RabbitMQ 3.11 功能预览:Super Streams

RabbitMQ 3.11 将带来一个在其历史上名称最酷的功能之一:Super Streams。Super Streams 是一种通过将大型流分区为较小流来扩展的方法。它们与Single Active Consumer集成,以在分区内保留消息顺序。
这篇博文概述了 Super Streams 及其带来的用例。继续阅读以了解更多信息,我们重视您的反馈,以使此功能尽善尽美。
概述
Super stream 是一种逻辑流,由单独的、常规的 streams 组成。它是一种在 RabbitMQ Streams 中实现发布和消费扩展的方法:一个大的逻辑流被划分为多个分区流,将存储和流量分散到多个集群节点上。
Super stream 仍然是一个逻辑实体:应用程序通过客户端库的智能实现,将其视为一个“大”流。Super stream 的拓扑基于 AMQP 0.9.1 模型,即交换器、队列以及它们之间的绑定。
下图展示了一个由 3 个分区组成的 invoices super stream。它由一个 invoices 交换器和绑定到它的 3 个流定义。

消息不经过交换器,而是直接进入分区流。但是 客户端库 使用拓扑信息来确定消息的路由目标和消费来源。
让我们来谈谈大家最关心的问题:它与 Kafka 相比如何?我们可以将 super stream 与 Kafka 主题进行比较,将 stream 与 Kafka 主题的分区进行比较。然而,RabbitMQ stream 是一个一等公民,拥有独立的名称,而 Kafka 分区是 Kafka 主题的子项。这种解释遗漏了大量的细节,没有真正的一对一映射,但对于本文的论点来说已经足够准确了。
Super streams 还利用 单活动消费者 来保证在消费者处理期间分区内消息的顺序。
请注意,super streams 并不会弃用单独的 streams 或使其变得无用。它们也不是 streams 的 2.0 版本,因为我们最初就设计 streams 的方式存在一些问题。Super streams 建立在 streams 之上,带来了自己的一套功能和能力。您仍然可以在它们适用时继续使用单独的 streams,也可以探索 super streams 来满足更苛刻的用例。
发布到 Super Stream
应用程序发布到 super stream 的消息必须进入其中一个分区。应用程序可以通过客户端库的帮助来选择分区,而代理不负责路由。这非常灵活,并避免了服务器端的瓶颈。
应用程序必须提供至少一个信息:从消息中提取的路由键。以下代码片段展示了应用程序如何使用 stream Java 客户端库提供此代码。
Producer producer = environment.producerBuilder()
.superStream("invoices") // set the super stream name
.routing(message -> message.getProperties().getMessageIdAsString()) // extract routing key
.producerBuilder()
.build();
producer.send(...);
发布与使用 常规 stream 保持一致,只是生产者配置略有不同。发布到 stream 或 super stream 对应用程序代码的影响不大。
