RabbitMQ 3.13:经典队列变更

我们已经在单独的博文中宣布了 3.13 的两个主要新功能
本文将重点介绍此版本中对经典队列的更改
- 经典队列存储格式 1.0 版本已弃用
- 经典队列消息存储的新实现
经典队列存储入门
在深入探讨变更之前,有必要简要解释一下经典队列是如何存储消息的。对于每条消息,我们需要存储消息的载荷(payload)以及一些关于消息的元数据(例如,该消息是否已传递给消费者)。将消息数据(一个不透明的二进制 blob,可能体积很大)与元数据(小的键值映射)分开存储是有意义的。然而,对于小消息来说,执行两次单独的写入(一次用于元数据,一次用于消息内容)是浪费的。因此,经典队列对小消息的处理方式与大消息不同。
历史上,在我们现在称之为经典队列版本 1 的版本中,这个过程称为将消息嵌入索引,而属性 queue_index_embed_msgs_below 控制着多小的消息才算小到可以嵌入(默认为 4kB)。超出此阈值大小的消息存储在消息存储(message store)中——一个具有不同磁盘表示的单独的键值结构。对于存储在消息存储中的消息,索引包含元数据和消息存储 ID,这使得在需要时可以检索到载荷。每个虚拟主机(virtual host)有一个消息存储,而每个队列有一个单独的索引。
经典队列存储版本 2(在 3.10 中引入)在逻辑上非常相似:仍然存在相同的每个虚拟主机的消息存储,以及一个单独的每个队列的消息存储,用于存储元数据和小消息。然而,我们每个队列存储的内容结构完全不同,因此我们不再仅仅称之为索引——小消息不嵌入索引,而是存储在每个队列的消息存储中的单独文件中。
每个虚拟主机的消息存储仍然用于存储较大的消息,但 3.13 版本显著改变了其行为。
为了向后兼容,queue_index_embed_msgs_below 仍然控制着消息是否足够大以存储在每个虚拟主机的消息存储中,并且默认值仍然是 4kB。
经典队列版本 2 (CQv2)
几年前,我们开始了一项重写经典队列以提高性能的旅程。自最初的实现(现在已有近 20 年历史!)以来,已经发生了许多变化。以下是这次旅程的步骤概述。
- 自 3.10 起,具有
queue-version=2的队列使用了新的索引存储格式(我们以不同的方式存储每个队列的数据)。 - 自 3.12 起,经典队列(v1 和 v2)永远不会在内存中存储超过少量消息。
- 自 3.12 起,小于
queue_index_embed_msgs_below(默认为 4kb)的消息处理效率大大提高。
随着 3.13 的发布,我们即将结束这段旅程。
- 从 3.13 开始,大于
queue_index_embed_msgs_below的消息处理方式更加高效。 - 从 3.13 开始,经典队列 v1 已弃用。
在 RabbitMQ 4.0 中,我们将移除经典队列的镜像功能。正如我们之前多次提到的,如果您需要高可用性的复制队列,您应该使用自 3.8 版本起即可使用的仲裁队列(quorum queues)。移除镜像功能将使实现获得进一步的优化。
此外,在 4.0 中,我们很可能会移除队列索引的 v1 实现(这可能会根据您的反馈而推迟!)。当您将来升级到 4.0 时,所有仍在使用 v1 的经典队列将在启动时需要转换为 v2。如果消息量很大和/或队列很多,这可能需要很长时间。因此,有计划地进行转换过程是一个好主意。
如果还没准备好使用 CQv2 怎么办?
