang_scheduler_context_switches_total | Erlang 调度器上下文切换的总次数 |
分组在 node_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_process_max_fds | 打开文件描述符限制 |
| rabbitmq_detailed_process_max_tcp_sockets | 打开 TCP 套接字限制 |
| rabbitmq_detailed_resident_memory_limit_bytes | 内存高水位线(字节) |
| rabbitmq_detailed_disk_space_available_limit_bytes | 磁盘空间低水位线(字节) |
| rabbitmq_detailed_erlang_processes_limit | Erlang 进程限制 |
| rabbitmq_detailed_erlang_scheduler_run_queue | Erlang 调度器运行队列 |
| rabbitmq_detailed_erlang_net_ticktime_seconds | 节点间心跳间隔 |
| rabbitmq_detailed_erlang_uptime_seconds | 节点正常运行时间 |
分组在 node_persister_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_io_read_ops_total | 总 I/O 读取操作数 |
| rabbitmq_detailed_io_read_bytes_total | 总 I/O 读取字节数 |
| rabbitmq_detailed_io_write_ops_total | 总 I/O 写入操作数 |
| rabbitmq_detailed_io_write_bytes_total | 总 I/O 写入字节数 |
| rabbitmq_detailed_io_sync_ops_total | 总 I/O 同步操作数 |
| rabbitmq_detailed_io_seek_ops_total | 总 I/O 查找操作数 |
| rabbitmq_detailed_io_reopen_ops_total | 文件被重新打开的总次数 |
| rabbitmq_detailed_schema_db_ram_tx_total | Schema DB 内存事务总数 |
| rabbitmq_detailed_schema_db_disk_tx_total | Schema DB 磁盘事务总数 |
| rabbitmq_detailed_msg_store_read_total | 消息存储读取操作总数 |
| rabbitmq_detailed_msg_store_write_total | 消息存储写入操作总数 |
| rabbitmq_detailed_queue_index_read_ops_total | 队列索引读取操作总数 |
| rabbitmq_detailed_queue_index_write_ops_total | 队列索引写入操作总数 |
| rabbitmq_detailed_io_read_time_seconds_total | 总 I/O 读取时间 |
| rabbitmq_detailed_io_write_time_seconds_total | 总 I/O 写入时间 |
| rabbitmq_detailed_io_sync_time_seconds_total | 总 I/O 同步时间 |
| rabbitmq_detailed_io_seek_time_seconds_total | 总 I/O 查找时间 |
与 Raft 相关(Quorum queues, streams)的指标
分组在 ra_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_raft_bytes_written | 写入的字节数 |
| rabbitmq_detailed_raft_entries | 写入的条目数 |
| rabbitmq_detailed_raft_mem_tables | 处理的内存表数量 |
| rabbitmq_detailed_raft_segments | 写入的段数 |
| rabbitmq_detailed_raft_wal_files | 创建的写前日志文件数 |
| rabbitmq_detailed_raft_segments | 写入的段数 |
| rabbitmq_detailed_raft_forced_gcs | 强制垃圾回收运行次数 |
| rabbitmq_detailed_raft_commit_index | 当前的提交索引。 |
| rabbitmq_detailed_raft_wal_files | 创建的写前日志文件数 |
| rabbitmq_detailed_raft_commands | 领导者接收的总命令数 |
| rabbitmq_detailed_raft_term_and_voted_for_updates | 任期和投票更新的总次数 |
| rabbitmq_detailed_raft_aux_commands | 接收的辅助命令总数 |
