使用火焰图提升 RabbitMQ 性能

近期 Erlang/OTP 版本附带了 Linux perf 支持。这篇博客文章提供了关于如何在 RabbitMQ 中创建 CPU 和内存 火焰图 的逐步指南,以快速准确地检测性能瓶颈。我们还提供了火焰图如何帮助我们提高 RabbitMQ 中的消息吞吐量的示例。
概述
在 Erlang/OTP 24 之前,许多工具,包括 fprof、eprof 和 cprof,已经可以用来 分析 Erlang 代码。然而,这些工具都无法以最小的开销生成调用图。
Erlang/OTP 24 引入了 即时 (JIT) 编译器。JIT 编译器不是解释代码,而是生成机器代码。该机器代码可以被原生工具检测。具体来说,Erlang/OTP 24 附带了 Linux perf 支持。Perf 可以分析机器代码并生成开销很低的调用图,因为性能分析发生在 Linux 内核中。
这是 Erlang/OTP 24 中的一项重要功能,因为它允许任何 Erlang 程序高效且精确地检测其源代码中的瓶颈。
一旦程序被分析并生成了其调用图,这些堆栈跟踪就可以通过各种工具进行可视化和分析。最流行的工具是火焰图。火焰图由 Brendan Gregg 在 2011 年发明。
虽然多年前就可以为分析后的 Erlang 代码创建火焰图,但现在的新变化是,这些火焰图现在可以在不显着减慢 Erlang 程序速度的情况下,创建具有准确调用堆栈报告的火焰图。
在这篇博客文章中,我们将演示如何创建 CPU 和内存火焰图,解释如何解读它们,并展示它们如何帮助我们提高 RabbitMQ 性能。
CPU 火焰图
为了使用 Linux perf 分析 RabbitMQ,我们需要在 Linux 操作系统上运行 RabbitMQ。(本博客文章中的命令在 Ubuntu 22.04 LTS 上运行。)
物理 Linux 服务器是最佳选择,因为会有更多的硬件计数器。但是,Linux 虚拟机 (VM) 也足够入门。请记住,虚拟机可能会有一些限制。例如,在某些虚拟化环境中,RabbitMQ 中大量使用的 fsync 系统调用可能不起作用。
执行以下步骤来创建我们的第一个火焰图
- 安装 Erlang/OTP 25.0(其中包含 JIT 中支持帧指针)。这里,我们使用 kerl
kerl build 25.0 25.0
kerl install 25.0 ~/kerl/25.0
source ~/kerl/25.0
- 安装 Elixir。这里,我们使用 kiex
kiex install 1.12.3
kiex use 1.12.3
- 克隆 RabbitMQ 服务器
git clone git@github.com:rabbitmq/rabbitmq-server.git
cd rabbitmq-server
git checkout v3.10.1
make fetch-deps
git -C $(pwd)/deps/seshat checkout 68f2b9d4ae7ea730cef613fd5dc4456e462da492
- 由于我们将要对 RabbitMQ 进行压力测试,并且我们不希望 RabbitMQ 通过保护自己免受过载而人为地减慢我们的性能测试,因此我们将内存阈值提高以避免达到 内存警报,并将信用 流控制 设置提高到其默认设置的 4 倍。您也可以尝试将
credit_flow_default_credit设置为{0, 0},这将完全禁用基于信用的流控制。创建以下 advanced.config 文件
[
{rabbit,[
{vm_memory_high_watermark, {absolute, 15_000_000_000}},
{credit_flow_default_credit, {1600, 800}}
]}
].
