仲裁队列和流量控制 - 压力测试
在上一篇文章中,我们对单个队列运行了一些简单的基准测试,以了解流水线发布者确认和消费者确认对流量控制的影响。
具体来说,我们研究了
- 发布者:限制飞行中消息的数量(已发送但正在等待确认的消息)。
- 消费者:预取(broker 将在通道上允许的飞行中消息的数量)
- 消费者:确认间隔(多重标志的使用)
不出所料,我们看到,当我们限制发布者和 broker 一次只能处理少量飞行中消息时,吞吐量很低。 当我们增加这个限制时,吞吐量增加了,但仅增加到一定程度,之后我们没有看到更多的吞吐量增长,而是延迟增加了。 我们还看到,允许消费者使用多重标志对吞吐量有利。
在这篇文章中,我们将研究相同的三个设置,但使用更多的客户端、更多的队列和不同的负载量,包括压力测试。 我们将看到发布者确认和消费者确认在流量控制中发挥作用,以帮助防止 broker 过载。
关于数据安全,客户端发挥着作用,它们必须正确使用确认和 ack 才能实现至少一次处理。 同样,成千上万的客户端不应期望用负载冲击 broker,并且不承担任何后果。
请注意,这篇文章中有相当多的细节,因此在开始之前,请确保您手边有饮料。
机械共情
我真的很喜欢“机械共情”这个词。 当你缓慢驾驶赛车时,几乎可以为所欲为。 只有当你将汽车推向极限时,你才需要开始倾听它,感受振动并进行相应调整,否则它会在比赛结束前抛锚。
同样,对于 RabbitMQ,如果你的负载很低,那么你可以轻松应对很多情况。 你可能看不到更改这三个设置或完全使用确认(至少在性能方面)的太多影响。 只有当你将集群压力测试到极限时,这些设置才会变得真正重要。
优雅降级
当系统接收的数据量超过其处理能力时,应该怎么做?
- 答案 1:接受所有数据,最终变成一堆燃烧的比特。
- 答案 2:提供吞吐量大幅波动,延迟变化巨大的情况。
- 答案 3:限制数据入口速率,并提供稳定的吞吐量和低延迟。
- 答案 4:优先考虑入口而不是出口,吸收数据,仿佛这只是负载峰值,导致高延迟,但更好地跟上入口速率。
在 RabbitMQ,我们会认为答案 3 和 4 是合理的期望,而没有人想要 1 和 2。
对于答案 4,何时峰值不再是峰值? 短暂的峰值何时变成长期问题? 这样的系统应该如何优先考虑发布者而不是消费者? 这是一个艰难的选择,也是一个难以很好地实施的选择。 RabbitMQ 更倾向于答案 3:限制发布者速率,并尽可能平衡发布和消费速率。
这归结为流量控制。
选择正确的飞行中限制和预取