在索引实现版本 1 被移除之前,您仍然可以使用它。
消息存储实现没有这样的选择——3.13 包含了显著的改进,尤其是在与 v2 索引结合使用时。然而,与 v1 结合使用时也可能存在一些小的回归。建议用户彻底测试他们的应用程序,并报告 v2 索引比 v1 差的情况。
CQv1 -> CQv2 转换
由于 v1 和 v2 使用不同的文件格式,如果一个队列从 v1 更改为 v2(反之亦然——降级也受支持),则需要进行转换。如果您有一个现有的经典队列 v1 并应用了具有 x-queue-version=2 的策略,则此队列在转换期间将不可用——队列需要一点时间来将文件重写为新格式。此类转换不应花费超过几秒钟——如果您发现耗时更长,请报告。
由于队列版本可以通过策略更改,因此也可以逐步从 v1 迁移到 v2。您可以声明一个仅匹配部分队列的策略,一旦它们被转换,您可以扩展正则表达式以匹配更多队列,或者声明另一个匹配不同队列子集的策略。即使策略匹配了许多队列,迁移也严格是每个队列的操作——任何已完成转换的队列在转换后立即可用,可以为客户端应用程序提供服务,即使其他队列仍在重写其文件。
您甚至可以在 3.12(甚至 3.10 或 3.11)上进行此转换。如果您这样做了,v1 在 4.0 中的移除将不会真正影响您,因为您所有的队列都将是 v2 了。
性能对比