- 启动 RabbitMQ 服务器。我们不启用任何 RabbitMQ 插件(因为插件可能会对性能产生负面影响,尤其是一些插件在具有数千个对象(如队列、交换器、通道等)的场景中查询统计信息)。我们设置 Erlang 模拟器标志
+JPperf true以启用对 Linux perf 的支持,并设置+S 4以创建 4 个调度器线程。
make run-broker PLUGINS="" RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS="+JPperf true +S 4" \
RABBITMQ_CONFIG_FILE="advanced.config" TEST_TMPDIR="test-rabbit"
- 在第二个 shell 窗口中,启动 RabbitMQ PerfTest。在我们的示例中,PerfTest 创建了一个生产者,该生产者以最多 2,000 条未确认的消息向名为
my-stream的流发布消息 60 秒。
# Install PerfTest
wget -O perf-test https://github.com/rabbitmq/rabbitmq-perf-test/releases/download/v2.17.0/perf-test_linux_x86_64
chmod +x perf-test
# Start PerfTest client generating load against RabbitMQ server
./perf-test --queue my-stream --queue-args x-queue-type=stream --auto-delete false --flag persistent \
--producers 1 --confirm 2000 --consumers 0 --time 60
- 当 PerfTest 运行时,在第三个 shell 窗口中,记录一个配置文件,该文件以 999 赫兹 (
--freq) 的频率采样 RabbitMQ 服务器进程 (--pid) 的 CPU 堆栈跟踪,记录内核空间和用户空间 (-g) 的调用图,持续 30 秒。
# Install perf, e.g. on Ubuntu:
# sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`
sudo perf record --pid $(cat "test-rabbit/rabbit@$(hostname --short)/rabbit@$(hostname --short).pid") --freq 999 -g -- sleep 30
- 一旦第二个 shell 窗口中的 60 秒 PerfTest 运行完成,检查结果。在这台机器上,我们获得的平均发送速率约为每秒 103,000 条消息。此结果在您的机器上可能会更慢或更快。
test stopped (Reached time limit)
id: test-114336-500, sending rate avg: 103132 msg/s
id: test-114336-500, receiving rate avg: 0 msg/s
- 之前的 perf 命令输出文件
perf.data。按照 Erlang 文档 中的描述,从此数据创建 CPU 火焰图
git clone git@github.com:brendangregg/FlameGraph.git
# Convert perf.data (created by perf record) to trace output
sudo perf script > out.perf
# Collapse multiline stacks into single lines
./FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# Merge scheduler profile data
sed -e 's/^[0-9]\+_//' -e 's/^erts_\([^_]\+\)_[0-9]\+/erts_\1/' out.folded > out.folded_sched
# Create the SVG file
./FlameGraph/flamegraph.pl --title="CPU Flame Graph" out.folded_sched > cpu.svg
在浏览器中打开生成的 cpu.svg 文件应该会向您显示类似于以下的 CPU 火焰图

如果您没有运行上述步骤,请单击 此处 在浏览器中将图 1 作为 SVG 文件打开。
