消息是如何存储的?不在内存中!

是时候打破“RabbitMQ 将消息存储在内存中”的迷思了。虽然这在 RabbitMQ 的早期是事实,并且在过去十年中一直是一个选项,但现代 RabbitMQ 版本几乎总是会立即将消息写入磁盘。在这篇博文中,我们将回顾不同类型的队列如何存储消息,但简短的答案是:不在内存中!
让我们先来澄清一下“在内存中存储消息”是什么意思,因为它不是一个精确的陈述。如果将其理解为“RabbitMQ 使用内存处理消息”,那么这个说法当然是正确的。当客户端应用程序将数据发送到 RabbitMQ 时,这些数据首先会出现在内存缓冲区中(这对于所有基于网络的软件都是如此)。同样,RabbitMQ 可能会在内存中缓存一些消息,例如为了提高性能(这一点对于几乎所有需要提供数据的软件都是如此)。
然而,我一直在听到这个说法被用来表达对消息持久性的担忧——如果服务器断电,你的消息就会丢失!在这种情况下,现代 RabbitMQ 版本几乎从不将消息存储在内存中。
没有任何配置,可以让你向 RabbitMQ 发布 1GB 的消息而没有连接的消费者,导致 1GB 的内存被用来存储这些消息。一部分消息可能会被缓存到内存中,但消息是存储在磁盘上的。
我们将回顾不同类型的队列,讨论消息是如何处理、存储以及何时被确认给发布者的。发布者确认在这里至关重要——RabbitMQ 不为未被确认的消息提供任何保证。如果你没有收到确认,你甚至无法知道消息是否已到达 RabbitMQ(例如,网络连接可能已失败)。考虑到这一点,让我们来看看不同类型的队列。
经典队列
经典队列是 RabbitMQ 中最老的队列类型,也是“RabbitMQ 将消息存储在内存中”误解的主要来源。RabbitMQ 于 2007 年首次发布。那时磁盘的速度要慢得多,因此经典队列的设计旨在尽量避免将消息写入磁盘。当时有一整套设置来配置 RabbitMQ 何时应该将消息写入磁盘(一个称为“分页”的过程),这样它就不会无限期地将消息保留在内存中,但确实,你可以说当时的 RabbitMQ 将消息存储在内存中。然而,那已经是很久以前的事了。
在 2015 年发布的 RabbitMQ 3.6 中,“惰性模式”被引入。配置为惰性模式的队列始终将消息存储在磁盘上,而根本不将其保留在内存中。这意味着“RabbitMQ 将消息存储在内存中”在 10 年前就不再是真的了。它仍然默认这样做,但那是完全可选的。
惰性模式在 2023 年发布的 RabbitMQ 3.12 中被移除,但默认(也是唯一可用)的行为发生了变化,并且与惰性模式类似,尽管不完全相同。因此,一年多以来,经典队列不再将消息存储在内存中,甚至无法配置为这样做。到现在为止,这个迷思几乎完全是错误的。
几乎完全?那么,现在经典队列的工作方式是这样的:它们会将传入的消息累积在一个小的内存缓冲区中,并在内存缓冲区装满后立即将它们批量写入磁盘。由于我们不知道是否会有更多消息到来,因此还有其他触发器会刷新该缓冲区,包括在一定数量的批量消息后(即使它们不足以填满整个缓冲区)以及在对该批次执行了一定数量的操作后进行刷新。此外,队列会监控消息的消耗速度并据此做出决定(如果有快速的消费者,更多的消息将被缓存在内存中)。最后,还有一个最后的手段,它每 200 毫秒刷新一次缓冲区。所以,消息在内存中存储的最长时间最多是 200 毫秒,但实际上,我从未见过这种情况发生。发布者通常在几毫秒内收到确认,并且这些确认是在消息写入磁盘后才发送的。
但我使用经典队列时看不到磁盘活动!
