了解 RabbitMQ 3.4 中的内存使用情况
“我的队列使用了多少内存?”这是一个很容易提出的问题,但回答起来却有些复杂。RabbitMQ 3.4 让您更清楚地了解队列如何使用内存。这篇博文讨论了这个问题,并解释了队列内存使用的一般情况。
背景介绍
首先,我们需要了解 Erlang 如何管理内存。Erlang 与大多数垃圾回收语言不同,它没有全局堆。相反,每个进程都有一个私有的独立堆。在 RabbitMQ 的术语中,进程可能指的是队列、通道、连接等。这意味着,每次垃圾回收发生时,整个系统不必停止;相反,每个进程都会在自己的时间表中进行垃圾回收。
这很好,但当消息在 RabbitMQ 中传递时,它会经过几个不同的进程。我们希望避免在消息传递过程中进行过多的复制。因此,Erlang 为二进制数据提供了一种不同的内存管理机制,二进制数据在 RabbitMQ 中用于多种用途,其中最重要的是消息体。二进制数据是在进程之间共享的,并且是引用计数的(引用由进程持有,并随其他所有内容一起被垃圾回收)。
这如何应用于 RabbitMQ
这意味着消息体使用的内存是在 RabbitMQ 中的各个进程之间共享的。这种共享也发生在队列之间:如果一个交换机将一条消息路由到多个队列,消息体只会存储一次。
因此,我们可以看到,“这个队列使用了多少内存?”是一个很难回答的问题——我们可以排除队列可能引用的任何二进制内存,这会导致低估;或者包含它,这可能导致高估。
早期版本的 RabbitMQ 并没有很好地处理这种困境;它们将队列的“内存使用量”报告为进程内存的大小(即不包括任何引用的二进制数据),并在全局内存细分中显示一个整体的“二进制内存使用量”。无法进一步调查。
RabbitMQ 3.4 从宏观和微观两个方面为我们提供了更好的指导。首先,让我们从宏观角度看看内存使用情况。
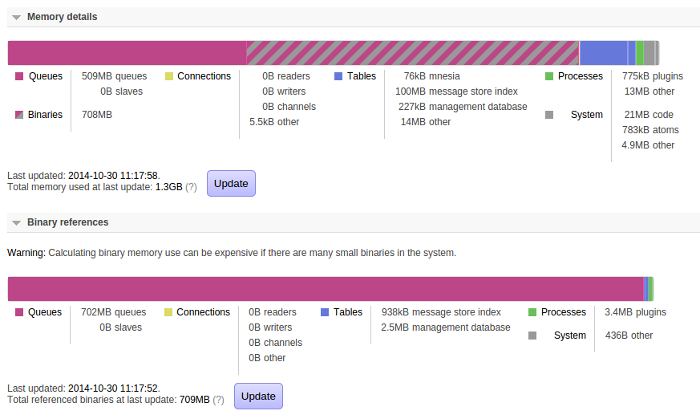
与我们过去拥有的相比,这里有几个不同之处。整体内存使用细分现在有更多的类别,并且有一个新的二进制内存“细分”。
我们将二进制内存细分分开显示有几个原因;一个原因是计算它可能非常昂贵(我们必须遍历服务器使用的所有内存;如果存在大量小的二进制数据,这可能需要一些时间),另一个原因是,我们不保证它会与总体内存细分中显示的大小相加(由于前面提到的二进制数据共享方式)。
但我们可以看到,几乎所有的二进制数据使用都是由于队列中的消息。此屏幕截图来自一个基本静态的代理,因此这是我们所期望的。
但是队列呢?
好的,那么哪些队列在使用所有这些内存呢?我们可以通过查看每个队列的详细信息页面来调查这一点(当然,这些信息也可以通过 rabbitmqctl 获取,但图片看起来更漂亮)。
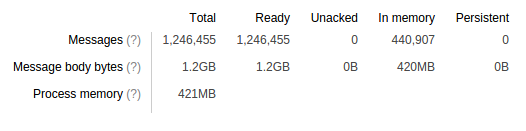
在这里,我们可以看到 RabbitMQ 3.4 的另一个新功能:队列维护着它包含的消息体字节总数的计数。因此,我们看到这个队列包含 1.2GB 的消息体内容,其中 420MB 在内存中。我们可以假设这 420MB 都包含在队列使用的二进制内存中。该队列还使用了 421MB 的进程内存(巧合的是,这 amounts to a very similar amount),这包括消息属性、头部以及每条消息的元数据。
因此,说“这个队列使用了 841MB 内存”是合理的——除非消息体也可能与其他队列共享。
顺便说一句,请注意,“内存中”和“持久化”消息在这里不是反义词:非持久化消息在内存压力下可能会被分页,而持久化消息也可能在内存中。有关分页的更多信息,请参阅文档。
我们也可以在队列列表视图中看到这些信息。
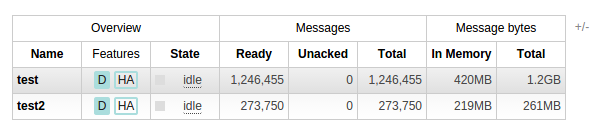
(在这里,我点击了“+/-”链接以添加列以显示内存使用情况,并删除了一些其他列以便更清晰。)
当然,这仍然不能完美地统计队列使用的内存量;在动态系统中,这样做可能是不可行的。但它让我们更接近真相。