如果你从不期望高负载,那么决策很简单。 我们在上一篇文章中看到,对于单个高吞吐量队列,你可以设置高飞行中限制、高预取,并可选择将多重标志与消费者确认结合使用,你会做得不错。 如果你的负载较低,那么所有设置对最终吞吐量和延迟数字的影响可能都相同。
但是,如果你预计会出现高负载时期,并且有数百甚至数千个客户端,那么这仍然是一个好的选择吗? 我知道回答这些问题的最好方法是运行测试,许多许多带有各种参数的测试。
因此,我们将运行一系列基准测试,使用不同的
- 发布者数量
- 队列数量
- 消费者数量
- 发布速率
- 飞行中限制
- 预取和确认间隔
我们将测量吞吐量和延迟。 飞行中限制将是每个发布者目标速率的百分比,百分比范围在 1% 到 200% 之间。 因此,例如,对于每个发布者的目标速率为 1000
- 1% 飞行中限制 = 10
- 5% 飞行中限制 = 50
- 10% 飞行中限制 = 100
- 20% 飞行中限制 = 200
- 100% 飞行中限制 = 1000
- 200% 飞行中限制 = 2000
与上一篇文章一样,我们将测试镜像队列和仲裁队列。 镜像队列使用一个 master 和一个镜像 (复制因子 2),仲裁队列使用一个 leader 和两个 follower (复制因子 3)。
所有测试都使用 RabbitMQ 3.8.4 的 alpha 版本,其中改进了仲裁队列内部机制,以处理高负载。 此外,我们将保守地使用内存,并将仲裁队列的 x-max-in-memory-length 属性设置为较低的值,这使得仲裁队列的行为有点像惰性队列,它会在安全的情况下尽快从内存中删除消息体,并且队列长度已达到此限制。 如果没有此限制,仲裁队列会将所有消息保存在内存中。 如果消费者跟不上,性能可能会降低,因为磁盘读取次数会更多,但这是一个更安全、更保守的配置。 当我们对系统进行压力测试时,这将变得很重要,因为它避免了大的内存峰值。 在这些测试中,它被设置为 0,这是最激进的设置。
所有测试都在 3 节点集群上进行,集群使用 16 个 vCPU(Cascade Lake/Skylake Xeon)机器和 SSD。
基准测试
- 20 个发布者,1000 msg/s,10 个队列,20 个消费者,1kb 消息
- 20 个发布者,2000 msg/s,10 个队列,20 个消费者,1kb 消息
- 500 个发布者,30 msg/s,100 个队列,500 个消费者,1kb 消息
- 500 个发布者,60 msg/s,100 个队列,500 个消费者,1kb 消息
- 1000 个发布者,100 msg/s,200 个队列,1000 个消费者,1kb 消息
基准测试 #1:20 个发布者,每个发布者 1000 msg/s,10 个队列,20 个消费者