让我们来看看 RabbitMQ 3.12.11 与 3.13.0-rc.4 的对比结果。有关基准测试设置和我们运行这些测试方式的详细信息,请参阅之前的博客文章,或查看我们用于维护环境配置和包含工作负载的脚本的存储库。
所有测试均使用 100B 和 5kB 的消息进行。
发布和消费
在此测试中,我们有一个发布者和一个消费者,并尝试通过单个队列尽快发送消息。
如您所见,经典队列 v2 与 CQv1 相比提供了显著更好的性能,而 3.13 提高了两个版本的性能。对于仍在使用 CQv1 的用户来说,在 3.13 中迁移到 CQv2 可能会使小消息的吞吐量几乎翻倍!

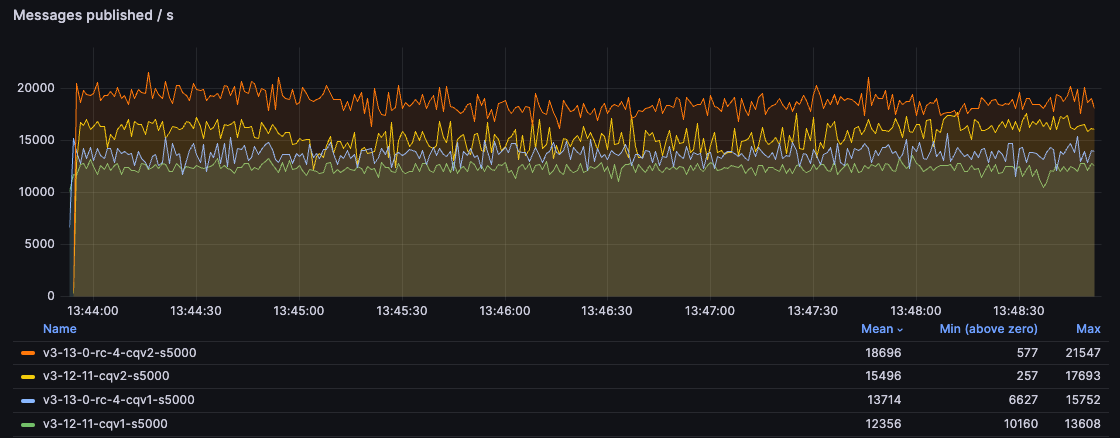
仅发布
在此测试中,我们以全速发布到队列,使用 2 个发布者,而不消费任何消息。队列从空增长到 500 万条消息。
对于 100B 消息,CQv2 在吞吐量方面远远领先于 CQv1,比 3.12 提高了 250% 以上。

5kB 消息的测试更为细致。CQv2 的 3.13 版本以巨大的优势获胜,并且 CQv2 的优势即使在 3.12 中也可见。然而,新的消息存储与旧索引的组合性能不一致——它大多数时候都有很好的吞吐量,但会出现显著的慢速(延迟尖峰)。这是不幸的,但鉴于触发此行为所需的因素数量以及用户最终应该迁移到 CQv2 的事实,我们决定保持现状。我们只在此测试中看到了这种行为,因此需要满足以下条件:一个运行 CQv1 队列(消息大小大于 4kb 或 queue_index_embed_msgs_below 的值)的 3.13 节点,发布者速度明显快于消费者(或根本没有消费者),以及高消息吞吐量。