CPU 火焰图的解读如下
- 每个框都是一个堆栈帧。
- SVG 是交互式的。尝试单击堆栈帧以放大到特定的调用图。在 SVG 的左上方单击
Reset Zoom返回。 - 颜色(黄色、橙色、红色)没有意义。
- 高度表示调用堆栈的深度。“高塔”可能代表递归函数调用。在大多数情况下,具有一定程度的递归是完全正常的。在上面的 SVG 中,单击最高塔(图表的左半部分)中的堆栈帧,您将看到名为
lists:foldr_1/3的函数导致了这种递归。 - 同一级别堆栈帧的水平顺序是按字母顺序排列的。因此,水平顺序不代表时间。
- 最重要的特征是注意框的宽度。宽度决定了函数在 CPU 上运行的频率。特别是,注意图表顶部的宽堆栈帧,因为它们直接消耗大量 CPU 周期!
- 所有 Erlang 函数都以美元符号 (
$) 为前缀。 - 在火焰图的右上角,您可以单击灰色的
Search图标。如果您在搜索框中输入正则表达式^\$(意思是“匹配所有以美元符号开头的内容”),则所有 Erlang 函数都将以紫色突出显示。
毫不奇怪,最难的部分是根据火焰图提供的见解来优化性能。总的来说,两种策略已被证明是成功的
- 运行您知道对 RabbitMQ 有问题的负载。例如,如果 RabbitMQ 运行缓慢,或者对于特定的客户端负载消耗大量内存,请运行该客户端负载(例如使用 PerfTest),使用 Linux perf 记录 RabbitMQ 服务器的配置文件,并创建火焰图。火焰图很可能呈现瓶颈。
- 尝试探索性地优化性能。这就是我们在这篇博客文章中要做的。
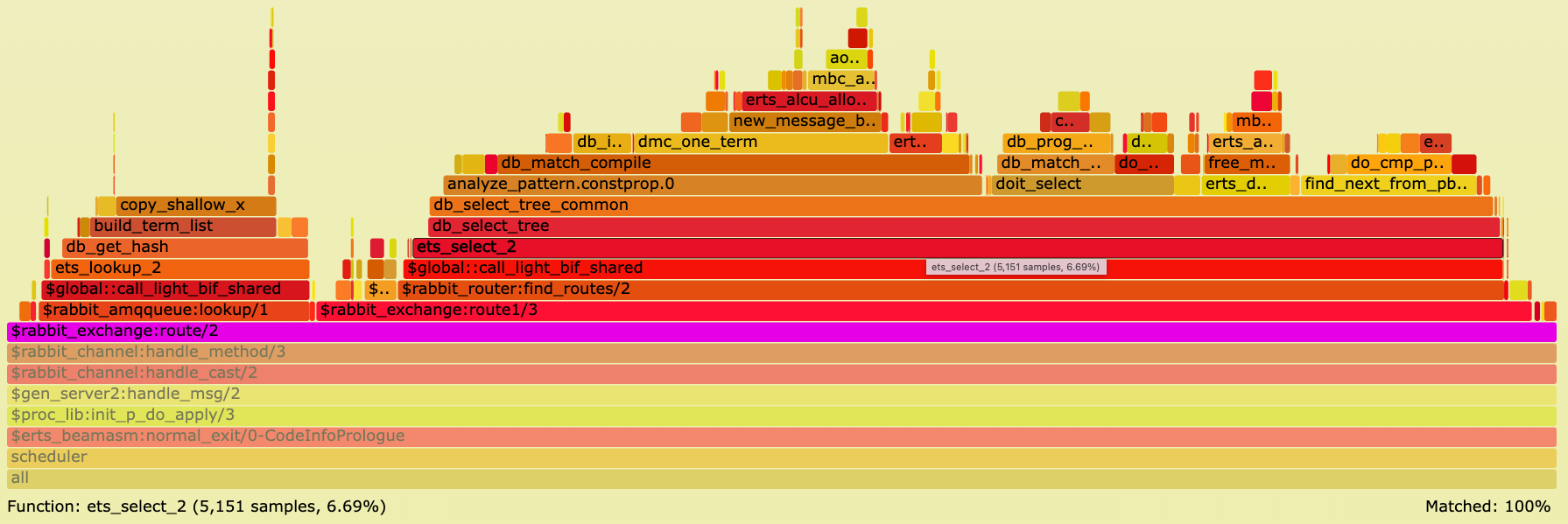
我们启动了 PerfTest,其中一个发布者向流发送消息,而没有意识到任何性能问题。单击一些堆栈帧并检查哪些函数消耗 CPU 时间,令人惊讶的是,函数 rabbit_exchange:route/2 花费了 9.5% 的 CPU。在上面的 SVG 中搜索该函数以将其突出显示为紫色,然后单击紫色框以放大(或单击 此处)。它将向您显示以下图像
在 shell 中执行以下命令以列出 RabbitMQ 绑定
./sbin/rabbitmqctl list_bindings --formatter=pretty_table
Listing bindings for vhost /...
┌─────────────┬─────────────┬──────────────────┬──────────────────┬──────────────────────────────────────┬───────────┐
│ source_name │ source_kind │ destination_name │ destination_kind │ routing_key │ arguments │
├─────────────┼─────────────┼──────────────────┼──────────────────┼──────────────────────────────────────┼───────────┤
│ │ exchange │ my-stream │ queue │ my-stream │ │
├─────────────┼─────────────┼──────────────────┼──────────────────┼──────────────────────────────────────┼───────────┤
│ direct │ exchange │ my-stream │ queue │ f809d879-b5ad-4159-819b-b39d6b50656a │ │
└─────────────┴─────────────┴──────────────────┴──────────────────┴──────────────────────────────────────┴───────────┘
PerfTest 客户端创建了一个流(队列)my-stream。第一个绑定显示每个队列都自动绑定到默认交换器(空字符串 "" 的交换器)。PerfTest 还创建了一个名为 direct 的直接交换器,并将流绑定到该交换器,并带有一些随机路由键。
尽管只有 2 个绑定(路由),但 RabbitMQ 在函数 rabbit_exchange:route/2 中花费了大量 CPU 时间 (9.5%) - 一个路由消息的函数 - 并且在函数 ets:select/2 中花费了 6.69% 的 CPU 时间。
我们还在函数堆栈跟踪中看到了一个宽框 db_match_compile,这意味着相同的 匹配规范 会为每条路由的消息编译。