总目标速率为 20000 msg/s,这在所选硬件上,对于此客户端和队列数量的集群总吞吐量限制之内。 这种负载对于此集群是可持续的。
我们有两个测试
- 没有发布者确认
- 确认,飞行中限制为目标发送速率的百分比:1% (10)、2% (20)、5% (50)、10% (100)、20% (200)、100% (1000)。
没有确认的镜像队列
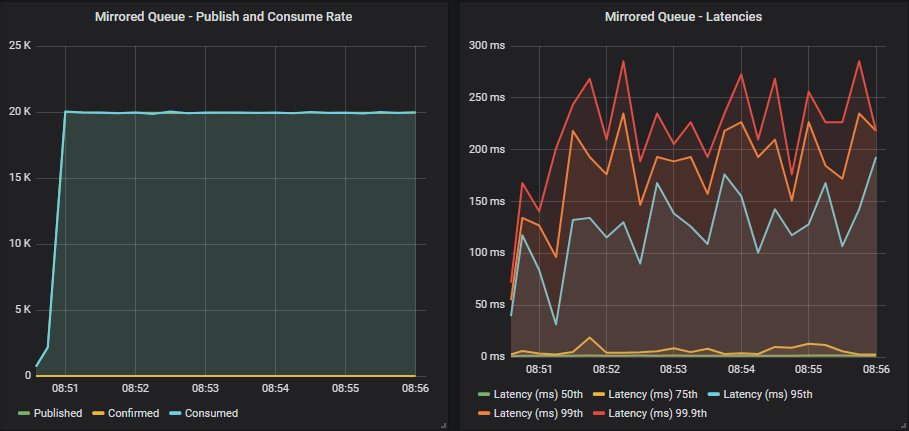
集群没有被发布者驱动得超出其处理能力。 我们获得了平稳的吞吐量,与我们的目标速率相匹配,延迟低于 1 秒。
带有确认的镜像队列
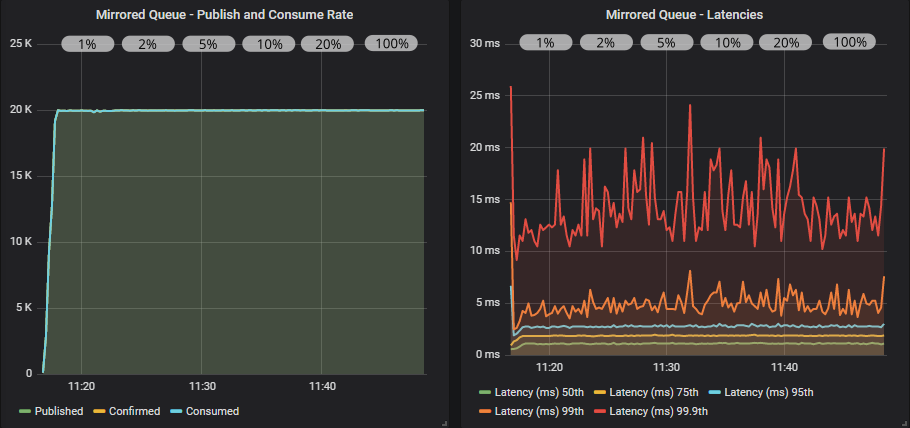
在此负载级别下,所有飞行中设置的行为都相同。 我们离 broker 的限制还很远。
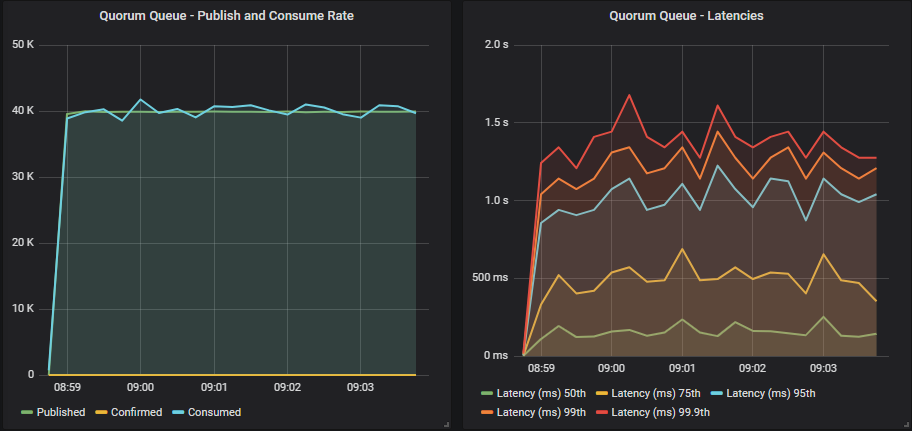
没有确认的仲裁队列
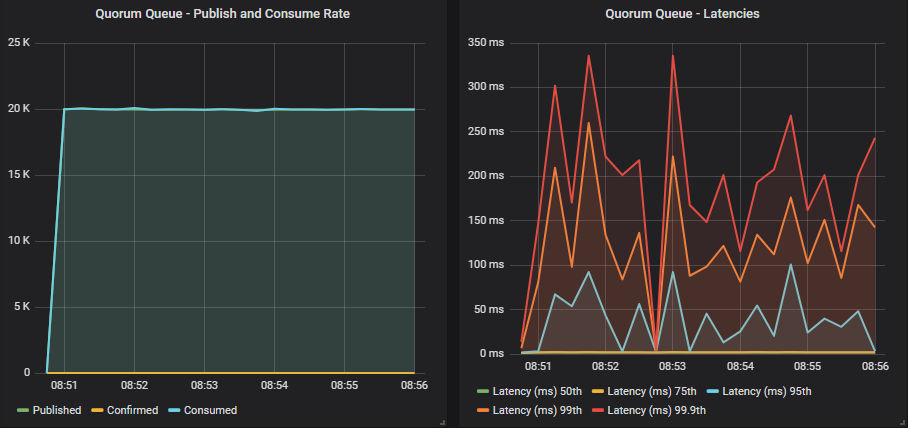
目标速率匹配,延迟低于 1 秒。
带有确认的仲裁队列
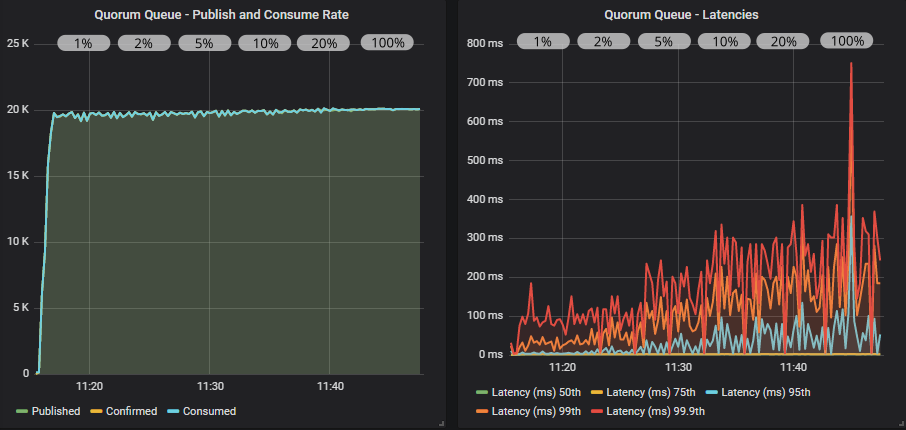
使用确认和较低的飞行中限制,仲裁队列略低于目标速率,但在所有百分位上都实现了 < 200 毫秒。 随着我们增加飞行中限制,达到了目标速率,线条平滑,但延迟增加,但仍低于 1 秒。
结论
当发布速率在集群向消费者交付的能力范围内时,具有较低飞行中限制的确认提供了最佳的端到端延迟,而没有确认或具有较高飞行中限制的确认交付了目标吞吐量,但延迟较高(但仍低于 1 秒)。
基准测试 #2:20 个发布者,每个发布者 2000 msg/s,10 个队列,20 个消费者
总目标速率为 40000 msg/s,这大约或高于所选硬件上集群的吞吐量限制。 这种负载对于此集群可能是不可持续的,但可能在峰值负载条件下发生。 如果持续存在,则建议使用更大的硬件。
我们有三个测试
- 没有发布者确认
- 确认,飞行中限制为目标发送速率的百分比:1% (20)、2% (40)、5% (100)、10% (200)、20% (400)、100% (2000)。 预取为 2000,确认间隔为 1。
- 与 2 相同,但消费者使用多重标志,确认间隔为 200(预取的 10%)。
没有确认的镜像队列
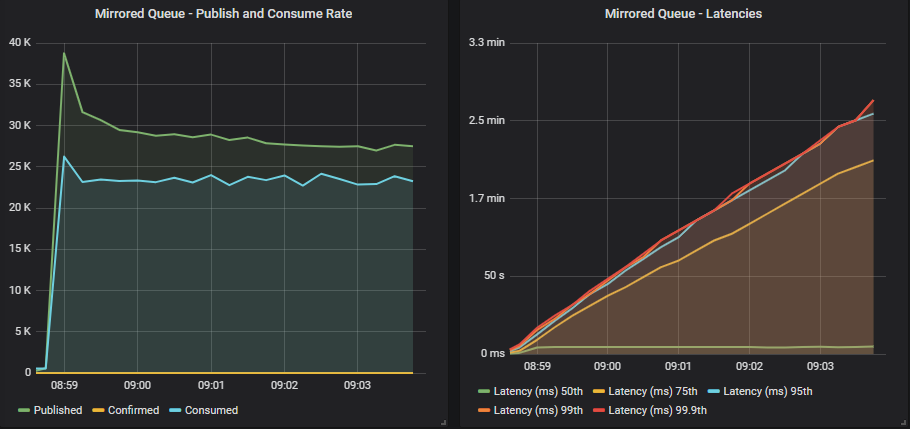
发布者短暂地接近目标速率,但发布者和消费者的速率都稳定在较低的速率,发布速率超过了消费速率。 这导致队列填满,延迟飙升。 如果这种情况持续下去,队列将变得巨大,并对资源使用造成越来越大的压力。