如果您有此类工作负载,迁移到 CQv2 不仅可以防止这种回归,还能提供比 CQv1 ever achieved 更高的性能。

仅消费
在此测试中,我们消费前一个测试产生的积压消息。有 500 万条消息需要消费(希望您的队列会更短!)。
对于 100B 消息,您可以看到 CQv2 在早期提供了约 30% 的更高消费率。随着时间的推移,当队列变短时,CQv1 会变快,但 CQv2 环境仍然比 CQv1 早将队列清空(当消费率降至零时,表示队列为空)。
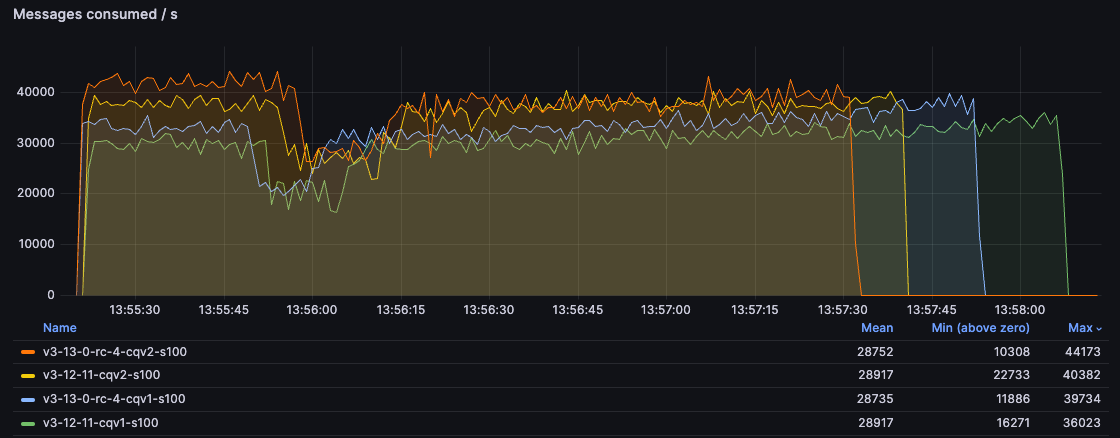
对于由每个虚拟主机的消息存储处理的 5kB 消息,您可以看到 3.13 变更的主要好处。由于 v1 和 v2 共享消息存储实现,在此测试中,所有 3.13 环境都显著领先于 3.12,即使是具有 CQv2 的 3.12。我们可以看到 3.13 的吞吐量提高了约 50%。
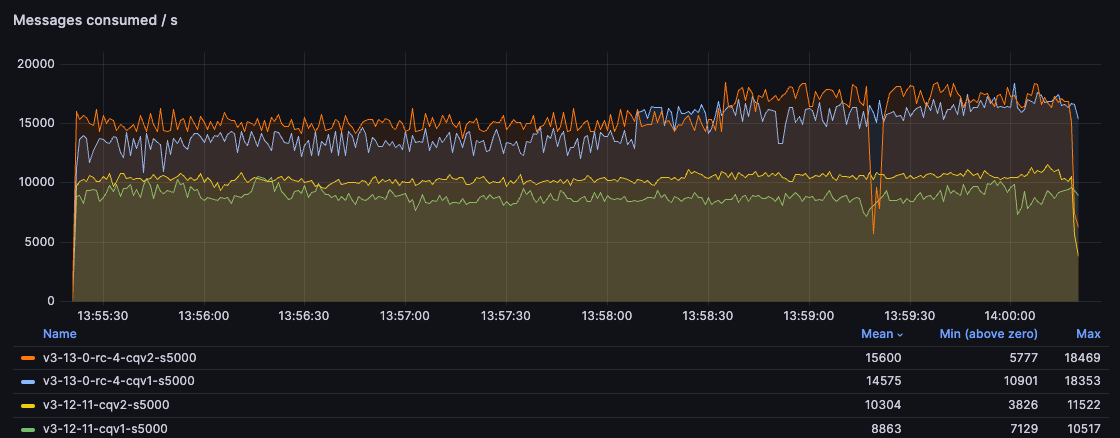
多个队列
在此测试中,我们不将单个队列推到极限,而是有 5 个并发消息流:5 个发布者,每个发布者发布到不同的队列;5 个消费者,每个消费者消费一个队列。每个发布者每秒发送 10000 条消息,因此预期的总吞吐量为 50000 条消息。对于 100B 消息,所有环境都达到了预期的吞吐量;而对于 5kB 消息,所有环境的吞吐量都在 27000 条消息/秒左右波动。更有趣的部分是端到端延迟——消息从发送到被消费需要多长时间。
