RabbitMQ 4.0:新的仲裁队列特性

RabbitMQ 4.0(目前处于 Beta 阶段)包含新的仲裁队列特性
- 消息优先级
- 消费者优先级与单一活跃消费者结合
- 默认投递限制现在为 20(重大更改!)
- 更快的长队列恢复
消息优先级
消息优先级的支持可能是仲裁队列中最受需求的功能,主要由希望迁移到仲裁队列的现有经典镜像队列用户提出(请记住,4.0 版本已移除对经典队列镜像的支持)。
但是,优先级的支持方式与经典队列处理方式有很大不同。经典队列需要 x-max-priority 参数来定义给定队列的最大优先级数(如果未提供此参数,则队列将平等对待所有消息)。从 0 到 255 的值在技术上是允许的,尽管每个队列的优先级不应超过少数几个。仲裁队列不需要任何预先声明(无需为给定队列启用优先级),但每个队列正好有两个优先级:普通和高。此行为与 AMQP 1.0 规范一致(请参阅AMQP 1.0 规范的第 3.2.1 章)
- 优先级值介于 0 和 4(含)之间被视为普通优先级
- 任何大于 4 的值都被视为高优先级
- 如果发布者未指定消息的优先级,则假定值为
4(普通优先级)
如果仲裁队列同时包含普通和高优先级消息,则消费者将收到两者的混合,比例为每 1 条普通优先级消息对应 2 条高优先级消息。这种方法避免了饥饿,因为无论高优先级消息的数量如何,普通优先级消息的处理都会取得进展。这与经典队列的实现形成对比,经典队列始终会先传递高优先级消息(如果有),因此普通优先级消息可能永远不会被传递(或者更可能的是,它们的传递延迟会非常高)。