带有确认的镜像队列
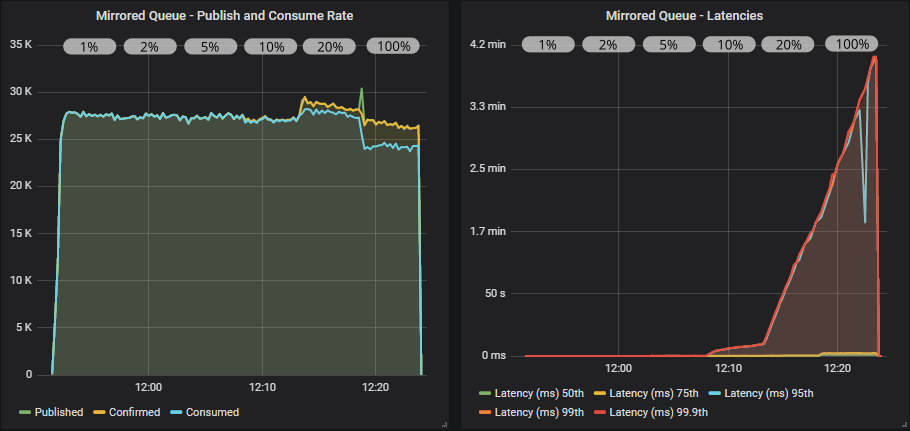
带有确认和多重标志使用的镜像队列
确认现在确实发挥了作用,对发布者施加了有效的反压。 我们在最低的飞行中限制 20(目标速率的 1%)下达到了峰值吞吐量(仍然远低于目标)。 端到端延迟很低,约为 20 毫秒。 但是,随着我们增加飞行中限制,少数队列开始填满,导致第 95 百分位延迟飙升。
我们看到,当处于高飞行中限制时,使用多重标志减少了发布到消费速率的不平衡,从而稍微降低了最糟糕的延迟。 但在这种情况下,效果不是很强。
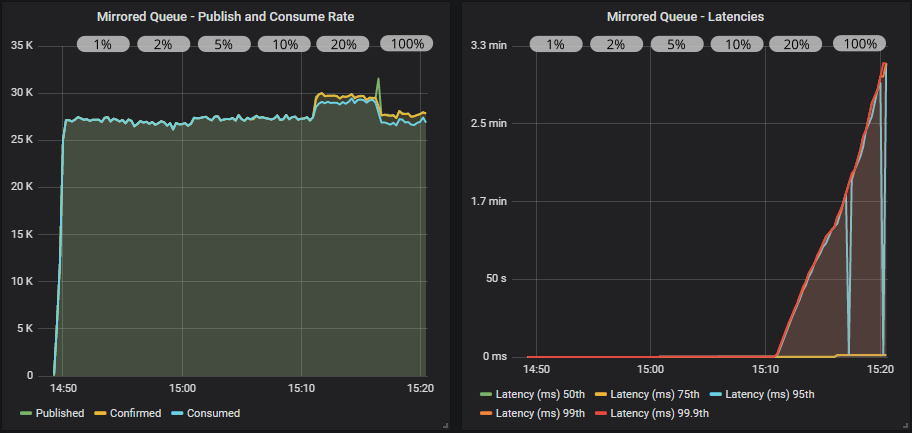
没有确认的仲裁队列
当队列计数较低时,仲裁队列往往优于镜像队列。 在这里,我们看到达到了 40000 msg/s,因此不需要对发布者施加反压。
带有确认的仲裁队列
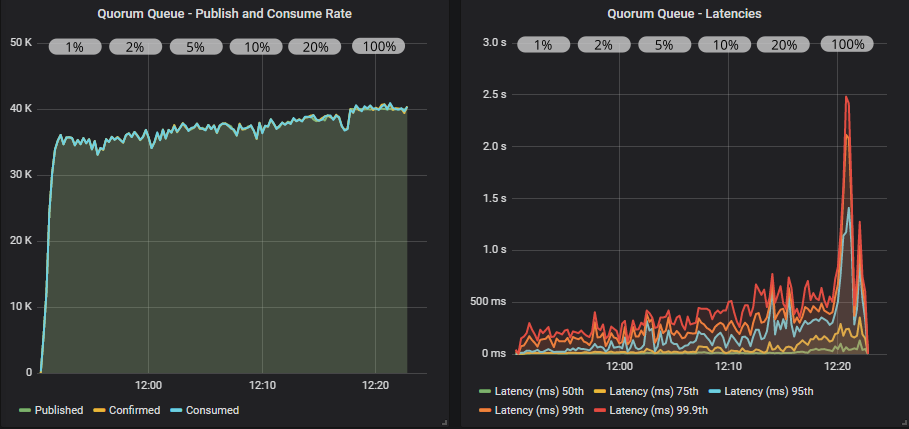
带有确认和多重标志使用的仲裁队列
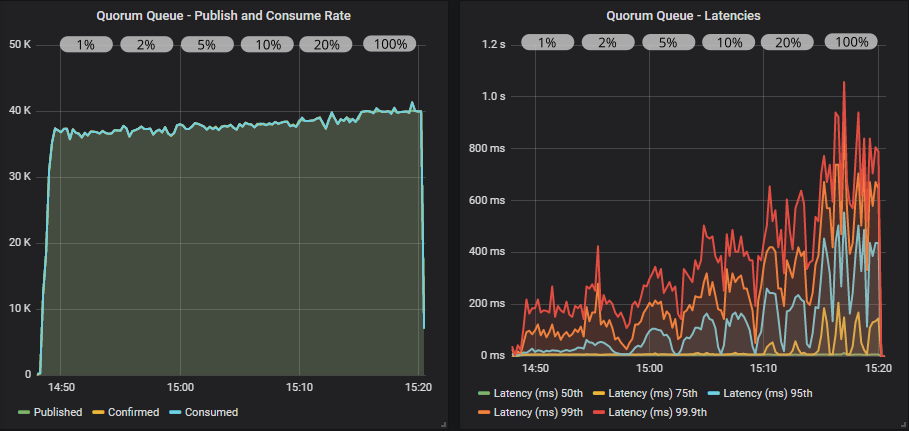
仲裁队列再次提供更高的吞吐量,我们甚至在飞行中限制为 2000 的情况下达到了 40000 msg/s 的目标速率。 使用多重标志有轻微的好处。
结论
在没有使用发布者确认和飞行中限制的反压的情况下,镜像队列崩溃了。 当发布者使用确认时,他们有效地对发布者施加了反压,在飞行中限制达到目标速率的 100% 之前实现了低延迟,之后延迟再次开始飙升。 需要注意的重要一点是,此目标速率超过了镜像队列的容量,我们看到了反压的重要性。
当队列和发布者的数量相对较低时,仲裁队列可以实现比镜像队列更高的吞吐量。 它们能够交付 40000 msg/s,因此使用确认或不使用确认对于稳定的性能并不关键。
多重标志的使用是有益的,但不是颠覆性的。
基准测试 #3:500 个发布者,每个发布者 30 msg/s,100 个队列,500 个消费者
总目标速率为 15000 msg/s,这在所选硬件上集群的总吞吐量限制之内。
我们有两个测试
- 没有发布者确认
- 确认,飞行中限制为目标发送速率的百分比:6% (2)、10% (3)、20% (6)、50% 12、100% (30)、200% (60),并且不使用多重标志。
没有确认的镜像队列
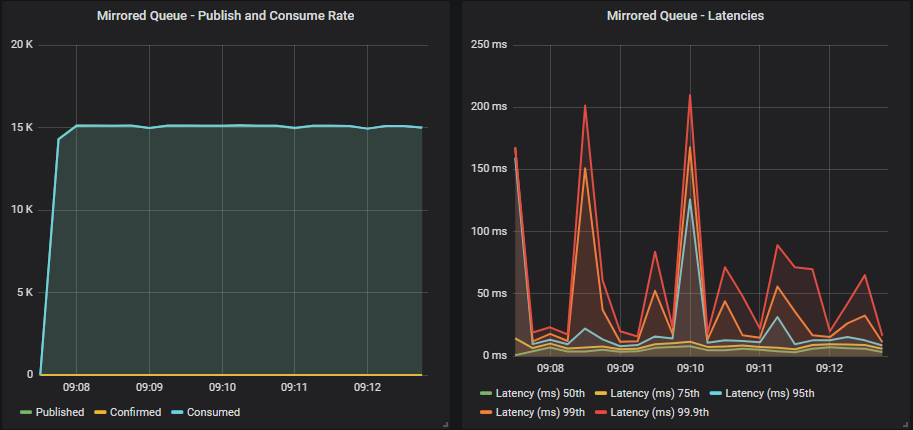
带有确认的镜像队列
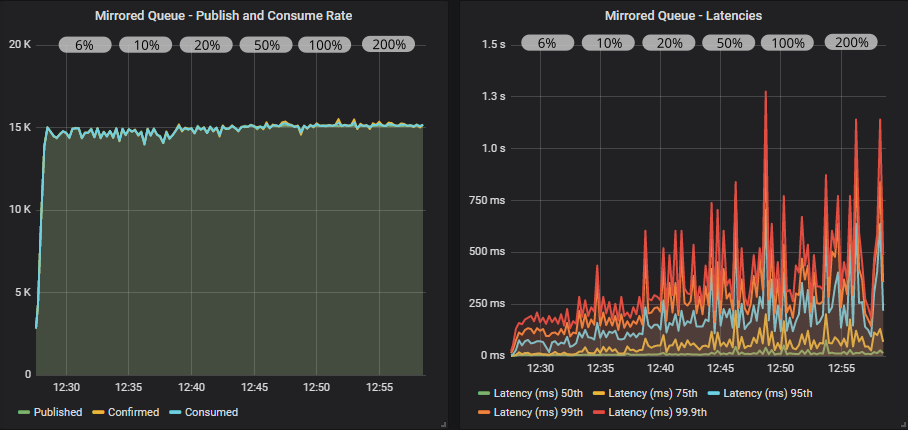
没有确认的仲裁队列