Ets 表是一个单键表(哈希表或按键排序的树),应按此方式使用。换句话说,尽可能使用键来查找事物。
此 PR 添加了一个 Mnesia 索引表,其表键是 Erlang 元组 {SourceExchange, RoutingKey},以便路由目标将通过该键查找。
在我们的示例中,这意味着不再调用使用昂贵的匹配规范的 ets:select/2,而是使用 ets:loookup_element/3 通过提供表键 {direct, f809d879-b5ad-4159-819b-b39d6b50656a} 来查找路由目标 my-stream。
使用 Ctrl+g q 停止 RabbitMQ 服务器并删除其数据目录
rm -rf test-rabbit
让我们检出 master 分支中的一个提交(在撰写本文时的 2022 年 5 月),其中包括 PR #4606
git checkout c22e1cb20e656d211e025c417d1fc75a9067b717
通过重复上述步骤 5 - 9 重新运行相同的场景。
打开新的 CPU 火焰图并搜索堆栈帧 rabbit_exchange:route/2(或单击 此处)

通过新的优化,该函数的 CPU 使用率从 9.5% 降至仅 2.5%。
由于此优化,PerfTest 输出的平均发送速率约为每秒 129,000 条消息。与此更改之前的每秒约 103,000 条消息相比,单个发布者的发送吞吐量提高了每秒 26,000 条消息或 25%。这种加速适用于通过直接交换器通过 AMQP 0.9.1、AMQP 1.0、STOMP 和 MQTT 发送的发布者。
如 PR 中所述,当发送到经典队列或仲裁队列时,端到端(从客户端到 RabbitMQ 服务器)发送吞吐量提高较低(每秒 20,000 条消息或 15%)(因为它们存储消息的速度比流慢),并且当有许多绑定时,吞吐量提高较高(每秒 90,000 条消息或 35%),因为在此更改之后,路由表查找以恒定时间通过表键发生。
总结一下,在本节中,我们为常见的 RabbitMQ 工作负载创建了一个 CPU 火焰图。CPU 火焰图精确地显示了哪些函数需要 CPU 使用率:框越宽,需要的 CPU 时间越多。仅通过探索堆栈帧,我们就能够检测到路由是瓶颈。意识到这个瓶颈后,我们可以随后通过直接交换器类型加速路由,从而将发送吞吐量提高 15% - 35%。
通过分析 CPU 火焰图来降低 RabbitMQ 中 CPU 使用率的更多示例可以在 PR #4787、#3934 和 rabbitmq/ra #272 中找到。
内存火焰图
火焰图可视化分层数据。在上一节中,此数据表示消耗 CPU 时间的代码路径。本节是关于表示导致内存使用量的代码路径的数据。
Brendan Gregg 提出了不同的跟踪方法来分析内存使用情况
- 分配器,例如 malloc() 库函数。glibc 的
malloc()实现使用系统调用 brk() 和 mmap() 请求内存。 brk()系统调用通常指示内存增长。mmap()系统调用由 glibc 用于更大的分配。mmap()在虚拟地址空间中创建一个新的映射。除非随后使用munmap()释放,否则mmap()火焰图可能会检测到增长或泄漏内存的函数。- 页面错误指示物理内存使用情况。
并非所有 Erlang 内存分配都可以通过这些方法之一进行跟踪。例如,Erlang VM(在启动时)已预先分配的内存无法跟踪。此外,为了减少系统调用的数量,一些通过 mmap() 分配的内存段在销毁之前会被 缓存。新分配的段从该缓存中提供,因此无法使用 Linux perf 进行跟踪。
在本节中,我们创建一个 mmap() 火焰图(方法 3)。
停止 RabbitMQ 服务器,删除其数据目录,检出标签 v3.10.1,并按照上一节中的步骤 5 启动 RabbitMQ 服务器。
在第二个 shell 窗口中,启动 PerfTest,使用 1 个发布者向流发送消息 4 分钟
./perf-test --queue my-stream --queue-args x-queue-type=stream --auto-delete false --flag persistent \
--producers 1 --consumers 0 --time 240
4 分钟后,我们看到 PerfTest 客户端发布了超过 3200 万条消息。
./sbin/rabbitmqctl list_queues name type messages --formatter=pretty_table
Timeout: 60.0 seconds ...
Listing queues for vhost / ...