以下是此工作原理的可视化表示。在准备此测试之前,我们首先发布了 100k 条普通优先级消息,然后发布了 100k 条高优先级消息。由于仲裁队列在 4.0 之前不支持优先级,因此如果我们在旧版本中执行此操作,然后启动消费者,它将简单地先接收普通优先级消息(因为它们较旧),然后接收所有高优先级消息。使用 4.0,我们可以看到消费者立即开始接收大约每秒 1500 条普通优先级消息,以及两倍的高优先级消息,总共约每秒 4500 条消息(此处实际的投递速率并不重要,它们取决于许多因素;在优先级的上下文中,重要的是 2:1 的高/普通优先级比率)。一旦队列传递完所有高优先级消息,消费者就开始接收每秒约 4500 条普通优先级消息——在此测试场景中,它可以处理的数量。蓝色虚线(右侧有轴刻度)是队列中就绪消息的数量(两个优先级的总和)——我们可以看到它从 200k 开始,最终降至零。
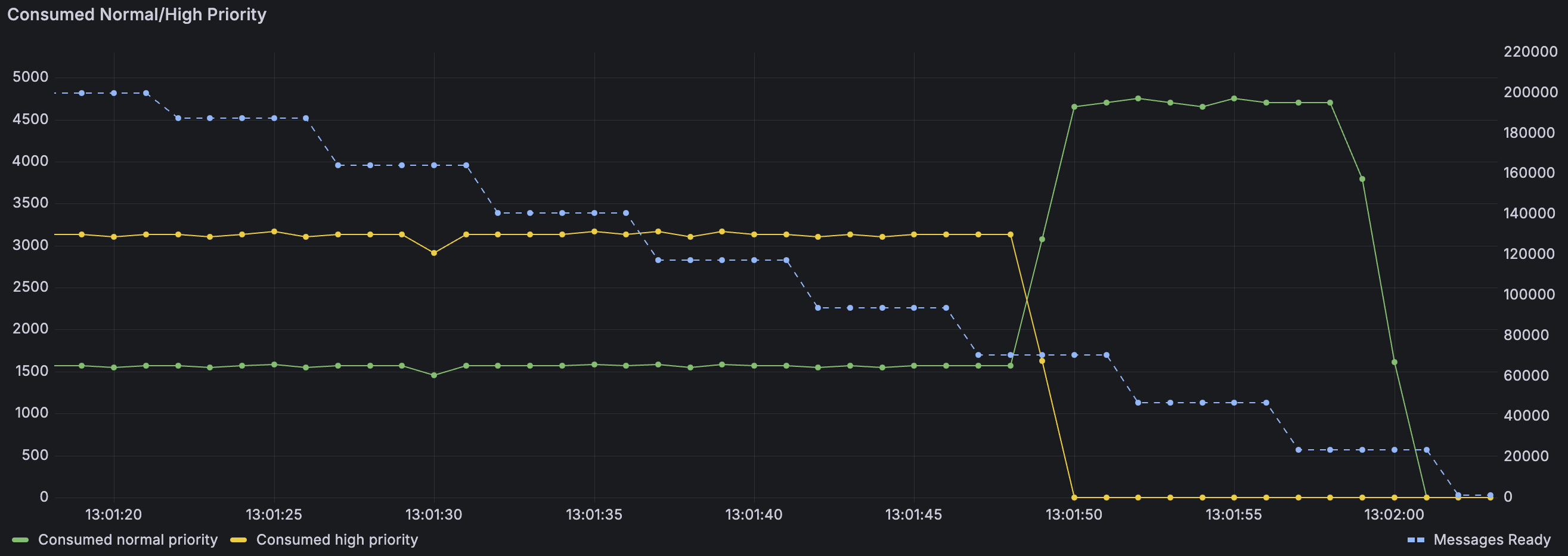
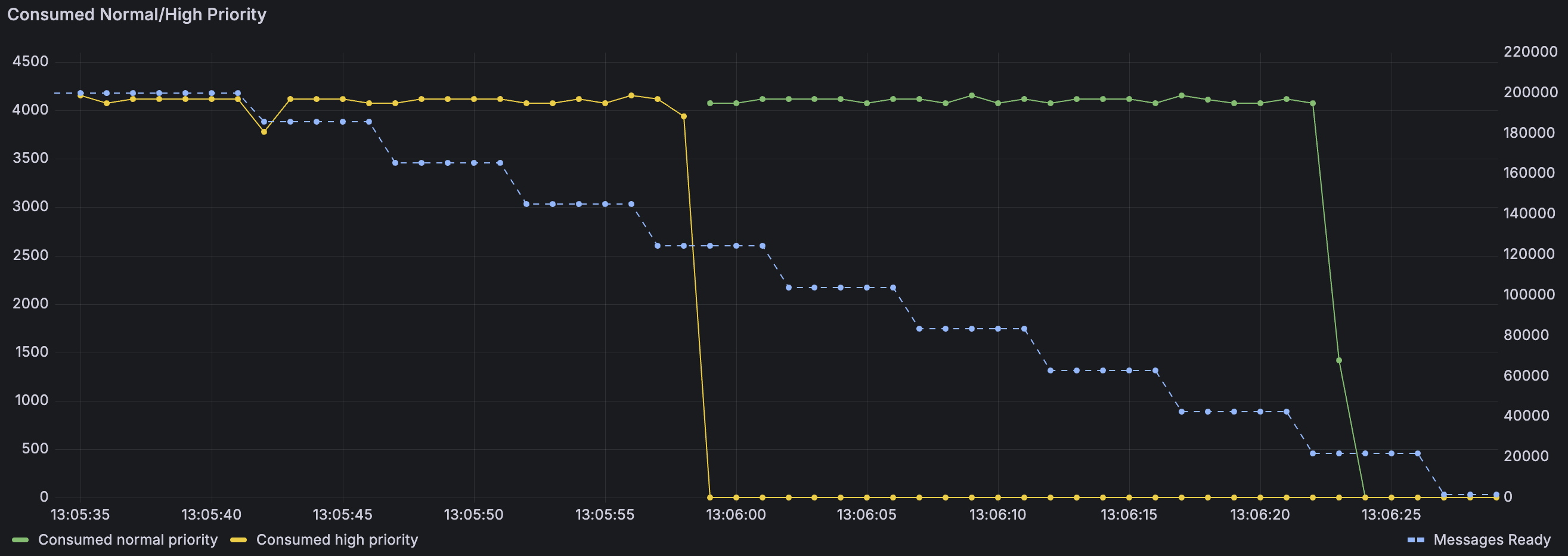
让我们考虑相反的情况——如果我们先发布所有高优先级消息,然后再发布所有普通优先级消息会怎么样?在这种情况下,消费者将按发布顺序接收消息。普通优先级消息根本没有理由超过高优先级消息。
此测试是如何执行的?