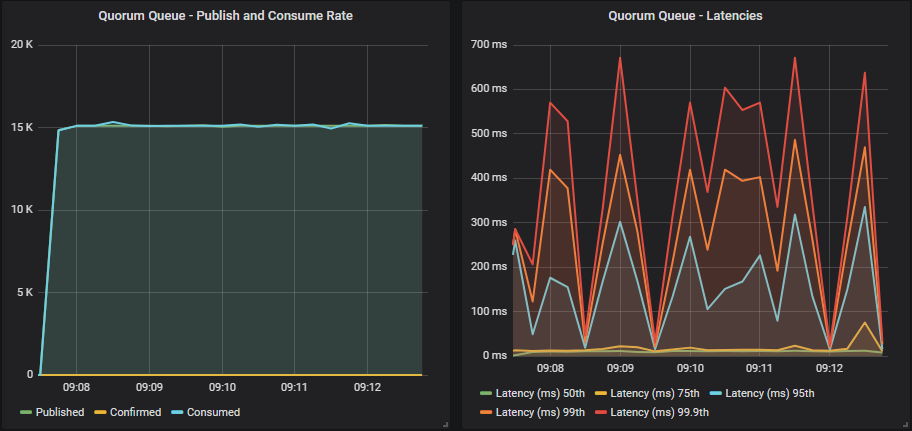
带有确认的仲裁队列
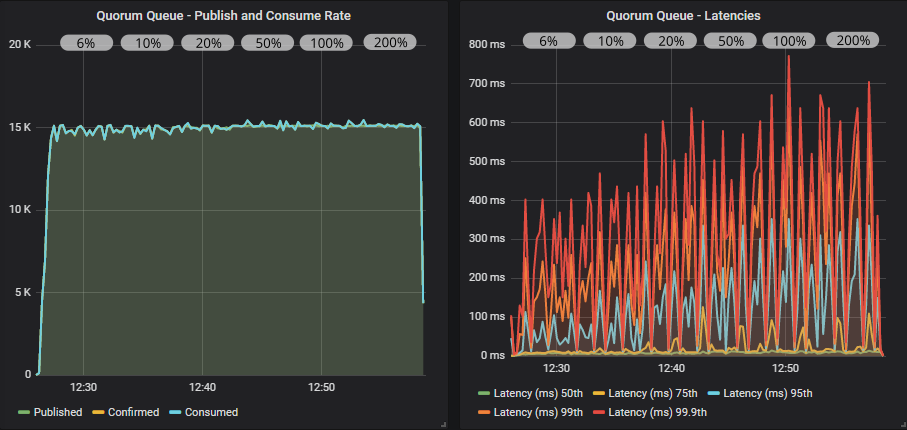
在所有情况下,我们都达到了目标速率。 使用确认和较低的飞行中限制,吞吐量有少量抖动,但在更高的限制下得到解决。
随着我们增加飞行中限制,延迟逐渐增加。 镜像队列超过 1 秒,而仲裁队列保持在 1 秒以下。
同样,我们看到,当集群在其容量范围内时,我们不需要将确认作为反压机制(仅用于数据安全)。
基准测试 #4:500 个发布者,每个发布者 60 msg/s,100 个队列,500 个消费者
总目标速率为 30000 msg/s,这略高于此客户端和队列数量(在所选硬件上)的集群总吞吐量限制。 这将对集群造成压力,并且不是此集群应该承受的可持续负载。
我们有三个测试
- 没有发布者确认
- 确认,飞行中限制为目标发送速率的百分比:5% (3)、10% (6)、20% (12)、50% (24)、100% (60)、200% (120),预取为 60。
- 与 2 相同,但使用多重标志,确认间隔为 6(预取的 10%)。
没有确认的镜像队列
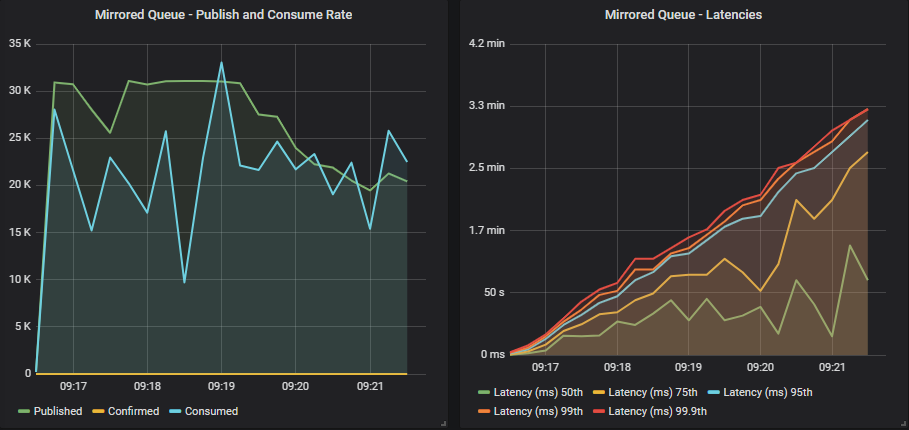
在没有确认的情况下,发布者短暂地管理目标速率,但消费者无法跟上。 吞吐量非常不稳定,一半队列的延迟接近 1 分钟,其余队列的延迟超过 2-3 分钟。
带有确认的镜像队列
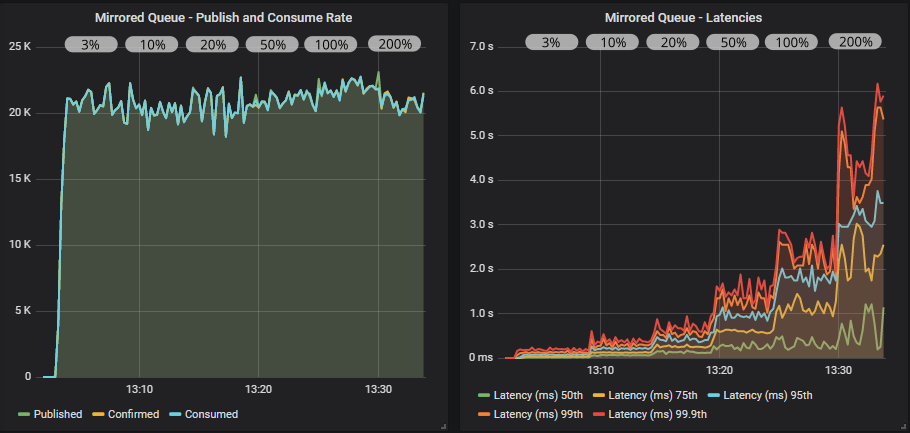
带有确认和多重标志使用的镜像队列
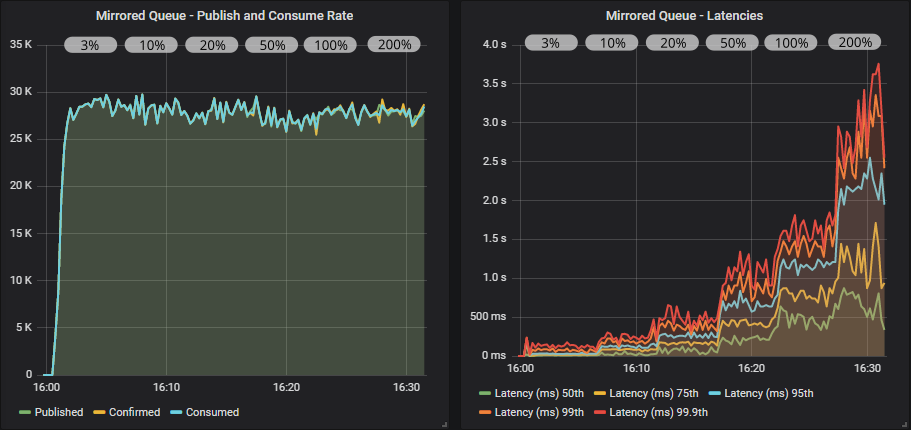
使用确认,我们获得了更稳定的吞吐量,消费者可以跟上发布速率,因为发布者受到其飞行中限制的速率限制。 多重标志这次肯定有帮助,使我们的吞吐量提高了 5000 msg/s。 请注意,仅为目标速率 3% 的飞行中限制可提供最佳性能。
没有确认的仲裁队列
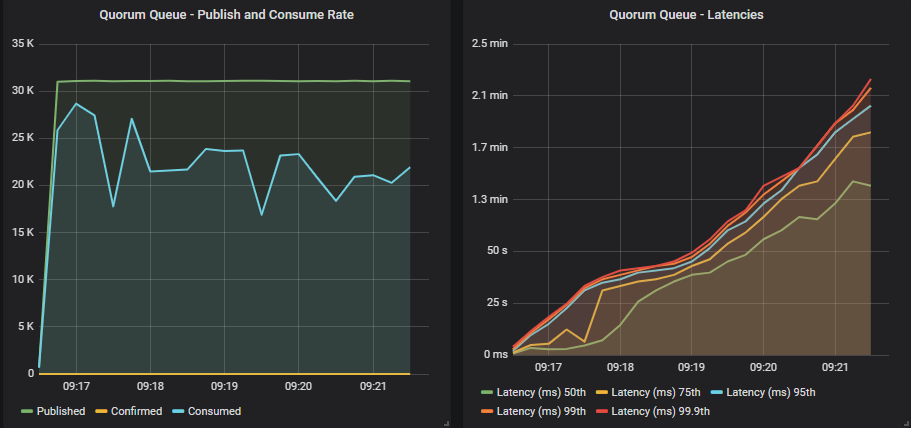
发布者达到了他们的目标,但消费者没有跟上,队列正在填满。 这不是一个可持续的状态。
带有确认的仲裁队列
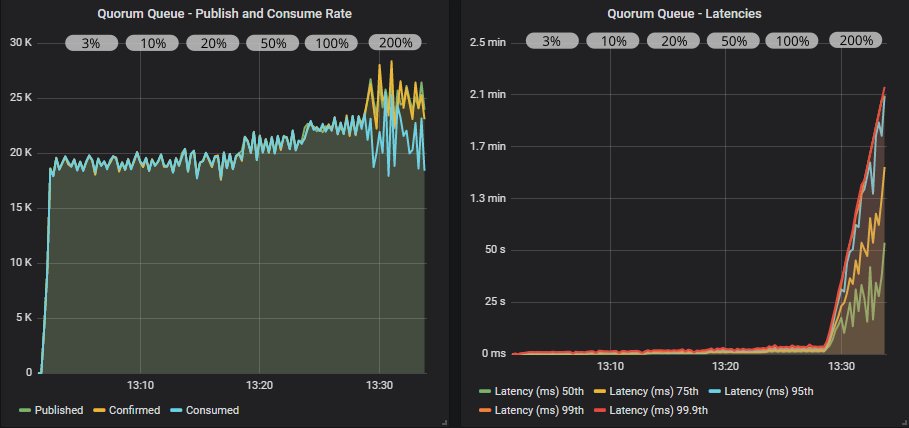
带有确认和多重标志的仲裁队列
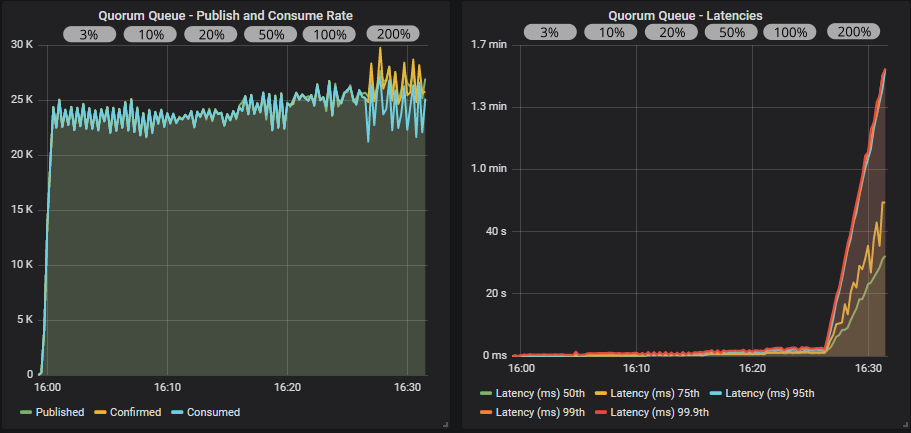
使用发布者确认,我们看到了更稳定的吞吐量,但肯定存在锯齿模式。 我们可以一直将飞行中限制提高到目标速率的 100%,而不会崩溃,尽管延迟稳步上升。 在 200% 时,发布速率超过了消费速率,队列开始填满。