| rabbitmq_detailed_raft_num_segments | 非空段文件的数量。 |
| rabbitmq_detailed_raft_read_segment | 读取的段总数 |
| rabbitmq_detailed_raft_last_written_index | 日志最后写入并同步的索引。 |
| rabbitmq_detailed_raft_read_ops | 读取操作总数 |
| rabbitmq_detailed_raft_term | 当前任期。 |
| rabbitmq_detailed_raft_snapshot_bytes_written | 写入的快照字节数(未安装) |
| rabbitmq_detailed_raft_command_flushes | 低优先级命令批次写入的总次数 |
| rabbitmq_detailed_raft_commit_latency_seconds | 从条目写入日志到提交的近似时间。 |
| rabbitmq_detailed_raft_local_queries | 本地查询总数 |
| rabbitmq_detailed_raft_aer_received_follower_empty | 跟随者接收的空追加条目总数 |
| rabbitmq_detailed_raft_msgs_sent | 发送的所有消息(不包括发送到 wal 的消息) |
| rabbitmq_detailed_raft_aer_replies_success | 收到的成功追加条目总数 |
| rabbitmq_detailed_raft_write_ops | 写入操作总数 |
| rabbitmq_detailed_raft_checkpoint_bytes_written | 写入的检查点字节数 |
| rabbitmq_detailed_raft_read_mem_table | 从内存表中读取的总次数 |
| rabbitmq_detailed_raft_read_cache | 未使用。缓存读取总数 |
| rabbitmq_detailed_raft_bytes_written | 写入的字节数 |
| rabbitmq_detailed_raft_open_segments | 打开的段数 |
| rabbitmq_detailed_raft_snapshots_written | 写入的快照总数 |
| rabbitmq_detailed_raft_last_applied | 最后应用的索引。如果 Ra server 重新启动,可能会回退。 |
| rabbitmq_detailed_raft_invalid_reply_mode_commands | 以无效回复模式接收的命令总数 |
| rabbitmq_detailed_raft_snapshots_sent | 发送的快照总数 |
| rabbitmq_detailed_raft_checkpoints_written | 写入的检查点总数 |
| rabbitmq_detailed_raft_send_msg_effects_sent | 执行的 send_msg 效果总数 |
| rabbitmq_detailed_raft_write_resends | 写入重试总数 |
| rabbitmq_detailed_raft_last_index | 日志的最后一个索引。 |
| rabbitmq_detailed_raft_entries | 写入的条目数 |
| rabbitmq_detailed_raft_checkpoint_index | 当前的检查点索引。 |
| rabbitmq_detailed_raft_read_closed_mem_tbl | 未使用。关闭的内存表总数 |
| rabbitmq_detailed_raft_rpcs_sent | RPC 总数,包括 append_entries_rpcs |
| rabbitmq_detailed_raft_dropped_sends | 发送的无连接或无暂停的消息数量被丢弃 |
| rabbitmq_detailed_raft_effective_machine_version | 机器当前的有效版本号。 |
| rabbitmq_detailed_raft_batches | 写入的批次数 |
| rabbitmq_detailed_raft_release_cursors | 释放游标更新的总次数 |
| rabbitmq_detailed_raft_checkpoints | 执行的检查点效果数量 |
| rabbitmq_detailed_raft_snapshot_installed | 安装的快照总数 |
| rabbitmq_detailed_raft_pre_vote_elections | 预投票选举总数 |
| rabbitmq_detailed_raft_aer_replies_fail | 失败的追加条目总数 |
| rabbitmq_detailed_raft_snapshot_index | 当前的快照索引。 |
| rabbitmq_detailed_raft_mem_tables | 处理的内存表数量 |
| rabbitmq_detailed_raft_fetch_term | 获取的任期总数 |