对于此测试,我们使用了omq,这是一个针对 AMQP 1.0、MQTT 和 STOMP 的测试客户端。仲裁队列的行为不依赖于使用的协议——使用 AMQP 1.0 仅仅是因为 omq 会按消息优先级发出消息消费指标。
# declare a quorum queue (you can use the Management UI or any other method)
rabbitmqadmin declare queue name=qq queue_type=quorum
# publish normal priority messages (10 publishers, 10k messages each)
omq amqp --publishers 10 --consumers 0 --publish-to /queues/qq --message-priority 1 --pmessages 10000
# publish high priority messages
omq amqp --publishers 10 --consumers 0 --publish-to /queues/qq --message-priority 10 --pmessages 10000
# consume all messages from the queue
omq amqp --publishers 0 --consumers 1 --consume-from /queues/qq --consumer-credits 100
对于第二种情况,只需以相反的顺序运行发布命令。
如果我需要更多控制怎么办?
如果 2:1 的投递比率的两个优先级无法满足您的需求,我们可以推荐两件事
- 重新考虑您的需求。😄使用许多优先级来推断消息投递顺序非常困难。确保所有消息都能足够快地投递,并仅使用优先级来确保在偶尔出现长时间积压的情况下,重要消息可以跳过队列,这可能更容易。
- 如果您确实需要更多优先级和/或更多关于如何处理不同优先级的控制,则使用多个队列是最佳选择。您可以开发一个订阅多个队列的消费者,然后决定从哪个队列消费。
消费者优先级与单一活跃消费者结合