结论
当集群超出其限制时,使用带有飞行中限制的发布者确认可确保平衡的发布和消费速率。 即使发布者会更快,他们也会自我限制速率,RabbitMQ 可以长时间提供可持续的性能。
对于大量的发布者、消费者和队列,镜像队列和仲裁队列的最大吞吐量已收敛到相似的数字。 仲裁队列不再优于镜像队列。 我们在客户端和队列较少的情况下看到了更高的吞吐量。 较少意味着更少的上下文切换,更少的随机 IO,所有这些都更有效。
基准测试 #5:1000 个发布者,每个发布者 100 msg/s,200 个队列,1000 个消费者
这种负载远远超出了此集群在 200 个队列上以每秒 100000 msg/s 的总目标速率可以处理的范围。 超过低 10 个队列后,预计集群的最大吞吐量会随着队列数量的增加而下降。
如果此集群曾经受到如此冲击,那么它应该只是在短时间内。
我们有三个测试
- 没有确认
- 确认,飞行中限制为目标发送速率的百分比:2% (2)、5% (5)、10% (10)、20% (20)、50% (50)、100% (100),预取为 100。
- 与 2 相同,但使用多重标志,确认间隔为 10(预取的 10%)。
没有确认的镜像队列
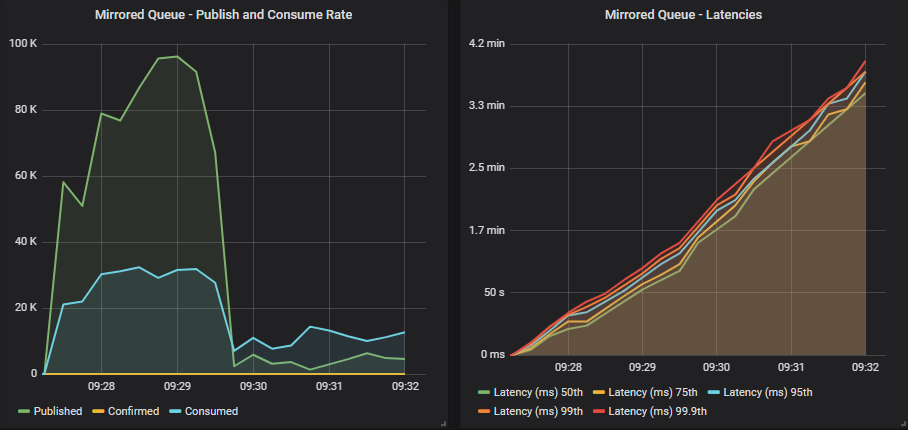
发布者几乎达到目标速率,但随后 broker 内部的缓冲区开始达到容量,吞吐量像石头一样骤降。 依靠 TCP 反压,使用默认的基于信用的流量控制设置,1000 个发布者发送速度快于集群的处理能力,结果不太好。
信用链中每个 actor 的初始信用为 400,因此每个连接上的读取器进程至少会接受 400 条消息,然后才会被阻止。 对于 1000 个发布者,仅在读取器进程中就缓冲了 400,000 条消息。 加上通道和队列的缓冲区,以及所有传出端口缓冲区等等,你可以看到 broker 如何吸收然后被大量发布者的大量消息阻塞,甚至在 TCP 反压开始生效之前。
带有确认的镜像队列
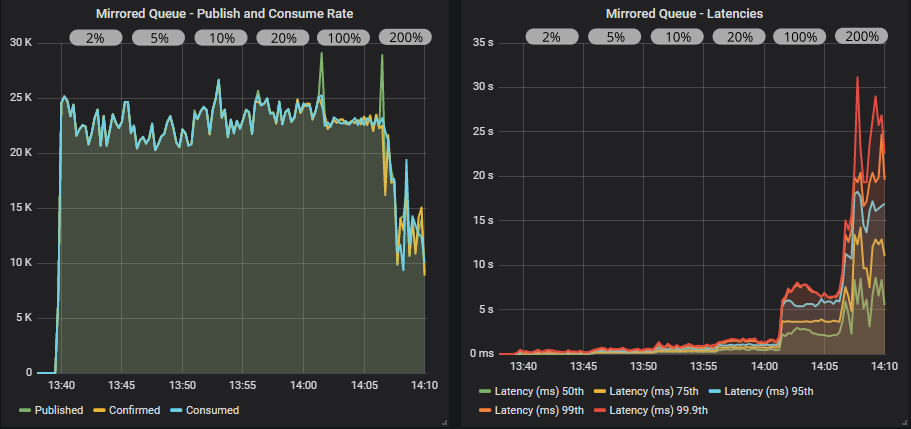
带有确认和多重标志使用的镜像队列
发布者很想达到目标速率,但他们受到了有效的速率限制。 随着我们增加飞行中限制,我们看到吞吐量略有增加,延迟增加幅度更大。 最后,当我们达到目标速率 200% 的飞行中限制时,这太多了,但发布者仍然受到限制。 队列稍微积压,吞吐量下降,变得非常不稳定。 多重标志的使用有所帮助,它减少了下降,并将延迟保持在 25 秒以下。
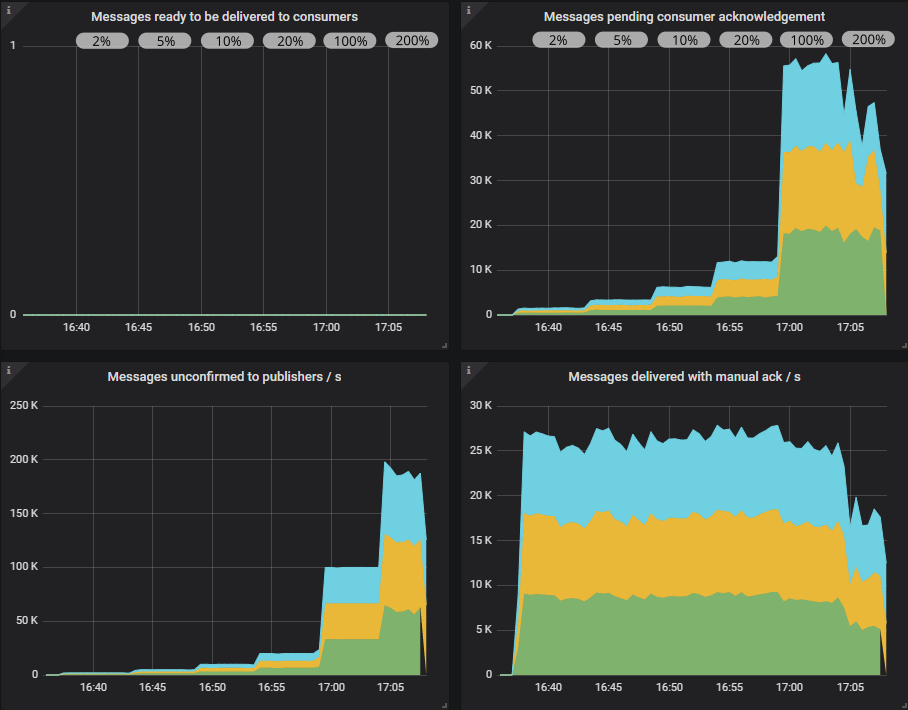