确实,发布消息到经典队列而几乎看不到磁盘读写是完全可能的。这是如何实现的?这是对一种非常特定但相对常见情况的优化。如上所述,消息可以短暂地保留在内存中,但如果存在正在等待消息的有源消费者(其预取缓冲区未满),到达队列的消息将被立即分发给消费者,而无需等待其批次写入磁盘。如果一条消息在被写入磁盘之前被消费者确认,那么它根本不会被写入磁盘,因为它根本不需要。队列不存储已确认的消息,所以如果消息在写入之前就被确认,它就不会被写入。如果它在写入之后被确认,它将从队列中删除(实际从磁盘删除将在稍后异步发生,但它被视为立即删除)。
值得一提的是,经典队列有两种独立的存储机制。小于 4KB 的消息(可通过 queue_index_embed_msgs_below 配置)存储在每个队列的消息存储中,而超过此阈值消息则存储在每个 vhost 的消息存储中。上述优化仅适用于那些将存储在每个队列的消息存储中的消息。
所以,这就是真相:在现代 RabbitMQ 版本中,经典队列会将消息存储在内存中非常短的时间(毫秒),而且肯定不会超过 200 毫秒。它们甚至可能根本不将消息写入磁盘,如果消息很小且消耗得足够快的话,但这仅仅是一种性能优化。我将决定权留给你,看这是否算作“RabbitMQ 将消息存储在内存中”,但我认为更准确的说法是“当一条消息被传递到经典队列时,RabbitMQ 会在短暂延迟后将消息写入磁盘”。但是的,这意味着在短暂的瞬间,它们只在内存中。
当然,临时消息是存储在内存中的,对吗?
不。过去情况有所不同,但截至 RabbitMQ 4.0,持久消息和临时消息之间的唯一区别是 RabbitMQ 何时发送发布者确认。消息的存储方式与上述相同。
对于持久消息,当以下两种事件之一发生时,将发送确认:
- 消息已写入磁盘
- 消息已被消费者传递并确认(如果发生得比写入磁盘早)
对于临时消息,只要消息到达队列并进入内存缓冲区,就会发送确认。由于消息是临时的,因此保证是宽松的:队列已收到消息,发布者可以继续处理。
fsync 怎么样?
fsync 是一种低级文件系统操作,它应该确保消息已真正写入磁盘。在像 RabbitMQ 这样的用户空间进程与实际硬件之间有多个 I/O 缓冲区层,包括操作系统缓冲区和内部磁盘缓冲区。执行写入而不执行 fsync 不能保证数据能在突然断电后得以幸存。不幸的是,fsync 是一个相对缓慢的操作,因此任何 I/O 密集型软件都必须决定是否以及何时调用它。虽然经典队列在某些情况下(例如,RabbitMQ 正常停止时)会调用 fsync,但在发送发布者确认之前不会执行 fsync。因此,即使发布者已收到确认的持久消息,如果服务器崩溃,理论上仍然可能丢失。如果您需要更强的保证,可以使用 仲裁队列。
仲裁队列
自 RabbitMQ 3.8(2019 年发布)首次发布以来,仲裁队列始终将消息存储在磁盘上。虽然早期版本有额外的内存缓存,但它在 RabbitMQ 3.10 中被移除。
因此,情况很简单:如果发布者收到了确认,这意味着消息已经写入磁盘并在仲裁节点上进行了 fsync(在最常见的 3 节点集群场景中,这意味着它已在至少 2 个节点上写入并进行了 fsync)。