从 RabbitMQ 4.0 开始,仲裁队列在选择单一活跃消费者时将考虑消费者优先级。如果出现更高优先级的消费者(订阅),则仲裁队列将切换到该消费者。如果您有多个队列,每个队列都应该有一个单一消费者,但您不希望应用程序的单个实例成为所有队列的消费者,那么这将特别有用,这在第一个启动的应用程序实例订阅所有这些单一活跃消费者队列时很可能发生。现在,您可以在订阅不同队列时选择不同的优先级,以确保每个实例仅从其“首选”队列消费,并且仅作为其他队列的备用消费者。
为了更好地解释此功能,让我们回顾一下所有活动部件。一个单一活跃消费者是一个队列参数,它可以防止队列向多个消费者投递消息,无论有多少消费者订阅了该队列。一个消费者处于活动状态,所有其他消费者都不处于活动状态。如果活动消费者断开连接,则其他消费者之一将被激活。如果需要维护严格的消息处理顺序,则使用此功能。
消费者优先级允许您指定,而不是以公平的循环方式(这是经典队列和仲裁队列的默认行为)向所有已订阅的消费者投递消息,而是应该优先考虑某个消费者。
在 4.0 版本之前,这些功能实际上是互斥的——如果启用了单一活跃消费者,则新的消费者永远不会变为活动状态,无论其优先级如何,只要以前的消费者保持活动状态即可。从 4.0 开始,如果新消费者的优先级高于当前活动消费者的优先级,则仲裁队列将切换到更高优先级的消费者:它将停止向当前消费者投递消息,等待所有消息被确认,然后停用旧消费者,并激活更高优先级的消费者。
下图显示了此行为。此图上有三个指标
- 绿线显示第一个(默认优先级)消费者消耗的消息数(恰好配置为每秒消费 10 条消息)
- 黄色显示相同的值,但针对第二个更高优先级的消费者
- 蓝色显示未确认的消息数(右侧有轴刻度)
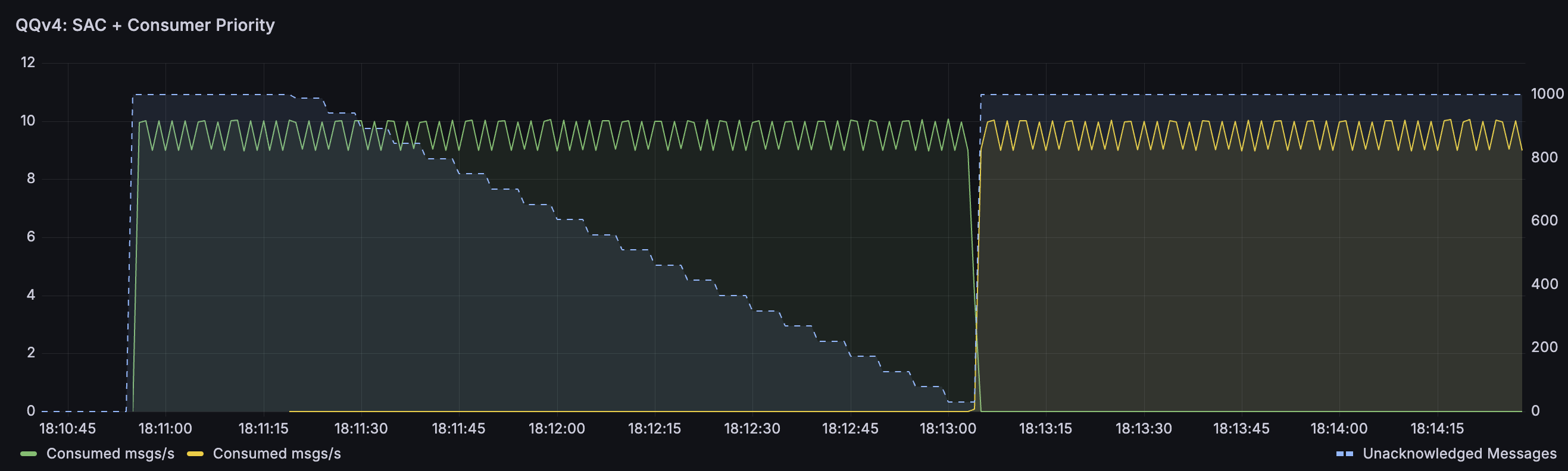
最初,我们只有一个消费者,并且如预期的那样,它每秒消耗 9-10 条消息(9 和 10 之间的这些跳跃仅仅是指标发出和显示方式的结果)。此消费者配置了 1000 条消息的预取,并且由于队列中有许多消息,因此预取缓冲区被最大限度地使用。然后出现黄线,最初为 0 条消息/秒。这是更高优先级的消费者,它已经连接,但尚未激活。从它连接的那一刻起,我们可以看到未确认的消息数量正在下降,因为队列不再向原始消费者投递消息。一旦所有消息都被确认,新消费者就成为单一活跃消费者并接收 1000 条消息,因为这是它的预取值。然后,它会按照配置每秒愉快地消费大约 10 条消息。
此测试是如何执行的?