┌───────────┬────────┬──────────┐
│ name │ type │ messages │
├───────────┼────────┼──────────┤
│ my-stream │ stream │ 32748214 │
└───────────┴────────┴──────────┘
启动 4 个消费者,每个消费者消费这些消息 90 秒。
./perf-test --queue my-stream --queue-args x-queue-type=stream --auto-delete false --flag persistent \
--producers 0 --consumers 4 --qos 10000 --multi-ack-every 1000 -consumer-args x-stream-offset=first --time 90
当 PerfTest 运行时,在第三个 shell 窗口中,记录一个配置文件,该文件跟踪 mmap() 系统调用
sudo perf record --pid $(cat "test-rabbit/rabbit@$(hostname --short)/rabbit@$(hostname --short).pid") \
--event syscalls:sys_enter_mmap -g -- sleep 60
90 秒后,PerfTest 输出的平均接收速率约为每秒 287,000 条消息。
test stopped (Reached time limit)
id: test-102129-000, sending rate avg: 0 msg/s
id: test-102129-000, receiving rate avg: 287086 msg/s
之前的 Linux perf 命令写入文件 perf.data。创建一个 mmap() 火焰图
sudo perf script > out.perf
# Collapse multiline stacks into single lines
./FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# Merge scheduler profile data
sed -e 's/^[0-9]\+_//' out.folded > out.folded_sched
# Create the SVG file
./FlameGraph/flamegraph.pl --title="mmap() Flame Graph" --color=mem --countname="calls" out.folded_sched > mmap.svg
在浏览器中打开生成的 mmap.svg 文件并搜索 amqp10_binary_parser 应该会向您显示类似于以下的 mmap() 火焰图

如果您没有运行上述步骤,请单击 此处 在浏览器中将图 4 作为 SVG 文件打开。
与 CPU 火焰图一样,除了紫色突出显示搜索匹配项外,内存火焰图中的颜色(绿色、蓝色)没有意义。