由于 RabbitMQ 不为未向发布者确认的消息提供任何保证,我们可以就此打住。然而,为了完整起见,我将提到一些消息理论上是在内存中的
- 队列进程有一个邮箱(Erlang/OTP 的概念),队列进程的请求(如入队/出队操作)会在此处到达以便处理。仲裁队列进程从邮箱接收消息并批量处理它们。当请求很多时,这些操作可能会在邮箱中累积,因此,假设邮箱中有入队操作,此时,一些消息只存在于内存中。然而,这通常意味着 RabbitMQ 至少暂时过载,无论如何,这些操作通常会在几毫秒内处理完毕。此外,这些消息尚未确认。
- 仲裁队列依赖于 Raft 协议,我们的 Raft 实现会将最新的 Raft 操作存储在内存中。对于入队操作,这意味着消息也存在于内存中。然而,此时消息已经写入磁盘并进行了
fsync,或者尚未被确认。
流
对于 流,情况比仲裁队列更简单:流根本不支持将消息保留在内存中。总的来说,队列和流的主要区别在于,流可以被多次读取,因此消费消息不会将其从流中移除。如果没有将消息存储在内存中的意义,如果我们希望能够多次向消费者传递消息,可能是在发布之后很长时间。
流不执行 fsync,因为它们针对高消息吞吐量进行了优化。
为了完整起见,就像仲裁队列(和任何其他 Erlang 进程)一样,流进程有一个邮箱,流进程的请求会在此处到达。因此,消息会在内存中存储一小段时间。但再次强调,这些是尚未确认的消息,而且它们很少在内存中停留超过几毫秒。
MQTT QoS 0 队列
RabbitMQ 3.12 引入了原生 MQTT 支持,作为该工作的一部分,引入了一种新的队列类型,专门用于 MQTT QoS 0 消费者(您无法显式声明此类型的队列,您必须创建一个 MQTT QoS 0 订阅)。由于 QoS 0 基本上意味着尽力而为但没有保证,QoS 0 消息根本不会被写入磁盘,而是直接传递给存在的消费者。实际上,除了 Erlang 邮箱之外,根本没有队列(beyond the Erlang mailbox)。从发布者收到的消息会立即传递给消费者并从内存中移除。
这算不算将消息存储在内存中?我认为不算——消息最初在内存中,仅仅是因为计算机就是这样工作的,并且一旦传递给消费者就会从内存中移除。我们并没有真正将它们存储在内存中——我们只是处理它们,在这种情况下从不将它们写入磁盘。你也可以不同意,认为这正是“存储消息在内存中”的含义,但即使那样——这仅适用于 MQTT QoS 0 用途,并且消息通常在内存中停留不超过零点几秒。
消息元数据
到目前为止,我一直关注消息体,因为人们在谈论在内存中存储消息时通常指的是消息体。然而,RabbitMQ 也需要跟踪当前存在于队列中的消息。例如,当队列定义了x-max-length 限制时,RabbitMQ 需要跟踪队列中所有消息的总大小,因此在传递消息时,它会在内存中保留消息的大小(但不包括消息体本身),以便在消费者确认消息后将其快速从队列总大小中减去。
这种元数据由不同的队列类型以不同的方式存储,但即使存储在内存中,它也会消耗比消息体少得多的内存,并且不会改变关于消息持久性的任何保证。
以下是我们为不同队列类型存储元数据的方式:
- 经典队列