| rabbitmq_detailed_raft_reserved_2 | 保留计数器 |
| rabbitmq_detailed_raft_reserved_1 | 保留计数器 |
| rabbitmq_detailed_raft_consistent_queries | 一致查询请求总数 |
| rabbitmq_detailed_raft_checkpoints_promoted | 提升为快照的检查点数量 |
| rabbitmq_detailed_raft_writes | 写入的条目数 |
| rabbitmq_detailed_raft_aer_received_follower | 跟随者接收的追加条目总数 |
| rabbitmq_detailed_raft_elections | 选举总数 |
认证指标
分组在 auth_attempt_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_auth_attempts_total | 总授权尝试次数 |
| rabbitmq_detailed_auth_attempts_succeeded_total | 成功授权尝试总数 |
| rabbitmq_detailed_auth_attempts_failed_total | 失败授权尝试总数 |
分组在 auth_attempt_detailed_metrics 下。聚合后,这些数字与 auth_attempt_metrics 相同。
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_auth_attempts_detailed_total | 带源信息的总授权尝试次数 |
| rabbitmq_detailed_auth_attempts_detailed_succeeded_total | 带源信息的成功授权尝试总数 |
| rabbitmq_detailed_auth_attempts_detailed_failed_total | 带源信息的失败授权尝试总数 |
队列指标
此组中的每个指标都通过其标签指向单个队列。因此,响应的大小与节点托管的队列数量成正比。
以下指标从收集成本最低到最高列出。
队列粗略指标
分组在 queue_coarse_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_messages_ready | 准备交付给消费者的消息数 |
| rabbitmq_detailed_queue_messages_unacked | 已交付给消费者但尚未确认的消息数 |
| rabbitmq_detailed_queue_messages | 就绪和未确认消息的总和 - 总队列深度 |
| rabbitmq_detailed_queue_process_reductions_total | 队列进程缩减总数 |
队列传递指标
这些指标类似于 channel_queue_metrics 下分组的指标,但不包含通道 ID 作为其标签。它们对于单独监控每个队列的状态很有用。
分组在 queue_delivery_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_get_ack_total | 使用 basic.get 在手动确认模式下从队列中获取消息的总数 |
| rabbitmq_detailed_queue_get_total | 使用 basic.get 在自动确认模式下从队列中获取消息的总数 |
| rabbitmq_detailed_queue_messages_delivered_ack_total | 从队列传递给消费者的消息数(手动确认模式) |
| rabbitmq_detailed_queue_messages_delivered_total | 从队列传递给消费者的消息数(自动确认模式) |
| rabbitmq_detailed_queue_messages_redelivered_total | 从队列重新传递给消费者的消息总数 |
| rabbitmq_detailed_queue_messages_acked_total | 消费者在队列上确认的消息总数 |
| rabbitmq_detailed_queue_get_empty_total | basic.get 操作在队列上未获取消息的总次数 |
每个队列的消费者计数
分组在 queue_consumer_count 下。这是 queue_metrics 的一个子集,如果请求了 queue_metrics,则会跳过此项
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_consumers | 队列上的消费者数量 |
此指标对于快速检测消费者问题(例如,当没有消费者在线时)很有用。这就是为什么它单独暴露出来。
详细的队列指标
分组在 queue_metrics 下。此组包含每个队列的所有指标,并且可能成本较高
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_consumers | 队列上的消费者数量 |
| rabbitmq_detailed_queue_consumer_capacity | 消费者容量 |