对于 100B 消息,我们可以看到 CQv2 环境可以更快地传递消息。对于从 3.12 的 CQv1 迁移到 3.13 的 CQv2 的用户来说,平均延迟降低了 75%,内存使用量减少了 50%。
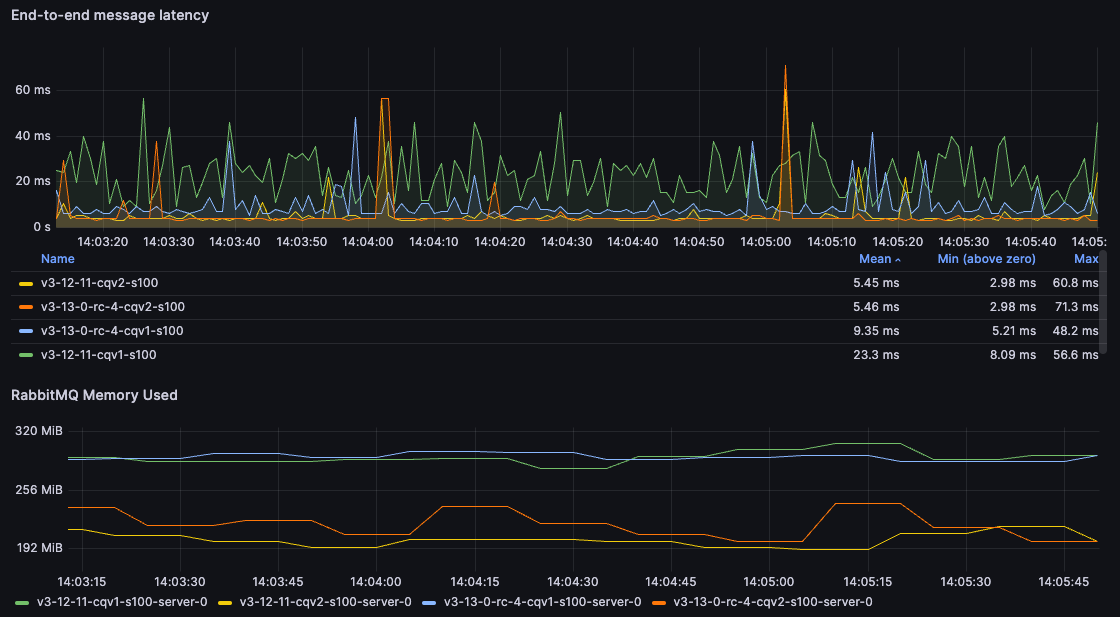
对于 5kB 消息,结果非常接近,事实上,3.12 在此特定测试中获胜(这是我们以后可能会研究的问题)。然而,3.13 仍然可以获得类似的结果,同时内存使用量减少 100MB。

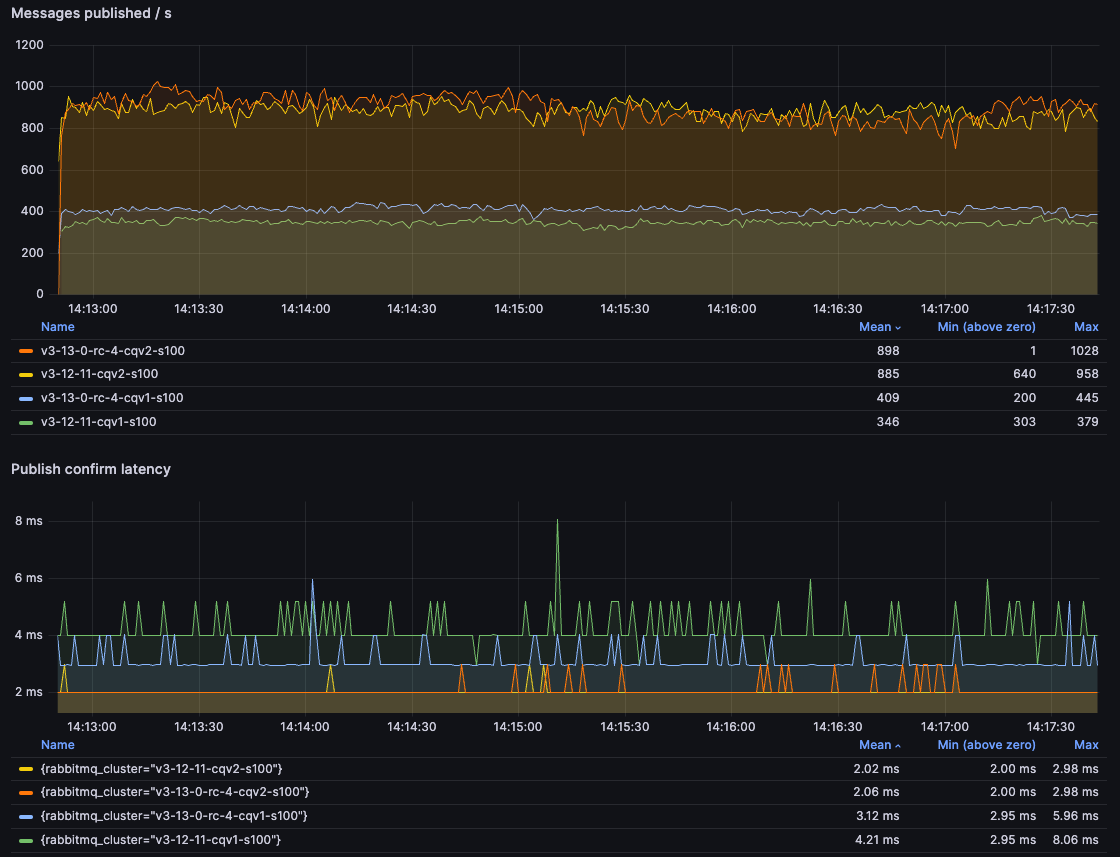
发布者确认延迟
最后,我们来看看一个非常不同的测试。我们不向队列(或队列)灌入消息,而是每次只发布一条消息,等待发布者确认,然后发布下一条消息(有一个消费者存在,但在此并不重要,因为它很容易消费传入的消息)。
对于 100B 消息,我们再次可以看到 CQv2 比 3.12 上的 CQv1 快得多,速度提升了 200% 以上。
对于 5kB 消息,3.13 中新的每个虚拟主机消息存储实现的好处显而易见,改进了 350% 以上。
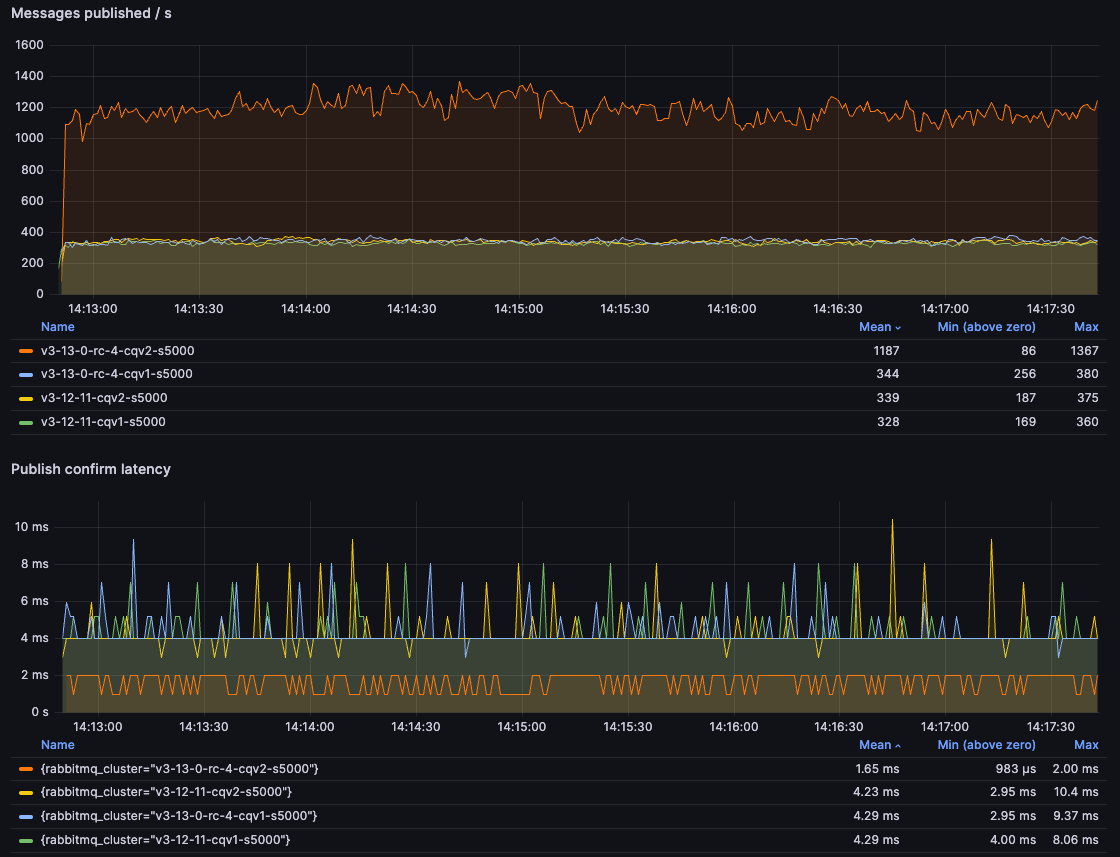