- 对于存储在每个队列的消息存储中的消息,内存中不存储任何数据
- 对于存储在每个 vhost 的消息存储中的消息,内存中会有一些元数据
- Quorum Queues
- 元数据存储在内存中(每个消息至少 32 字节,有时更多,例如在使用消息 TTL 时)
- Streams
- 内存中不存储任何消息元数据
这基本上意味着,对于经典队列中存储的 4KB 以下的消息,以及对于流,无论队列/流中有多少消息,内存使用量都是恒定的。你将先用完磁盘空间而不是内存(你应该配置保留/长度限制以避免用完磁盘空间,但这又是另一回事)。
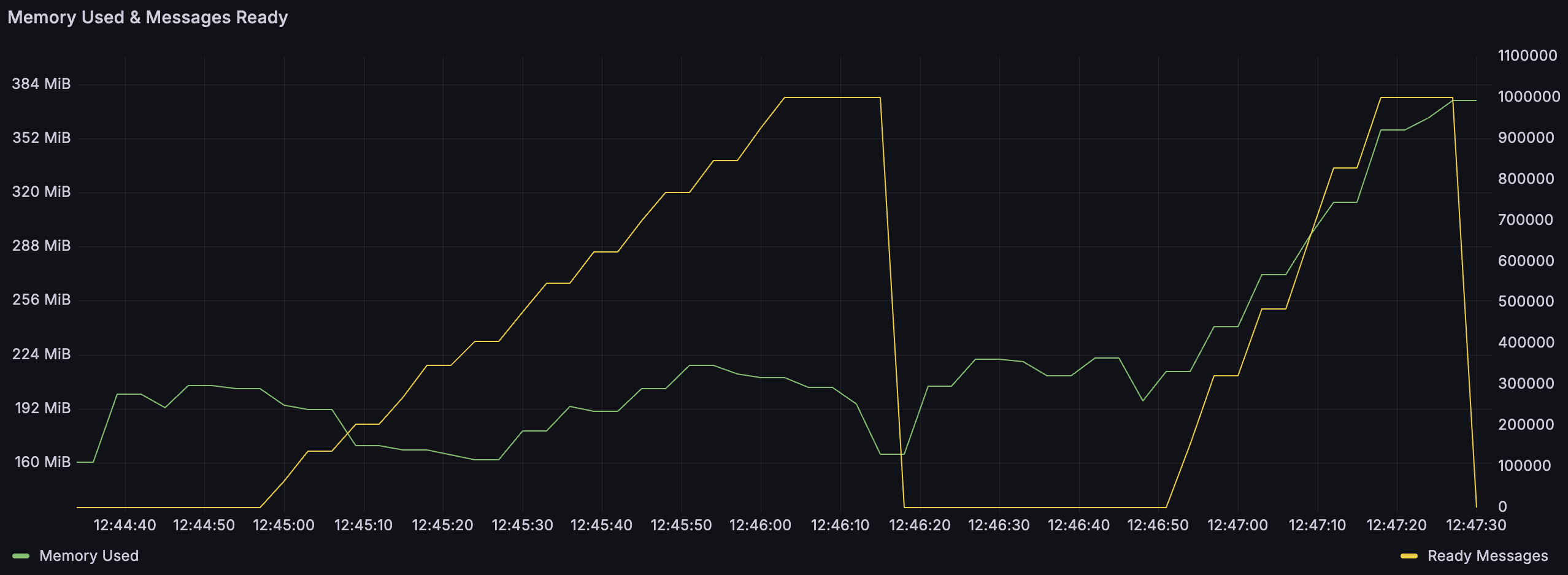
以下是一个说明经典队列两种存储机制之间差异的图示。在此测试中,我首先发布了 100 万条 4000 字节的消息,然后删除了队列并发布了 100 万条 4100 字节的消息。正如你所看到的,第一阶段的内存使用量是稳定的(尽管有小幅波动),但在发布更大的消息时,我们可以看到内存使用量也在增长。这是因为 4100 字节超过了阈值,所以这些消息存储在每个 vhost 的消息存储中,而每个 vhost 的消息存储在内存中保留了一些元数据。一百万条 4KB 的消息将占用 4GB 的内存来存储,而实际使用量仍低于 400MB。
总结
这是要点总结。
| 类型 | 消息何时写入磁盘? | fsync? | 发布者确认何时发送? |
|---|---|---|---|
| 经典 | 几毫秒后或内存缓冲区满时(以先发生的为准) | 否 | 持久消息:消息写入磁盘或被消费并确认后 临时消息:批量进入内存后立即发送 |
| 仲裁 | 立即(除了在邮箱中等待的未确认消息,详见上文) | 是 | 消息已写入磁盘并在仲裁节点上进行了 fsync(最常见的是 3 个节点中的 2 个节点) |
| Streams | 立即(除了在邮箱中等待的未确认消息,详见上文) | 否 | 消息已写入磁盘并在仲裁节点上进行了 fsync(最常见的是 3 个节点中的 2 个节点) |
RabbitMQ 提供的灵活性,支持多种协议、队列类型和其他配置(例如,单节点与带队列复制的集群),加上 18 年的历史和演进,意味着几乎任何“RabbitMQ 做/不做 X”的陈述都是不准确的,或者至少是不精确的。它们几乎总需要用特定的版本和配置来限定。
回到本文的标题,我认为可以说“RabbitMQ 不将消息存储在内存中”比相反的说法更接近事实,后一种说法仍在 RabbitMQ 相关的讨论中流传。无论何种队列类型,都没有任何配置可以在没有连接的消费者的情况下发布,例如 1GB 的消息到 RabbitMQ,会导致 1GB 的内存被用来存储这些消息。最重要的是,如果您想要高数据安全保证,仲裁队列是可用的,并且默认安全地存储数据。如果您将消息发布到仲裁队列并收到确认,那么需要发生灾难性事件 RabbitMQ 才会丢失它(如果您想保护消息免受灾难性事件的影响,您可能对商业的Warm Standby Replication 插件感兴趣)。
如果您不需要如此高的数据安全保证,您就不必承担数据安全的内在开销。只需为工作选择正确的工具。