| rabbitmq_detailed_queue_consumer_utilisation | 与消费者容量相同 |
| rabbitmq_detailed_queue_process_memory_bytes | Erlang 队列进程使用的内存(字节) |
| rabbitmq_detailed_queue_messages_ram | 存储在内存中的就绪和未确认消息 |
| rabbitmq_detailed_queue_messages_ram_bytes | 存储在内存中的就绪和未确认消息的大小 |
| rabbitmq_detailed_queue_messages_ready_ram | 存储在内存中的就绪消息 |
| rabbitmq_detailed_queue_messages_unacked_ram | 存储在内存中的未确认消息 |
| rabbitmq_detailed_queue_messages_persistent | 持久化消息 |
| rabbitmq_detailed_queue_messages_persistent_bytes | 持久化消息的大小(字节) |
| rabbitmq_detailed_queue_messages_bytes | 就绪和未确认消息的大小(字节) |
| rabbitmq_detailed_queue_messages_ready_bytes | 就绪消息的大小(字节) |
| rabbitmq_detailed_queue_messages_unacked_bytes | 所有未确认消息的大小(字节) |
| rabbitmq_detailed_queue_messages_paged_out | 分页到磁盘的消息 |
| rabbitmq_detailed_queue_messages_paged_out_bytes | 分页到磁盘的消息的大小(字节) |
| rabbitmq_detailed_queue_head_message_timestamp | 队列中第一条消息的时间戳(如果存在) |
| rabbitmq_detailed_queue_disk_reads_total | 队列从磁盘读取消息的总次数 |
| rabbitmq_detailed_queue_disk_writes_total | 队列将消息写入磁盘的总次数 |
| rabbitmq_detailed_stream_segments | 流段文件的总数 |
交换器指标
此组中的每个指标都通过其标签指向单个交换器。因此,响应的大小与节点托管的交换器数量成正比。
这些指标类似于 channel_exchange_metrics 下分组的指标,但不包含通道 ID 作为其标签。它们对于单独监控每个交换器的状态很有用。
分组在 exchange_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_exchange_messages_published_total | 发布到交换器的消息总数 |
| rabbitmq_detailed_exchange_messages_confirmed_total | 发布到交换器并已确认的消息总数 |
| rabbitmq_detailed_exchange_messages_unroutable_returned_total | 作为强制性消息发布到交换器并作为不可路由返回给发布者的消息总数 |
| rabbitmq_detailed_exchange_messages_unroutable_dropped_total | 作为非强制性消息发布到交换器并作为不可路由被丢弃的消息总数 |
队列-交换器指标
此组中的每个指标都通过其标签指向单个队列-交换器对。
这些指标类似于 channel_queue_exchange_metrics 下分组的指标,但不包含通道 ID 作为其标签。它们对于单独监控每个队列-交换器对的状态很有用。
分组在 queue_exchange_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_exchange_messages_published_total | 通过交换器发布到队列的消息总数 |
连接/通道指标
所有这些都包含通道的 Erlang 进程 ID 作为其标签。这些数据不是很重要,仅用于区分不同通道的指标。
这些指标的生成成本最高。
连接指标
分组在 connection_coarse_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_connection_incoming_bytes_total | 连接上接收的总字节数 |
| rabbitmq_detailed_connection_outgoing_bytes_total | 连接上发送的总字节数 |
| rabbitmq_detailed_connection_process_reductions_total | 连接进程缩减总数 |
分组在 connection_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_connection_incoming_packets_total | 连接上接收的总数据包数 |
| rabbitmq_detailed_connection_outgoing_packets_total | 连接上发送的总数据包数 |