您可能会注意到,对于 5kB 消息,吞吐量实际上比 100B 消息略高。这违反直觉,但实际上并不奇怪。5kB 对于通过网络传输仍然是微不足道的数据量,而消息存储的设计可以更好地处理此类消息。与所有其他事情一样,随着未来的优化以及我们可能会考虑的 queue_index_embed_msgs_below 默认值的更改,这种差异可能会改变。
注意事项
索引版本 2 和新的消息存储实现都应该为大多数用户提供显著的好处。然而,这些实现已经专注于非镜像用例,并且新的消息存储实现是为索引的 v2 版本设计的。虽然它是向后兼容的,并且可以与经典队列 v1 一起使用,但在某些情况下,将 v1 索引与新的消息存储一起使用可能会提供比过去更差的性能或不同的性能特征,如在仅发布测试中所见。因此,强烈建议:
- 测试并对您的应用程序进行基准测试,使用 3.13。
- 比较 v1 和 v2 的性能。
- 如果在无镜像的情况下 v1 的表现更好,请报告,以便我们进行检查。
停留在 v1 可以解决它提供更好性能的情况。然而,旧的实现将在未来被移除,因此您不能长期依赖该解决方法。请报告此类情况,以便将来升级到 v2。
最后的总结
重新设计和替换如此核心的组件,对于一个广泛使用的软件来说是一项非常艰巨的任务。特别感谢Loïc Hoguin,他承担了这个项目,深入研究了代码,有些代码可以追溯到 RabbitMQ 的第一个版本,当时 iPhone 甚至还没有问世。一如既往,我们欢迎测试和反馈,并希望这次升级能为您带来与上面所示相似的益处。