消息去哪里了?在这种情况下,库通过使用 MurmurHash3 对路由键进行哈希来选择 stream 分区。此哈希函数提供了良好的均匀性、性能和可移植性,使其成为一个不错的默认选择。在本例中,路由键是发票 ID,因此发票应该均匀分布在各个分区中。如果路由键是客户 ID,我们将保证给定客户的所有发票都在同一个分区中。这是一个可以利用的用例:在给定时间段内按客户进行报告,并附带相应的 基于时间戳的偏移量指定。
说到处理,让我们来看看如何从 super stream 中消费。
从 Super Stream 消费
Super stream 的分区是常规 streams,因此应用程序可以像往常一样从它们进行消费。但这需要了解 super stream 的拓扑,而我们将其宣传为一个逻辑实体,即应用程序将其视为一个单独的 stream。幸运的是,客户端库可以在代理的帮助下实现这一点,从而对应用程序来说一切都是透明的。
客户端库可以实现一个 众所周知的设计模式,并提供一个复合消费者,该消费者同时从 super stream 的所有分区进行消费。
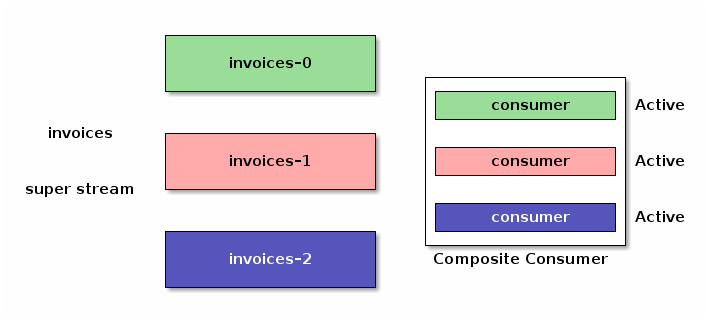
以这种方式实现的复合消费者存在局限性:如果您启动同一应用程序的多个实例以实现冗余和可扩展性,它们将消费相同的消息,导致处理重复。所有这些都需要协调,幸运的是,我们可以将 单活动消费者 的语义应用于我们的 super stream 复合消费者。
现在启用了单活动消费者,我们的复合消费者的实例将与代理协调,以确保在任何给定时间只有一个消费者在某个分区上活动。
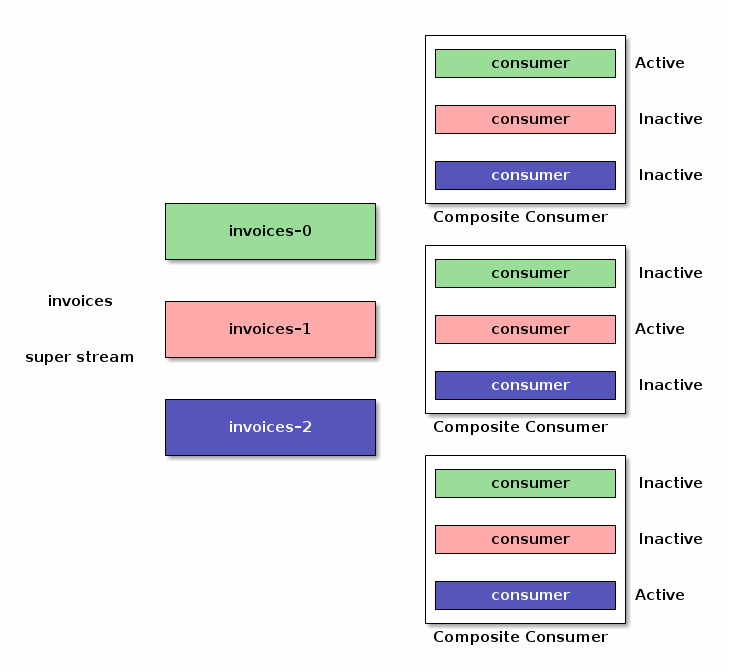
好消息是,所有这些都是实现细节。应用程序实例可以启动和关闭,消费者将根据单活动消费者语义进行激活或停用。
这在代码中如何体现?以下是 stream Java 客户端的一个示例。
Consumer consumer = environment.consumerBuilder()
.superStream("invoices") // set the super stream name
.name("application-1") // set the consumer name (mandatory)
.singleActiveConsumer() // enable single active consumer
.messageHandler((context, message) -> {
// message processing
})
.build();
这与 常规 stream 的消费者 类似,只有配置会改变,更重要的是消息处理代码保持不变。
总结
我们在本文中介绍了Super Streams,这是即将发布的 RabbitMQ 3.11 版本中的一项新功能。Super Streams 是分区流,它们为 RabbitMQ Stream 带来了可扩展性。结合 单活动消费者,它们保证在分区内按照发布顺序处理消息。
本文有一个 配套示例项目,提供了分步演示来阐释文中介绍的功能。请务必参考一下!
我们很高兴与 RabbitMQ 社区分享这项新功能,并迫不及待地希望在 RabbitMQ 3.11 今年晚些时候 GA 之前收到一些 反馈。