对于此测试,我们使用了perf-test,这是一个针对 AMQP 0.9.1 的测试客户端。
# Publish 5000 messages to have a backlog (perf-test will declare a quorum queue `qq-sac`)
perf-test --quorum-queue --queue qq-sac --pmessages 5000 --confirm 100 -qa x-single-active-consumer=true --consumers 0
# Start a consumer with the default priority and prefetch of 1000; consume ~10 msgs/s
perf-test --producers 0 --predeclared --queue qq-sac --consumer-latency 100000 --qos 1000
# In another window, some time after starting the first consumer, start a higher priority consumer
perf-test --producers 0 --predeclared --queue qq-sac --consumer-latency 100000 --qos 1000 --consumer-args x-priority=10
一段时间后,您应该会看到第一个消费者停止接收消息(perf-test 没有更多输出),而第二个消费者则接收消息。
此示例中使用的设置是为了突出显示切换过程,并不适合实际场景。如果消费者只能每秒处理 10 条消息,则通常没有理由将预取值配置为 1000 这么高。
投递限制现在默认为 20
这可能会对某些应用程序造成破坏性更改
仲裁队列现在默认将投递限制设置为 20。过去,该限制未设置,因此仲裁队列会无限期地尝试投递,直到消息被消费者确认或丢弃。这可能导致消息卡在队列中且无法投递的情况。
此更改的缺点是,如果未配置死信队列,则消息将在 20 次尝试后被丢弃。因此,强烈建议为所有仲裁队列配置死信队列。
长队列的更快恢复
这与其说是一个功能,不如说是一个内部更改,但绝对值得一提。到目前为止,如果 RabbitMQ 节点重新启动,则该节点上的所有仲裁队列都必须读取从上次快照以来的所有数据(Raft 日志),以重建其内存状态。例如,如果您现在将数百万条消息发布到仲裁队列,然后重新启动节点,您将看到节点启动后,队列将在相当长一段时间内(至少几秒钟)报告0个就绪消息,并且您将无法开始使用这些消息。队列尚未准备好提供服务 - 它仍在从磁盘读取数据(注意:这并不意味着所有这些数据都保存在内存中,绝大多数数据都没有,但队列数据的索引/摘要是)。从 RabbitMQ 4.0 开始,仲裁队列会创建包含特定时间点队列状态的检查点文件。启动时,队列可以读取最新的检查点,以及从该时间点开始的 Raft 日志的一部分。这意味着仲裁队列启动所需的时间大大减少了。
例如,一台具有一个包含 1000 万条 12 字节消息的仲裁队列的 RabbitMQ 节点在我的机器上大约需要 30 秒才能启动。使用 RabbitMQ 4.0,它只需一小部分时间。
您可能想知道快照和检查点之间有什么区别。在许多方面,它们是相同的 - 它们实际上共享写入磁盘的代码。区别在于,只有在截断 Raft 日志时才会创建快照。对于许多常见的队列用例,这都是必需的 - 旧消息被消费,我们创建一个不再包含它们的快照,然后我们截断日志。此时,队列不再记得这些消息曾经存在过。另一方面,当我们无法截断日志时,检查点会定期创建。测试用例场景就是一个很好的例子 - 由于我们没有消费任何消息,因此最旧的消息仍然存在,我们不能忘记它们。但检查点仍然允许队列更快地启动。当日志被截断时(在此示例中 - 在一些较旧的消息被消费后),检查点可以提升为快照。
我如何尝试?
再次,我们将使用perf-test来声明队列并发布消息
# Publish 10 million 12-byte messages (feel free to play with other values)
perf-test --quorum-queue --queue qq --consumers 0 --pmessages 5000000 --confirm 1000 --producers 2
# restart the node
rabbitmqctl stop_app && rabbitmqctl start_app
# list the queues (repeat this command until the number of messages is 10 million instead of 0)
rabbitmqctl list_queues
总结
RabbitMQ 4.0 是 RabbitMQ 的一个重要里程碑。随着经典队列镜像的移除,仲裁队列成为高可用、复制队列的唯一选择(注意:流也是高可用且复制的,但从技术上讲不是队列;尽管如此,对于过去使用经典镜像队列的一些用例,它们可能仍然是一个不错的选择)。多年来,仲裁队列提供了比镜像队列更高的数据安全保障和更好的性能,并且通过这些最新的改进,它们在更广泛的场景中变得更加健壮和高效。
您现在可以试用 RabbitMQ 4.0 Beta 版:https://github.com/rabbitmq/rabbitmq-server/releases/tag/v4.0.0-beta.5