火焰图显示,所有 mmap() 系统调用中有 10.1% 发生在模块 amqp10_binary_parser 中。PR #4811 通过遵循 匹配二进制文件效率指南 来优化该模块中的代码,即通过重用匹配上下文而不是创建新的子二进制文件。
停止 RabbitMQ 服务器。无需删除其数据目录,检出包含 PR #4811 的标签 v3.10.2。重复之前的步骤,启动 RabbitMQ 服务器,并使用 4 个消费者从流中消费,同时使用 Linux perf 记录 mmap() 系统调用。
当 PerfTest 在 90 秒后完成时,这次输出的平均接收速率约为每秒 407,000 条消息。与 v3.10.1 中的 287,000 条消息相比,接收吞吐量提高了约每秒 120,000 条消息或约 42%。
再次创建 mmap() 火焰图,如之前所做的那样,并搜索 amqp10_binary_parser。
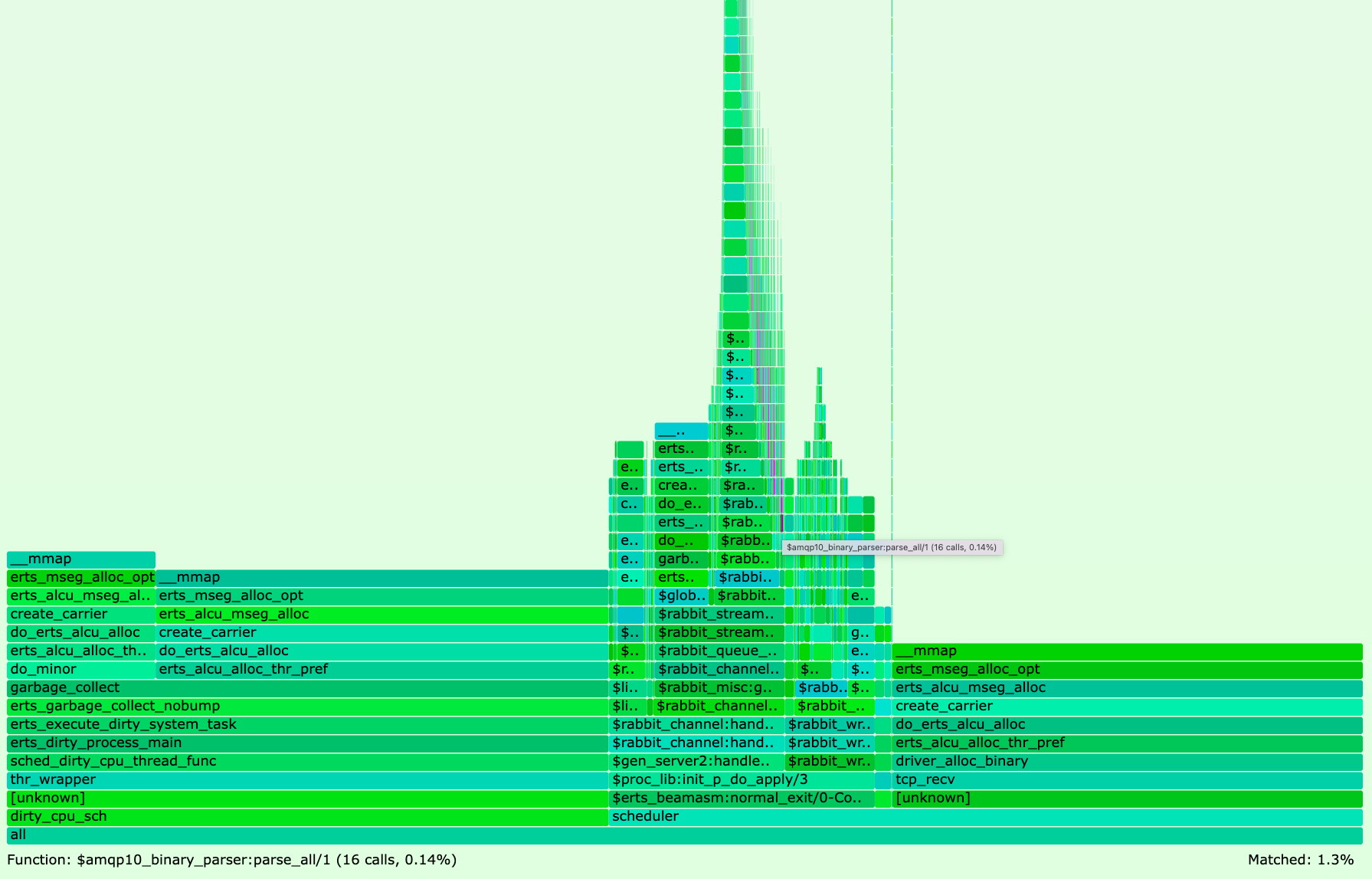
如果您没有运行上述步骤,请单击 此处 在浏览器中将图 5 作为 SVG 文件打开。
二进制匹配优化将模块 amqp10_binary_parser 的 mmap() 系统调用从 v3.10.1 中的 10.1% 降低到 v3.10.2 中的 1.3%。
总结一下,在本节中,我们为常见的 RabbitMQ 工作负载创建了一个 mmap() 内存火焰图。mmap() 火焰图精确地显示了哪些函数导致 mmap() 系统调用:框越宽,它们触发的 mmap() 系统调用越多。仅通过探索堆栈帧,我们就能够检测到 AMQP 1.0 二进制解析是一个瓶颈。意识到这个瓶颈后,我们可以随后加速 AMQP 1.0 二进制解析,从而将通过 AMQP 0.9.1 从流接收的吞吐量提高约 42%。
通过探索 mmap() 火焰图来减少 RabbitMQ 中 mmap() 系统调用的另一个示例可以在 PR #4801 中找到。
创建页面错误火焰图(方法 4)的工作方式与创建 mmap() 火焰图(方法 3)相同。唯一的区别是将 Linux perf 标志 --event syscalls:sys_enter_mmap 替换为 --event page-faults。PR #4110 中可以找到页面错误火焰图如何帮助提高 RabbitMQ 性能的示例,其中新的队列实现维护自己的队列长度,从而消耗更少的物理内存。
总结
自从 Erlang/OTP 25 以来,我们可以高效且精确地检测 RabbitMQ 中消耗大量 CPU 或内存的堆栈跟踪,方法是使用 Linux perf 并创建火焰图。一旦确定了瓶颈,我们就可以优化代码路径,从而提高 RabbitMQ 性能。
不同的客户端工作负载将导致 RabbitMQ 服务器的不同 CPU 和内存使用模式。无论您遇到 RabbitMQ 运行缓慢、怀疑 RabbitMQ 泄漏内存,还是只是想加速 RabbitMQ,我们都鼓励您创建火焰图以查明性能瓶颈。
与本博客文章中对单个 RabbitMQ 节点进行的一次性性能分析相反,我们还在试验跨 RabbitMQ 集群中多个节点的连续性能分析。未来,在生产环境中持续分析 RabbitMQ 的一种潜在方法是在 Kubernetes 上使用 rabbitmq/cluster-operator 部署 RabbitMQ,同时使用 Parca Agent 进行性能分析。