如果我们查看 RabbitMQ 概览 Grafana 仪表板(为了在此处显示而略作修改),我们看到,当飞行中限制较低时,待处理的确认和待处理的消费者 ack 的数量较少,但是当我们达到 100% 的飞行中限制时,这些数字达到 100,000。 因此,RabbitMQ 在内部缓冲了更多的消息。 消费者尚未达到其预取限制,但峰值达到其总可能 100,000 的 55,000。
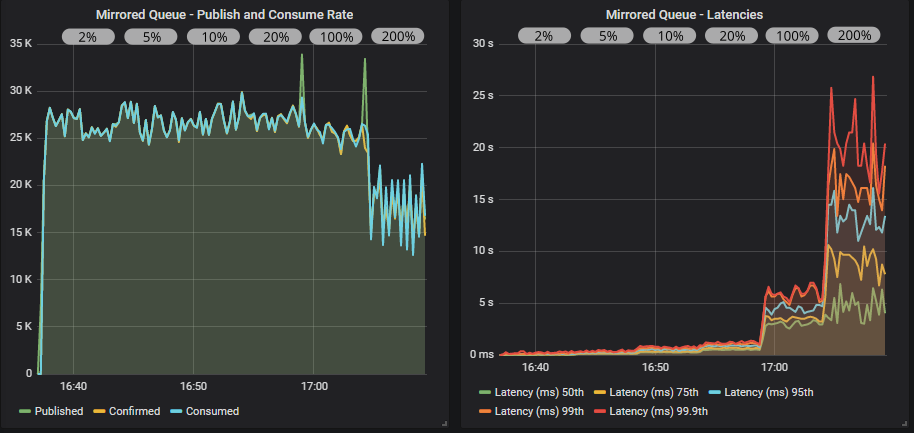
没有确认的仲裁队列
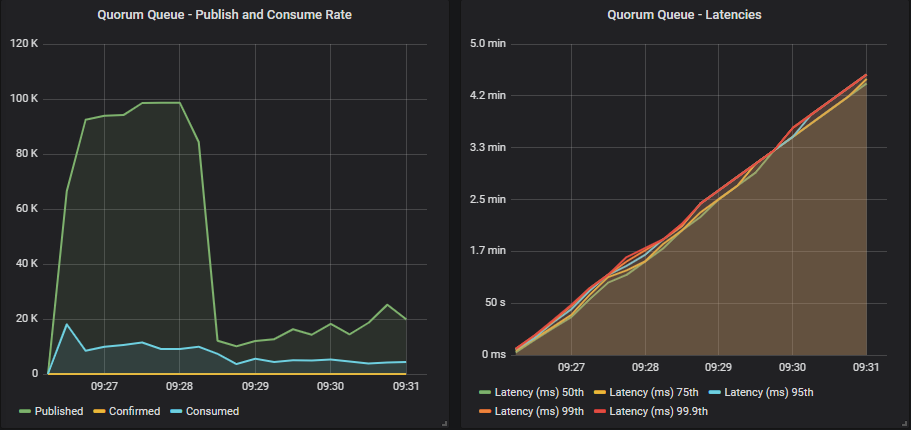
与镜像队列相同。 TCP 反压不足以阻止过载。
带有确认的仲裁队列
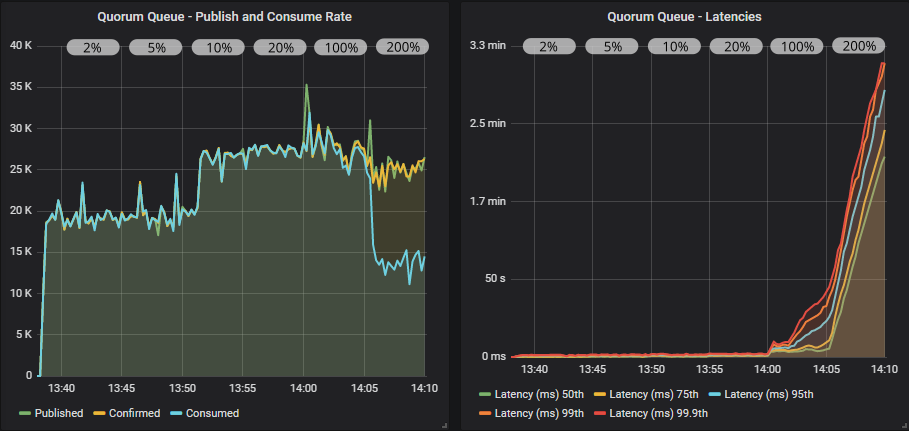
带有确认和多重标志使用的仲裁队列
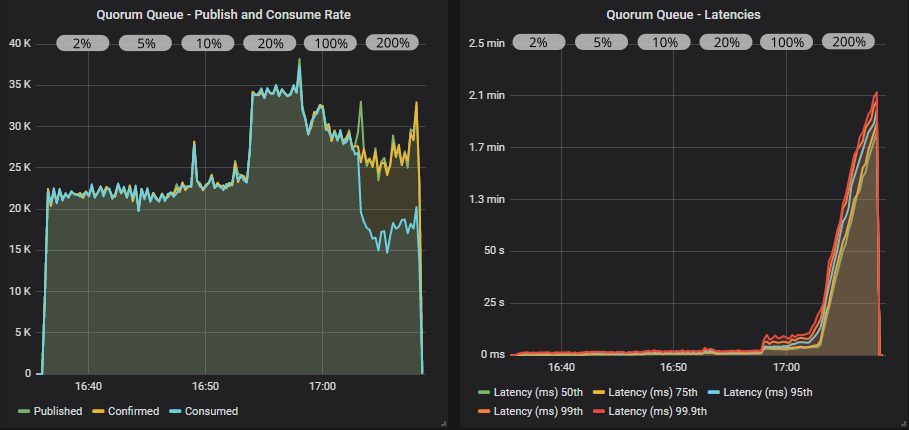
当从低飞行中限制切换到中等大小的飞行中限制时,仲裁队列的受益程度明显高于镜像队列。 使用多重标志,我们甚至达到了接近 35000 msg/s。 当达到目标速率限制的 100% 时,情况开始变糟,然后在 200% 时变得非常糟糕。 发布者领先,导致队列填满。 这时,你真的需要为 x-max-in-memory-length 仲裁队列属性设置低值。 如果没有它,在这些条件下,内存使用量会快速飙升,导致吞吐量大幅波动,因为内存警报会反复打开和关闭。
我们在即将发布的 3.8.4 版本中对压力下的仲裁队列内存使用量进行了重大改进。 所有这些测试都显示了这项工作的成果。 在本文的末尾,我们将展示使用 3.8.3 的相同测试,以及它如何不能很好地处理此压力测试。
在概览仪表板中,我们看到队列是如何填满的。 消费者已达到其预取限制。
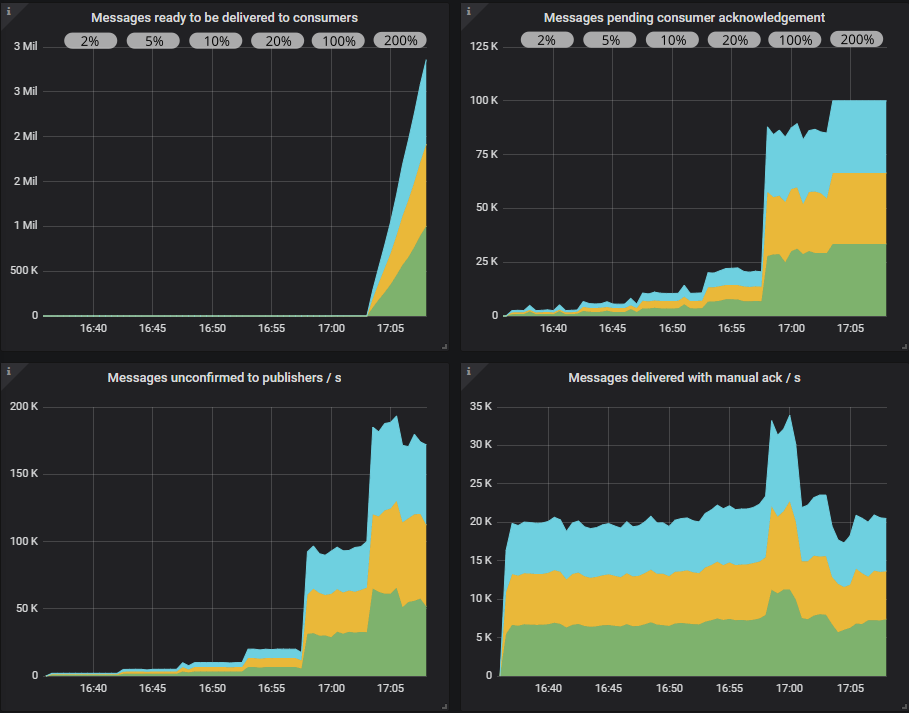
结论
在没有发布者确认的情况下,两种队列类型都无法处理此负载。 每个集群都完全不堪重负。
使用确认,镜像队列和仲裁队列在 100% 和 200% 飞行中限制之前实现了相同的 ballpark 吞吐量和延迟数字,在 100% 和 200% 飞行中限制下,仲裁队列的表现更差。
镜像队列很好地处理了过载,即使在较高的飞行中限制下也是如此。 仲裁队列需要较低的飞行中限制的额外帮助才能实现稳定的吞吐量和低延迟。
3.8.3 及更早版本呢?
所有仲裁队列测试都在 3.8.4 的 alpha 版本上运行,以便展示即将发布的 3.8.4 版本的性能。 但你们中的其他人将使用 3.8.3 及更早版本。 那么你能期待什么呢?