| rabbitmq_detailed_connection_pending_packets | 等待在连接上发送的数据包数 |
| rabbitmq_detailed_connection_channels | 连接上的通道数 |
通用通道指标
分组在 channel_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_channel_consumers | 通道上的消费者数 |
| rabbitmq_detailed_channel_messages_unacked | 已交付但尚未确认的消息数 |
| rabbitmq_detailed_channel_messages_unconfirmed | 已发布但尚未确认的消息数 |
| rabbitmq_detailed_channel_messages_uncommitted | 在事务中接收但尚未提交的消息数 |
| rabbitmq_detailed_channel_acks_uncommitted | 事务中尚未提交的消息确认数 |
| rabbitmq_detailed_consumer_prefetch | 每个消费者的未确认消息限制 |
| rabbitmq_detailed_channel_prefetch | 通道上所有消费者的未确认消息总限制 |
分组在 channel_process_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_channel_process_reductions_total | 通道进程缩减总数 |
带有队列/交换器细分的通道指标
分组在 channel_exchange_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_channel_messages_published_total | 在通道上发布到交换器的消息总数 |
| rabbitmq_detailed_channel_messages_confirmed_total | 在通道上发布到交换器并已确认的消息总数 |
| rabbitmq_detailed_channel_messages_unroutable_returned_total | 作为强制性消息发布到交换器并作为不可路由返回给发布者的消息总数 |
| rabbitmq_detailed_channel_messages_unroutable_dropped_total | 作为非强制性消息发布到交换器并作为不可路由被丢弃的消息总数 |
分组在 channel_queue_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_channel_get_ack_total | 在手动确认模式下使用 basic.get 获取消息的总数 |
| rabbitmq_detailed_channel_get_total | 在自动确认模式下使用 basic.get 获取消息的总数 |
| rabbitmq_detailed_channel_messages_delivered_ack_total | 在手动确认模式下传递给消费者的消息总数 |
| rabbitmq_detailed_channel_messages_delivered_total | 在自动确认模式下传递给消费者的消息总数 |
| rabbitmq_detailed_channel_messages_redelivered_total | 重新传递给消费者的消息总数 |
| rabbitmq_detailed_channel_messages_acked_total | 消费者确认的消息总数 |
| rabbitmq_detailed_channel_get_empty_total | basic.get 操作未获取消息的总次数 |
分组在 channel_queue_exchange_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_queue_messages_published_total | 发布到队列的消息总数 |
虚拟主机和交换器指标
这些附加指标在共享集群中创建虚拟主机或交换器时可能很有用。**这些指标是集群范围的,而不是节点本地的**。因此,**这些指标不得**在集群节点之间聚合。
分组在 vhost_status 下
| 指标 | 描述 |
|---|---|
| rabbitmq_cluster_vhost_status | 给定的虚拟主机是否正在运行 |
分组在 exchange_names 下
| 指标 | 描述 |
|---|---|
| rabbitmq_cluster_exchange_name | 枚举交换器,不带额外信息。此值是集群范围的。比 exchange_bindings 更经济高效。 |
分组在 exchange_bindings 下
| 指标 | 描述 |
|---|---|
| rabbitmq_cluster_exchange_bindings | 交换器的绑定数。此值是集群范围的。 |
流消费者指标
分组在 stream_consumer_metrics 下
| 指标 | 描述 |
|---|---|