3.8.4 中包含的改进是
- 段写入的高吞吐量能力。 消息首先写入 WAL,然后写入段文件。 在 3.8.3 中,我们看到段写入器在高负载、高队列计数场景中是一个瓶颈,这会导致高内存使用率。 3.8.4 附带并行段写入,这完全解决了此瓶颈。
- 仲裁队列的默认配置值经过了负载测试,我们发现一些更改导致在高负载下吞吐量更稳定。 具体来说,我们将 quorum_commands_soft_limit 从 256 更改为 32,并将 raft.wal_max_batch_size 从 32768 更改为 4096。
如果你使用的是 3.8.3,好消息是现在可以轻松执行滚动升级,但如果你无法升级,请尝试上述配置。 但是,你仍然可能遇到段写入器的瓶颈。
下面是基准测试 #5,运行时间更长,使用 3.8.3(应用了配置更改)。
3.8.3 基准测试 #5
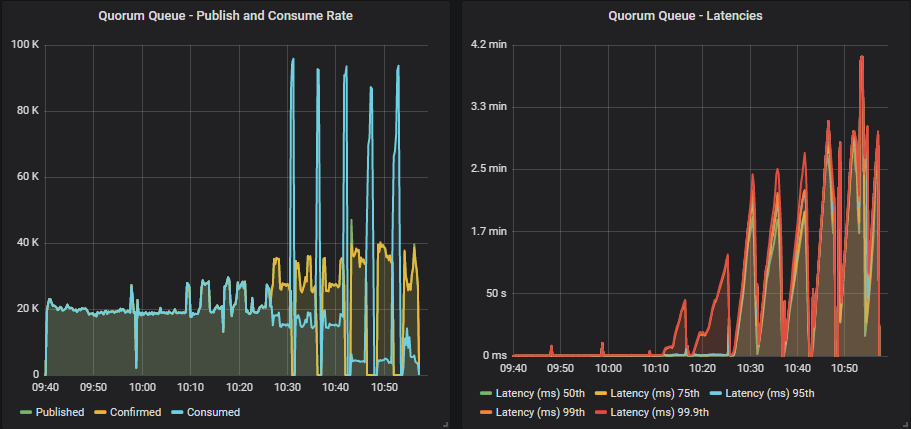
3.8.3 的主要区别在于,随着我们增加飞行中限制,段写入器落后,内存增长,直到达到内存警报。 发布者被阻止,然后消费者不受与发布者竞争将其 ack 放入复制日志的限制。 消费速率达到高达 90k msg/s 的短峰值,直到队列被耗尽,内存下降,警报被停用,然后再次重复。
我们可以从概览仪表板中看到这一点。 3.8.4 alpha 版本随着飞行中限制的增加,内存增长缓慢。
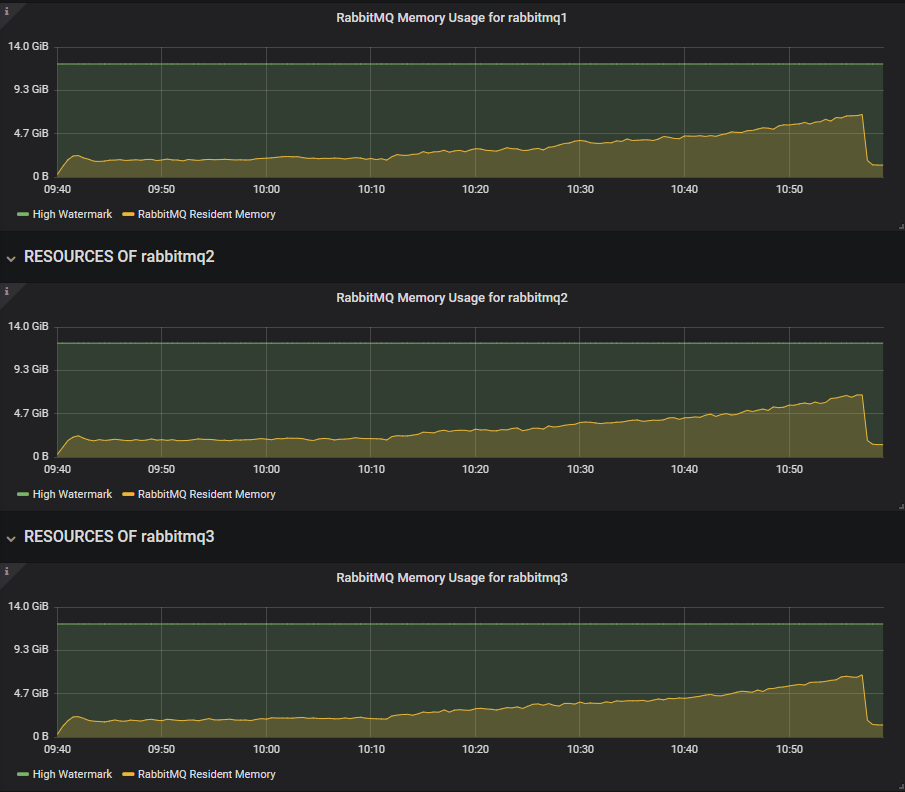
3.8.3 反复触发内存警报。
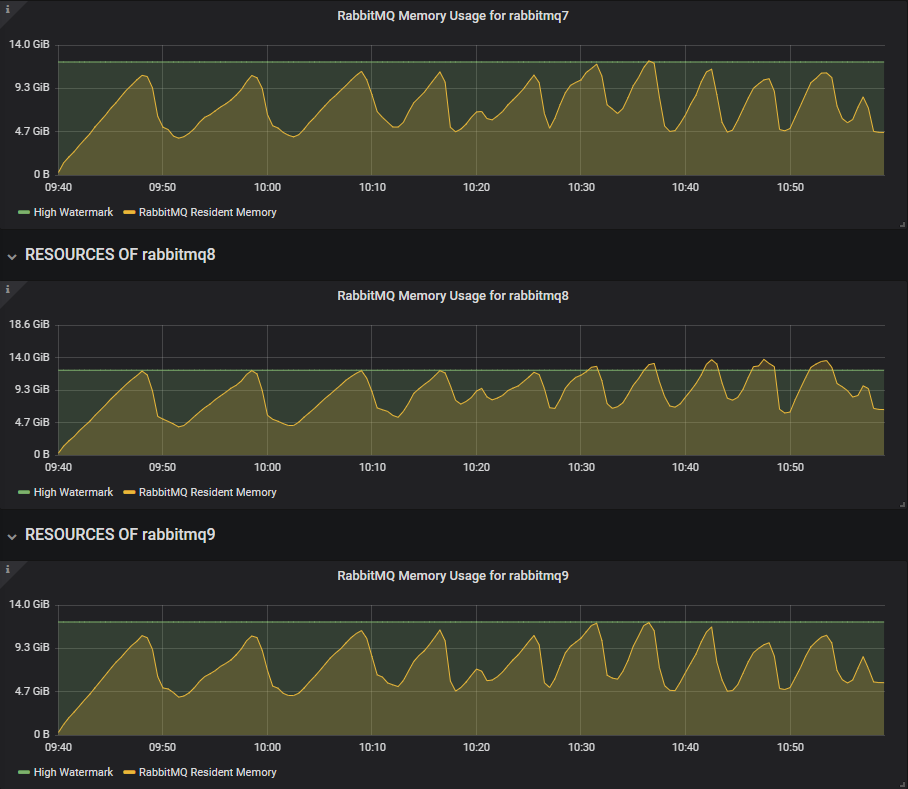
即使使用低飞行中限制,1000 个发布者的重负载对于段写入器来说也太多了,并且在测试早期就接近内存警报。
因此,如果你有大量的发布者和队列计数,并且负载定期达到峰值并超过其限制,请考虑在 3.8.4 发布时升级到 3.8.4。
最终结论
首先,如果您正在使用复制队列(镜像或仲裁),那么从数据安全的角度来看,不使用发布者确认是非常不明智的。消息传递无法得到保证,所以请使用它们。
除了数据安全之外,这些测试表明确认在流量控制中也起作用。
一些关键要点
- 当队列计数在每个核心 1-2 个左右的区域时,仲裁队列可以提供比镜像队列更高的吞吐量。
- 在低发布者和队列计数的情况下,您可以做任何事情。 TCP 反压可能足以满足镜像队列和仲裁队列的需求(不使用确认)。
- 在高发布者和队列计数以及更高负载的情况下,TCP 反压是不够的。我们必须使用发布者确认,以便发布者限制自己的速率。
- 在高发布者和队列计数的情况下,两种队列类型的性能或多或少相似。但是仲裁队列在压力测试期间需要通过降低飞行中限制来获得一些额外的帮助。
- 多标志的使用是有益的,但不是至关重要的。
- 无论你做什么,都不要在没有发布者确认的情况下让你的 Broker 承受高负载!
那么最佳的飞行中限制是多少? 我希望我已经说服您这取决于情况,但作为经验法则,在发布者和 Broker 之间的网络延迟较低的情况下,使用目标速率的 1% 到 10% 之间的限制是最佳的。 对于发送速率高的较少发布者,我们倾向于 10%,但对于数百个客户端,我们倾向于 1% 的标记。 这些数字可能会随着发布者和 Broker 之间更高的延迟链接而增加。
关于消费者预取,所有这些测试都使用了目标发布速率(每个发布者,而不是总数)的预取,但请记住,在这些测试中,发布者的数量与消费者的数量相匹配。 当使用多标志时,ack 间隔是预取值的 10%。 多标志的使用是有益的,但如果您不使用它也没什么大不了的。
如果您当前正在使用镜像队列,并且您的工作负载更接近基准测试 #5 而不是其他任何一个,那么建议在 3.8.4 发布后进行迁移。 改进负载下的流量控制和弹性可能是一项持续的努力,但在许多情况下也是特定于工作负载的。 希望您已经看到,您可以利用确认来调整吞吐量和延迟,并获得您需要的行为。
如果我不提及容量规划,那将是我的疏忽。 确保 RabbitMQ 有足够的硬件来处理峰值负载是确保它可以提供可接受性能的最佳方法。 但总会有意外的负载、预算限制等等。
请记住,与所有此类基准测试一样,不要只关注这些特定数字。 你的情况会有所不同。 不同的硬件、不同的消息大小、不同程度的扇出、不同版本的 RabbitMQ、不同的客户端、框架......等等。 最主要的 takeaway 是,当在高负载下时,你不应该期望 RabbitMQ 自己施加流量控制。 这完全是关于机械共情。
本系列的下一篇将着眼于从镜像队列迁移到仲裁队列。