| rabbitmq_detailed_stream_consumer_max_offset_lag | 给定流的最高消费者偏移量滞后 |
抓取端点超时
在某些环境中,统计信息实体(队列、连接、通道)不多,而在另一些环境中,抓取 HTTP 端点可能需要向客户端返回大量数据(例如,成千上万行)。在这些情况下,处理请求所需的时间可能会超过嵌入式 HTTP 服务器和 Prometheus 使用的 HTTP 客户端的某些超时。
可以使用 prometheus.tcp.idle_timeout、prometheus.tcp.inactivity_timeout、prometheus.tcp.request_timeout 设置来提高插件端的 HTTP 请求超时。
prometheus.tcp.inactivity_timeout控制 HTTP(S) 客户端的 TCP 连接非活动超时。达到此值时,HTTP 服务器将关闭连接。prometheus.tcp.request_timeout控制客户端发送 HTTP 请求的时间窗口。prometheus.tcp.idle_timeout控制客户端在 HTTP 请求的上下文中发送更多数据(如果有)的时间窗口。
如果 Prometheus 节点和它抓取的 RabbitMQ 节点之间使用了负载均衡器或代理,则 inactivity_timeout 和 idle_timeout 的值应至少与负载均衡器使用的超时和非活动值一样大,通常更大。
下面是一个修改超时的配置片段示例
prometheus.tcp.idle_timeout = 120000
prometheus.tcp.inactivity_timeout = 120000
prometheus.tcp.request_timeout = 120000
Grafana 配置
此设置的最后一个组件是 Grafana。如果您是第一次将 Grafana 与 Prometheus 集成,请遵循官方集成指南。
在 Grafana 与读取和存储 RabbitMQ 指标的 Prometheus 实例集成后,就可以导入 Team RabbitMQ 维护的 Grafana 仪表盘了。请参考官方 Grafana 教程,了解如何在 Grafana 中导入仪表盘。
RabbitMQ 和 Erlang 的 Grafana 仪表盘是开源的,并且公开可从 rabbitmq-server GitHub 存储库获取。
要将 **RabbitMQ-Overview** 仪表盘导入 Grafana
- 访问 Grafana 网站查看官方 RabbitMQ Grafana 仪表盘列表。
- 选择 **RabbitMQ-Overview** 仪表盘。
- 点击 **Download JSON** 链接或复制仪表盘 ID。
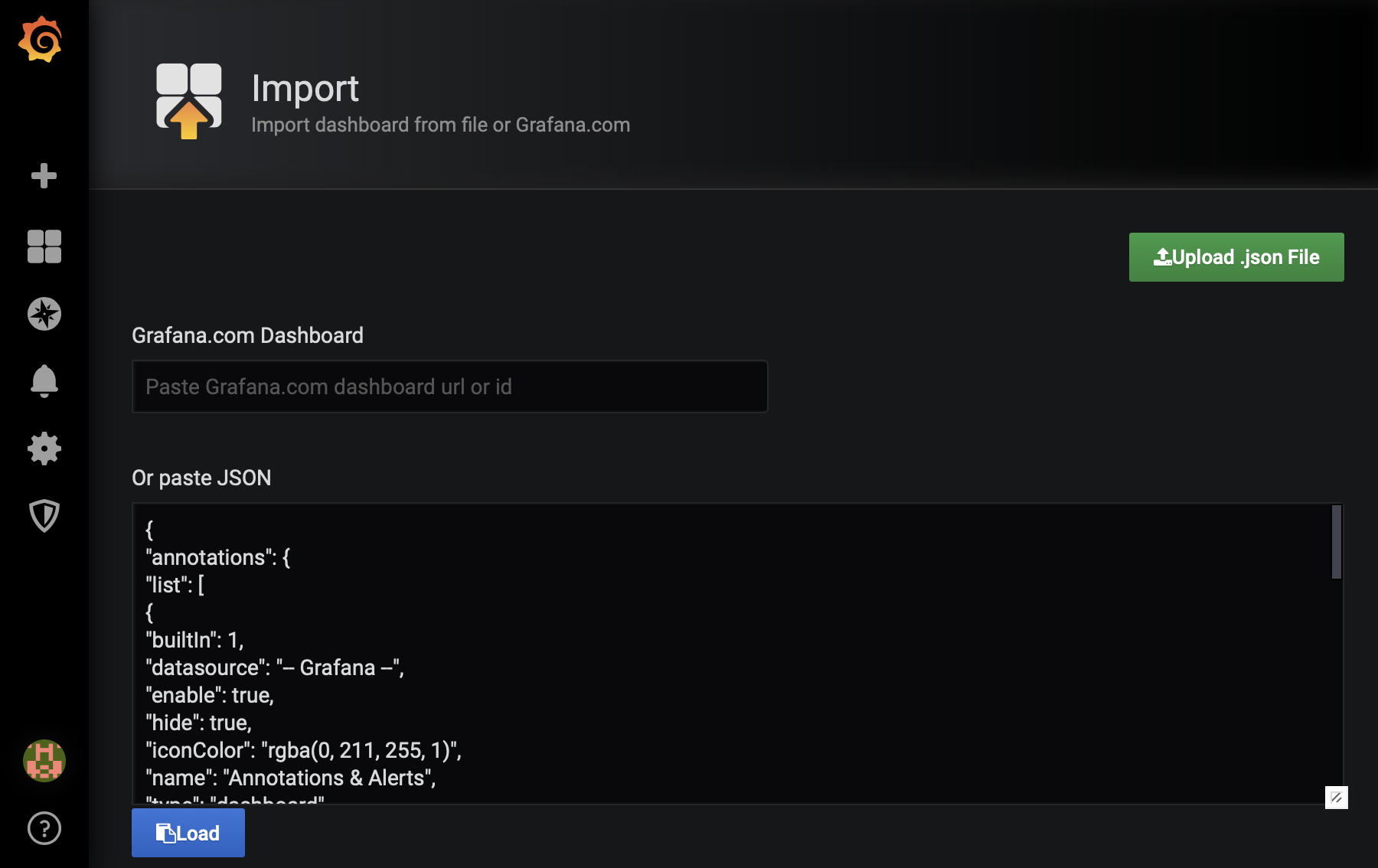
- 将文件内容复制并粘贴到 Grafana 中,然后点击 **Load**,如下图所示
- 或者,在 **Grafana.com Dashboard** 字段中粘贴仪表盘 ID。
对您希望在此 RabbitMQ 部署中使用的所有其他 Grafana 仪表盘重复此过程。
最后,将 Grafana 使用的默认数据源切换为 prometheus。
恭喜!您的 RabbitMQ 现在已通过 Prometheus 和 Grafana 进行监控!
使用 TLS 保护 Prometheus 抓取端点
Prometheus 指标可以通过 TLS 进行保护,与其他监听器类似。例如,在配置文件中
prometheus.ssl.port = 15691
prometheus.ssl.cacertfile = /full/path/to/ca_certificate.pem
prometheus.ssl.certfile = /full/path/to/server_certificate.pem
prometheus.ssl.keyfile = /full/path/to/server_key.pem
prometheus.ssl.password = password-if-keyfile-is-encrypted
## To enforce TLS (disable the non-TLS port):
# prometheus.tcp.listener = none
要使用对等验证启用 TLS,请使用类似以下的配置
prometheus.ssl.port = 15691
prometheus.ssl.cacertfile = /full/path/to/ca_certificate.pem
prometheus.ssl.certfile = /full/path/to/server_certificate.pem
prometheus.ssl.keyfile = /full/path/to/server_key.pem
prometheus.ssl.password = password-if-keyfile-is-encrypted
prometheus.ssl.verify = verify_peer
prometheus.ssl.depth = 2
prometheus.ssl.fail_if_no_peer_cert = true
## To enforce TLS (disable the non-TLS port):
# prometheus.tcp.listener = none